
Обучая разработчиков Big Data, сегодня рассмотрим, почему в распределенных приложениях Apache Spark случаются OOM-ошибки. Читайте далее, как работает сборка мусора JVM в Spark-приложениях, почему из-за нее случаются утечки памяти и что можно сделать на уровне драйвера и исполнителя для предупреждения OutOfMemoryError. Сборка мусора JVM и OOM-ошибки в Spark-приложениях На практике...

В рамках нового курса Эксплуатация Apache NIFI, сегодня разберем особенности развертывания этого маршрутизатора потоков Big Data на платформе управления контейнерными приложениями Kubernetes. Советы дата-инженерам, как сократить расходы на AWS, избежать сбоев узлов и потерь данных, обеспечить безопасность и автоматическое масштабирование облачного кластера Apache NiFi в Amazon EKS, а также зачем...
Добавляя в наши курсы по Apache AirFlow еще больше полезных практик, сегодня разберем опыт дата-инженеров американской компании Groupon по настройке этого фреймворка. Читайте далее, как добавить собственные KPI исполнения конвейеров обработки данных в эту workflow-платформу, делая его веб-GUI более наглядным и удобным для управления DAG’ами. Типовые возможности веб-GUI Apache Airflow...
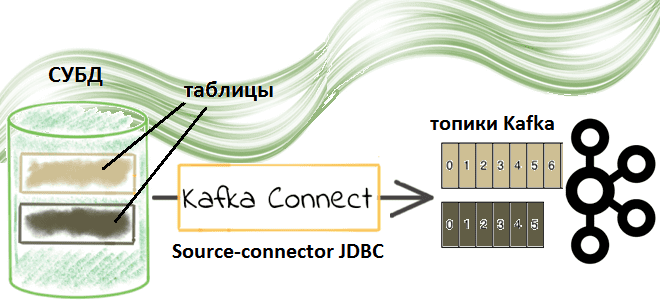
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов. Я все объясню: команда EXPLAIN в PostgreSQL Разобравшись с оператором анализа и сбора статистики по...

В этой статье по обучению Apache Spark рассмотрим, чем графический веб-интерфейс этого фреймворка полезен разработчику распределенных приложений. Читайте далее, где посмотреть кэшированные данные, визуализацию DAG, переменные среды, исполняемые SQL-запросы, а также прочие важные метрики кластерных вычислений и аналитики больших данных. 9 страниц Apache Spark UI Apache Spark предоставляет набор пользовательских...
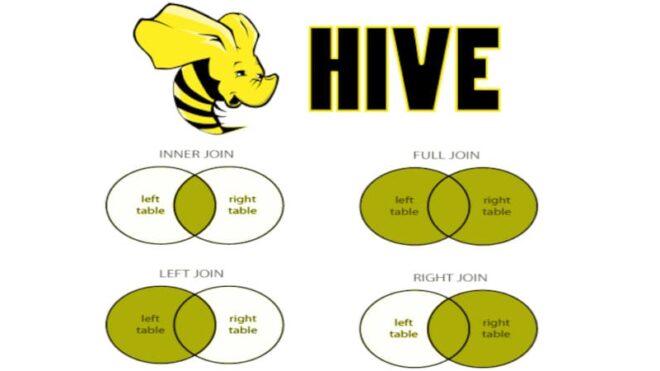
В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Развивая наши курсы по Apache AirFlow для дата-инженеров и администраторов, сегодня рассмотрим, как автоматизировать обслуживание этого фреймворка, запуская поддерживающие операции как рабочие задачи по расписанию. В этой статье разбираем опыт дата-инженеров американской ИТ-компании Clairvoyant, предложивших сообществу 3 разных DAG по обслуживанию Apache AirFlow в виде open-source проектов, доступных для свободного...