
Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе.
Задержка публикации сообщений в Kafka
Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя Apache Kafka, я написала пару простых Python-приложений. Задержка – это разница между моментом происхождения события в реальном мире, материализованным в виде публикации сообщения продюсером и фактическим потреблением этих данных приложением-потребителем. На самом деле эта задержка складывается из двух компонентов:
- задержка публикации – разница между моментом происхождения события и его записью в топике Kafka;
- задержка потребления – разница между получением сообщения из Kafka и его фактической обработкой.
Чтобы сфокусироваться именно на этих временных показателях, логика публикации сообщений очень простая, без распределения сообщений по разделам топика Kafka. Приложение-продюсер отправляет в явно заданный раздел топика Kafka сообщение, которое содержит случайное название компании, сгенерированное с помощью метода fake.company() из библиотеки Faker. Для отслеживания времени происхождения события в реальном мире, т.е. когда продюсер его сгенерировал, используется переменная producer_publish_time, полученная из преобразования результата функции time.time(), которая возвращает текущее время в секундах, прошедших с начала эпохи Unix (1 января 1970 года 00:00:00 UTC). Это значение называется временной меткой (timestamp). Для наглядности в рамках цикла публикации присвоим каждому сообщению итерируемый порядковый номер. Таким образом, полезная нагрузка, упакованная в формате JSON, имеет следующую схему:
{
"$schema": "http://json-schema.org/draft-06/schema#",
"$ref": "#/definitions/Welcome4",
"definitions": {
"Welcome4": {
"type": "object",
"additionalProperties": false,
"properties": {
"number": {
"type": "integer"
},
"producer_publish_time": {
"type": "string"
},
"content": {
"type": "string"
}
},
"required": [
"number",
"content",
"producer_publish_time"
],
}
}
}
Код приложения-продюсера, который отправляет данные в 1-ый раздел топика Apache Kafka с названием test, запущенный в Google Colab, выглядит так:
####################################ячейка в Google Colab №1 - установка и импорт библиотек###########################################
#установка библиотек
!pip install kafka-python
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
# Импорт модуля faker
from faker import Faker
####################################ячейка в Google Colab №2 - публикация сообщений в Kafka###########################################
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic='test'
fake=Faker()
number=0
#бесконечный цикл публикации данных
while True:
start_time = time.time() # запоминаем время начала отправки сообщения
#подготовка данных для публикации в JSON-формате
producer_publish_time = time.strftime("%m/%d/%Y %H:%M:%S", time.localtime(start_time))
number=number+1
#задаем распределение по разделам
part=1
name=fake.company()
content = str('сообщение от ' + name)
#создаем полезную нагрузку в JSON
data = {'number': number, 'producer_publish_time': producer_publish_time,'content': content}
# публикуем данные в Kafka
future = producer.send(topic, value=data, partition=part, key=None)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Payload {data}')
end_time = time.time() # запоминаем время окончания отправки сообщения
package_size = len(json.dumps(data).encode('utf-8')) # размер пакета в байтах
