 725
725 
Содержание
Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с учетом ограничений PaaS-провайдера.
RocksDB и stateful-приложения Apache Flink: краткий ликбез
Из 3-х возможных backend’ов для хранения состояний stateful-приложений Apache Flink на практике чаще всего используется RocksDBStateBackend на базе встраиваемой key-value NoSQL-СУБД RocksDB. Во время выполнения Flink-задания RocksDB встраивается в процессы TaskManager и работает в собственных потоках с локальными файлами [1].
С помощью RocksDBStateBackend текущее (рабочее, In-flight) состояние приложения сначала записывается во внутреннюю память вне кучи, а затем сохраняется на локальные диски при достижении настроенного порогового значения. Текущее состояние в RocksDBStateBackend передается файлам на диске, поэтому его производительность напрямую влияет на RocksDB. Именно из-за такой зависимости для ускорения работы stateful-приложения Flink рекомендуется располагать каталог с данными о его текущем состоянии на локальном диске, а не в местах удаленного сетевого расположения в NFS или Hadoop HDFS. Для повышения пропускной способности и скорости следует выбирать локальные SSD-диски [1]. Однако, такая простая рекомендация не всегда реализуема на практике, особенно когда речь идет о крупных Big Data системах, развернутых в облачных кластерах. В этом случае нужно подстраиваться под особенности и ограничения PaaS-провайдера, что мы и рассмотрим далее на примере выполнения Flink-заданий в кластере Amazon Elastic Kubernetes Service (EKS) в рамках кейса интернета вещей (IoT, Internet of Things).
Что случилось с заданием Flink в облаке AWS: кейс компании Ververica
Подобно тому как Confluent занимается популяризацией и коммерциализаций Apache Kafka, а Databricks – Spark, немецкая компания Ververica продвигает Flink для разработки распределенных приложений и аналитики больших данных. Рассматриваемый кейс включает IoT-задачу обработки потока событий, исходящих от множества устройств. Каждое событие содержит идентификатор устройства, тип события и метку времени, когда событие было сгенерировано. Flink-задание разделяет поток на основе идентификатора устройства, сопоставляет тип события с последней меткой времени его получения и сохраняет это в состоянии приложения. Из сотни типов событий для каждого входящего события Flink-задание считывает метку времени из состояния для полученного типа и сравнивает ее с входящим timestamp. Если входящая метка времени новее, то сохраненный в состоянии timestamp обновляется.
Это задание Flink выполняется в кластере Amazon EKS – среде запуска и масштабирования приложений Kubernetes в облаке AWS и локально. Дополнительное конфигурирование EKS не проводилось, использовались настройки по умолчанию. На Flink TaskManager выделено 1,5 ядра ЦП и 4 ГБ памяти. В качестве хранилища состояний используется RocksDB, настроенную на управляемую память Flink. Параметр конфигурации state.backend.rocksdb.localdir явно не задан, поэтому каталог хранения временных данных /tmp на корневом томе базового экземпляра EC2 используется по умолчанию для рабочего (текущего) состояния RocksDB [2]. Это состояние (in-flight), над которым работает задание Flink, всегда хранится локально в памяти с возможностью переноса на диск и может быть утеряно при сбое задания, не влияя на возможность восстановления задания [1].
Сперва Flink-задание отлично работало на EKS, но через какое-то время его производительность резко снизилась. Однажды это падение произошло в 23:50 на уровне около 10 тысяч событий в секунду. Остановка задания с перезапуском из точки сохранения (savepoint) состояния не помогли: его пропускная способность все равно оставалась низкой, а подобные отказы повторялись все чаще. При этом падении пропускной способности загрузка ЦП контейнера TaskManager также уменьшилась. А потребление памяти в контейнере TaskManager достигло предела выделения задолго до падения пропускной способности, не особо изменившись в час Х, т.е. 23:50.
Чтобы определить причины замедления Flink-задания и понять, что случилось с TaskManager, DevOps-инженеры Flink включили управленческие расширения Java (JMX, Java Management Extensions) для контроля и управления приложениями, установив следующие параметры TaskManager JVM [2]:
env.java.opts.taskmanager: >-
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.local.only=false
-Dcom.sun.management.jmxremote.port=1099
-Dcom.sun.management.jmxremote.rmi.port=1099
-Djava.rmi.server.hostname=127.0.0.1
Подключив локально работающую VisualVM к TaskManager, специалисты просмотрели загрузку ЦП и определили, что 93% времени CPU занимал поток UpdateState, который запускает оператор UpdateState для считывания и обновления состояния в RocksDB. Внутри потока UpdateState почти все время ЦП было занято собственным методом org.rocksdb.RocksDB.get(). Это свидетельствует, что само Flink-задание стало бутылочным горлышком чтения состояния из RocksDB.
Для дальнейшей отладки были включены следующие Flink-метрики RocksDB [2]:
- backend.rocksdb.metrics.block-cache-capacity: true
- backend.rocksdb.metrics.block-cache-pinned-usage: true
- backend.rocksdb.metrics.block-cache-usage: true
- backend.rocksdb.metrics.estimate-table-readers-mem: true
По умолчанию все собственные метрики RocksDB отключены, так как они могут отрицательно сказаться на производительности Flink-задания, поэтому их следует очень осторожно применять в production. Все вышеотмеченные метрики относятся к блочному кэшу – памяти, где RocksDB кэширует данные для чтения. Этот блочный кэш быстро заполнился в первые несколько минут при запуске задания, в основном за счет записей состояния. Однако, это не объясняет внезапного падения пропускной способности около 23:50. Когда запись состояния отсутствует в блочном кеше RocksDB, ее чтение из этого хранилища состояний потребует дисковых операций ввода-вывода (IOPS). Поэтому DevOps-инженеры Ververica решили искать причину проблемы в дисках [2], что мы и рассмотрим далее.
IOPS в SSD-томах сервисов Amazon и не только
Перейдя к проверке дисковых метрик корневого тома, специалисты Ververica нашли, что пропускная способность чтения упала в момент снижения пропускной способности задания Flink. То же самое произошло и с пропускной способностью записи. После проверки емкости дисковых IOPS-операций, было обнаружено, что по умолчанию каждый экземпляр EC2 в кластере AWS EKS, созданном по умолчанию, является экземпляром m5.large с корневым gp2-томом универсального хранилища Amazon Elastic Block Store (EBS) [2]. Обычно этот высокопроизводительный сервис блочного хранилища для Amazon EC2 обеспечивает высокую пропускную способность и интенсивность транзакций рабочих нагрузок при любом масштабе.
Официальная документация Amazon EC2 отмечает, что тома с поддержкой SSD общего назначения (gp2 и gp3) и SSD с выделенным IOPS (io1 и io2) обеспечивают стабильную производительность независимо от того, является ли операция ввода-вывода случайной или последовательной. Размер IOPS ограничен 256 КБ для томов SSD и 1024 КБ для томов HDD, поскольку SSD-технология обрабатывает небольшие или случайные операции ввода-вывода намного эффективнее, чем HDD. Когда небольшие операции ввода-вывода являются физически последовательными, Amazon EBS пытается объединить их в одну IOPS-операцию до максимального возможно размера. Аналогично, когда IOPS-операции превышают максимальный размер, Amazon EBS пытается разделить их на более мелкие операции [3].
Напомним, для SSD-дисков величина IOPS сильно зависит от алгоритмов прошивки микроконтроллера и скорости работы интерфейса памяти. При последовательном доступе к данным на большом размере блока IOPS становится максимальным. У большинства SSD на основе флэш-модулей NAND величина IOPS на запись намного меньше, чем на чтение из-за того, что при попытке повторной записи в один и тот же блок запускается сборка мусора, и запись выполняется в менее используемый блок для увеличения срока службы носителя [4].
В рассматриваемом кейсе компании Ververica корневой том размером 80 ГБ обеспечивал базовую скорость 240 IOPS-операций в секунду. Поэтому DevOps-инженеры пришли к выводу, что диск переполнился, и потому производительность Flink- задания резко упала.
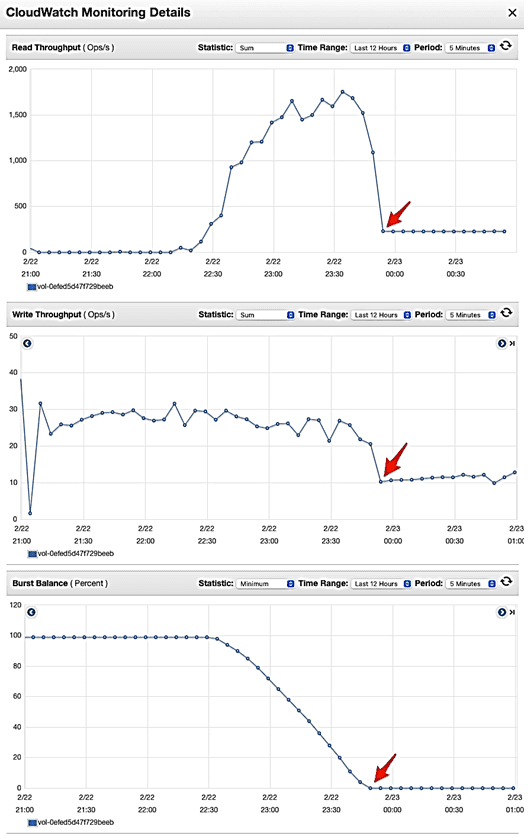
Изначально высокие показатели IOPS обеспечивались кредитами ввода-вывода, которые AWS предоставляет каждому gp2-тому для поддержки пакетных IOPS-запросов. Когда эти первоначальные кредиты были исчерпаны, а пакетный баланс упал до 0, и случилась проблема с Flink-заданием. Определив это, специалисты Ververica решили подключить выделенный том с высокой IOPS-скоростью, например, использовать том gp3 или io1/io2, а затем установить в нем каталог для хранения состояния Backend.rocksdb.localdir в конфигурации Flink [2].
Таким образом, из всей этой детективной истории можно сделать вывод, для эффективной разработки Flink-приложений необходимо знать особенности не только этого фреймворка, но и окружения, в котором он развернут. О том, как упростить процесс разработки и отладки Flink-приложений с помощью Byteman, читайте в нашей новой статье.
Освоить все тонкости разработки дата-конвейеров и распределенных приложений потоковой аналитики больших данных с Apache Flink, а также прочими компонентами экосистемы Hadoop вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