delay = end_time - start_time # задержка в секундах
print(f'Размер пакета в байтах : {package_size}')
print(f'Задержка: {delay} секунд')
####################################ячейка в Google Colab №3 - закрытие соединения###########################################
#Закрываем соединения
producer.close()

Задержка публикации для пакета сообщений 150-170 байт составила около 0,02 секунды, кроме самого первого сообщения. Далее напишем код потребителя, чтобы понять задержку потребления.
Задержка потребления сообщений
Код потребителя тоже будет очень простым без сложных преобразований полученных данных. Для наглядности приложение-потребитель будет записывать потребленные сообщения в Google-таблицу, добавляя отметку времени приема сообщения в Kafka и текущее время, т.е. момент, когда фактически потребитель обрабатывает полученные данные. Текущее время вычисляется с помощью функции now(), которая возвращает текущую дату и время в формате объекта datetime. Python-код приложения-потребителя будет выглядеть так:
####################################ячейка в Google Colab №1 - установка и импорт библиотек###########################################
#установка библиотек
!pip install kafka-python
#импорт модулей
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
import json
import random
from datetime import datetime
from kafka import KafkaConsumer
from json import loads
from kafka.structs import TopicPartition
####################################ячейка в Google Colab №2 - потребление из Kafka###########################################
#объявление потребителя Kafka
consumer = KafkaConsumer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
group_id='gr1',
auto_offset_reset='earliest',
enable_auto_commit=True
)
topic='test'
#Google Sheets Autentificate
gc = gspread.authorize(creds)
# подписка потребителя на определенный раздел topic partition
part=1 #задание раздела
topic_partition = TopicPartition(topic, part) # указываем имя топика и номер раздела
consumer.assign([topic_partition]) #назначаем потребителя на этот топик и раздел
#Открытие заранее созданного файла Гугл-таблицы по идентификатору (взять из его URL, например, у меня это https://docs.google.com/spreadsheets/d/1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM)
sh = gc.open_by_key('1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM')
wks = sh.worksheet("test_"+ str(part)) #в какой лист гугл-таблиц будем записывать
#начальный номер строки для записи данных
x=1
# обработка сообщений из Kafka
for message in consumer:
try:
# распаковка сообщения
payload = message.value.decode("utf-8")
data = json.loads(payload)
# вывод сообщения в консоль
print(f"Offset: {message.offset}, Value: {message.value}")
print(consumer.position(topic_partition))
print(f"Timestamp: {message.timestamp}, Value: {message.value}")
timestamp = message.timestamp / 1000.0
datetime_object = datetime.fromtimestamp(timestamp)
formatted_timestamp = datetime_object.strftime('%Y-%m-%d %H:%M:%S.%f')
print(f"Timestamp: {formatted_timestamp}, Value: {message.value}")
# парсинг сообщения
number = data['number']
producer_publish_time = data['producer_publish_time']
content = data['content']
now=datetime.now()
consuming_time=now.strftime("%m/%d/%Y %H:%M:%S")
# вывод распарсенных данных в консоль
print(f'Сообщение № {number}, время публикации: {producer_publish_time}, Kafka timestamp {formatted_timestamp}, сейчас: {consuming_time}, содержимое: {content}')
# обновление данных в Google Sheets
x += 1
wks.update_cell(x, 1, number)
wks.update_cell(x, 2, producer_publish_time)
wks.update_cell(x, 3, formatted_timestamp)
wks.update_cell(x, 4, consuming_time)
wks.update_cell(x, 5, content)
except Exception as e:
# запись ошибок в лог-файл на Google Диске
error_str = f"Error: {str(e)}, Offset: {message.offset}, Value: {message.value}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Error: {str(e)}")
###################################ячейка в Google Colab №3 - закрытие соединения###########################################
#отписываем потребителя и закрываем соединение
consumer.unsubscribe()
consumer.close()
Чтобы избежать сбоя потребителя из-за изменения схемы данных полезной нагрузки, цикл потребления сообщений включает конструкцию try-except. При возникновении ошибки парсинга, т.е. исключения сообщение с измененной схемой записывается в лог-файл на Google Диске. Посмотрим вывод отладочной информации в консоли после запуска этого скрипта в Google Colab:
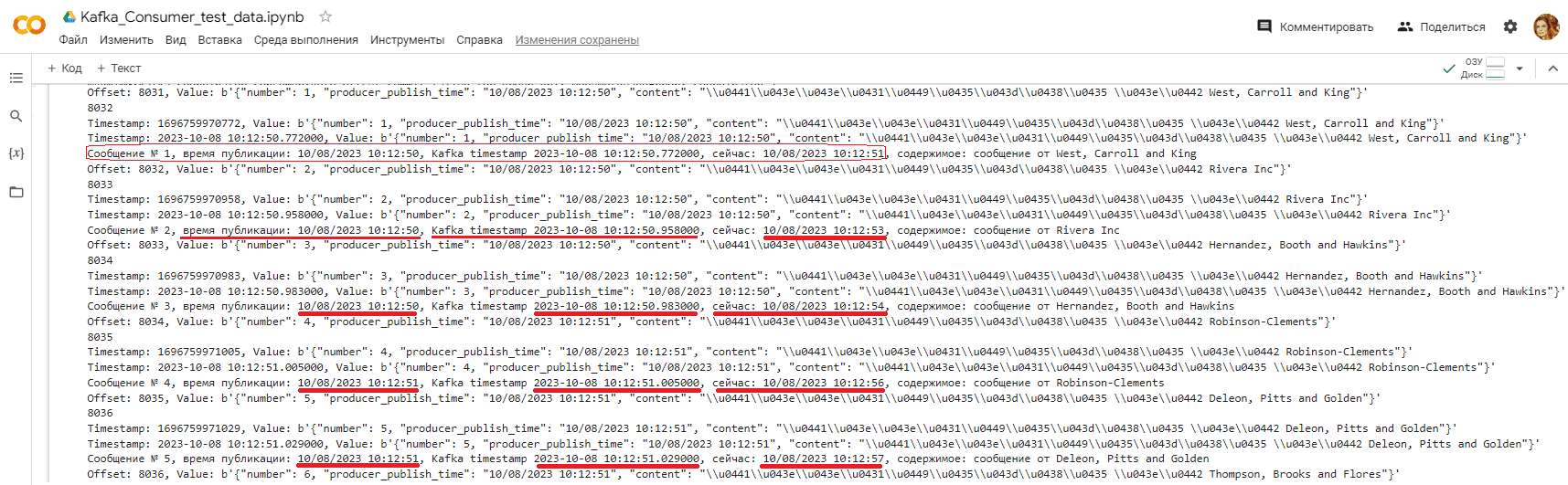
Таким образом, видно, что потребитель уже с первых сообщений начинает отставать от продюсера. Наиболее наглядно этот вывод подтверждает визуализация результатов потребления в Google-таблице:
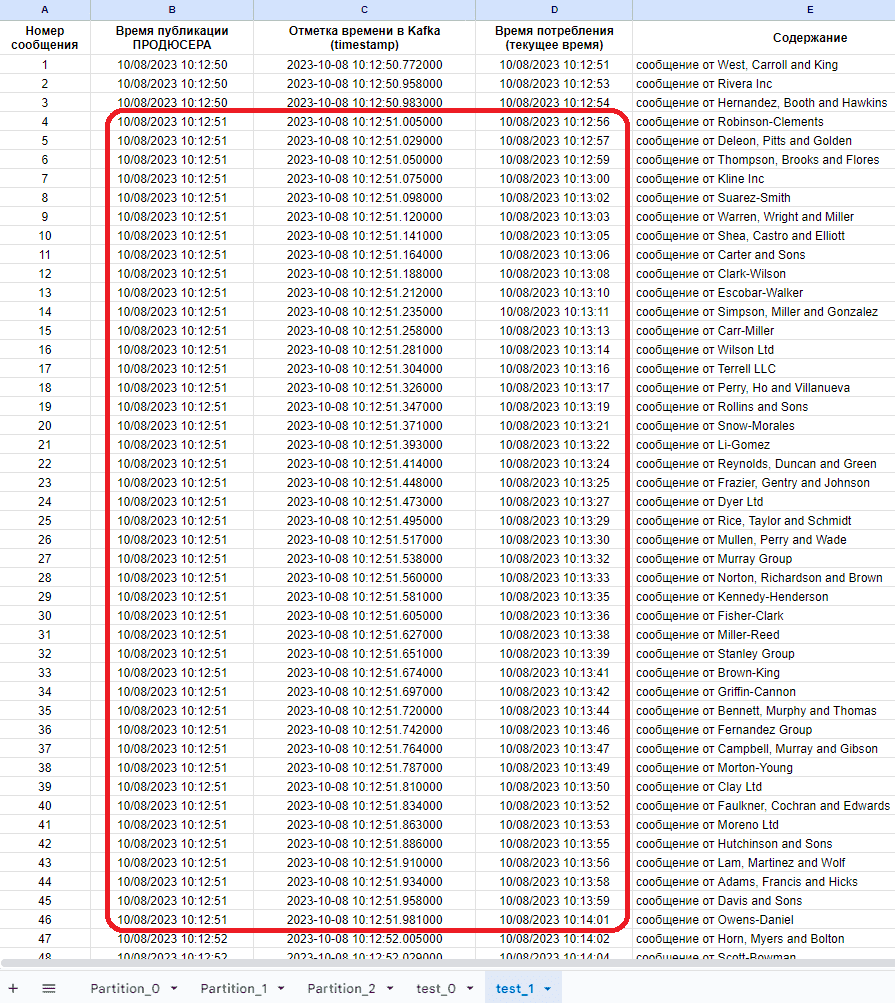
Визуализация показывает, что за 1 секунду продюсер отправляет в Kafka примерно 43 сообщения. А потребитель потребляет лишь 1 сообщение в секунду. Поэтому задержка между моментом происхождения события, его публикации в топике и моментом фактической обработки данных нарастает интегрально и приводит к тому, что общая задержка системы возрастает и уже измеряется минутами. Например, мой Python-скрипт продюсера опубликовал в Kafka 1108 сообщений, проработав с 10:12:50 до 10:13:16, т.е. всего минуту и 16 секунд. Однако, фактическая обработка всех этих сообщений приложением-потребителем завершилась в 10:41:57, т.е. интегральная задержка составила 28 минут и 41 секунду. Это уже совсем не обработка в реальном времени и даже не near real-time. Впрочем, скорей всего такое расхождение связано с долгой записью данных в Google-таблицы, которая выполняется для каждого полученного сообщения и включает накладные расходы установки соединения. Поэтому для потоковой записи событий в системы-приемники обычно используются специализированные API в библиотеках или коннекторах, например, Kafka Connect Neo4j Connector, PostgreSQL Source (JDBC) Connector for Confluent Cloud и пр. А вообще общая задержка системы зависит от многих факторов:
- где и как развернута Apache Kafka (локально или в облаке);
- объем передаваемых данных и формат сериализации сообщения;
- сложность бизнес-логики потребителя, который должен не просто считать сообщение из Kafka, но и преобразовать эти данные или отреагировать на них как-то иначе, чтобы потом перейти к следующему сообщению;
- каков фактор репликации, ожидает ли продюсер подтверждений, о том, что все брокеры-подписчики получили свою копию данных с брокера-лидера;
- криптографические операции (шифрование на строне продюсера и расшифровка на стороне потребителя), пример которых разбирается в новой статье;
- пропускная способность сетей передачи данных, как между продюсером и Kafka, так и между потребителем и Kafka.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka

