 814
814 
Содержание
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов.
Я все объясню: команда EXPLAIN в PostgreSQL
Разобравшись с оператором анализа и сбора статистики по таблицам, рассмотрим, какие инструменты помогают дата-аналитику и SQL-разработчику оптимизировать выполнение запросов в Greenplum. План выполнения запроса – это отчет с подробным описанием шагов, которые определил оптимизатор СУБД. План представляет собой дерево узлов, читаемое снизу вверх, где каждый узел передает свой результат вышестоящему. Каждый узел – это шаг в плане, а одна строка для узла определяет операцию, выполняемую на этом шаге, например, сканирование, соединение, агрегирование или сортировку. Узел также определяет метод для выполнения операции: последовательное сканирование или сканирование индекса. Операция соединения может выполняться через хэш или с вложенным циклом [1].
Перед тем, как погружаться в Greenplum, вспомним, что эта MPP-СУБД основана на open-source СУБД PostgreSQL, которая реализует объектно-реляционный подход и поддерживает полуструктурированные данные в формате JSON, а также соответствует стандарту стандарта SQL:2011. В PostgreSQL команда EXPLAIN выводит план выполнения SQL-запроса, генерируемый планировщиком для заданного оператора. Этот план показывает, как будут сканироваться таблицы (последовательно, по индексу и пр.) и какой алгоритм соединения будет объединять считанных из них строки.
Также EXPLAIN показывает ожидаемую стоимость выполнения оператора, т.е. затраты на его выполнение, которые обычно означают число обращений к странице на диске. При этом фактически выводятся два числа: стоимость запуска до выдачи первой строки и общая стоимость выдачи всех строк, что особенно важно для большинства SQL-запросов. При добавлении к команде EXPLAIN параметра ANALYZE анализируемый оператор будет выполнен на самом деле, а не только запланирован, а в вывод добавятся фактические сведения о времени выполнения, включая общее время, затраченное на каждый узел плана в миллисекундах и общее число строк в результате. Это помогает понять, насколько точны предварительные оценки планировщика.
Важно, что при измерении фактической стоимости выполнения каждого узла в плане, реализация EXPLAIN ANALYZE в PostgreSQL вносит накладные расходы профилирования в выполнение запроса. Поэтому при запуске запроса командой EXPLAIN ANALYZE он может выполняться дольше, особенно в операционных системах, с длительным процессом получения текущего времени [2].
На практике для анализа и визуализации планов выполнения SQL-запросов в PostgreSQL-совместимых базах (Timescale, Citus, Greenplum и Redshift) можно использовать открытый сервис российской компании «Тензор» — https://explain.tensor.ru/. Он позволяет проанализировать планы любой сложности и увидеть алгоритм выполнения SQL-запроса со всеми числовыми показателями [3, 4].
Администрирование Greenplum - Arenadata DB
Код курса
GRAD
Ближайшая дата курса
12 января, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Как посмотреть план выполнения SQL-запросов в Greenplum
Практически все, что сказано про EXPLAIN и EXPLAIN ANALYZE в PostgreSQL справедливо и для Greenplum [1]:
- EXPLAIN отображает план запроса и предполагаемую стоимость запроса, но не выполняет сам запрос;
- EXPLAIN ANALYZE выполняет запрос в дополнение к отображению плана запроса, отбрасывая любой вывод оператора SELECT, но выполняя другие операции, например, INSERT, UPDATE или DELETE.
Чтобы применять оператор EXPLAIN ANALYZE без влияния на данные, его нужно явно использовать в транзакции:
BEGIN;
EXPLAIN ANALYZE …;
ROLLBACK.
Команда EXPLAIN ANALYZE запускает оператор в дополнение к отображению плана со следующей дополнительной информацией:
- общее время в миллисекундах на выполнение запроса;
- количество worker’ов (сегментов), задействованных в операции узла плана;
- максимальное количество строк, возвращаемых сегментом, с идентификатором сегмента, который произвел наибольшее количество строк для операции;
- память, используемая операцией;
- время в миллисекундах для извлечения первой строки из сегмента, который произвел наибольшее количество строк, и общее время, затраченное на извлечение всех строк из этого сегмента.
Как читать планы выполнения запросов: смотрим на практическом примере
Рассмотрим пример плана выполнения SQL-запроса, который находит количество строк в таблице вкладов, хранящихся в каждом сегменте Greenplum [1]:
EXPLAIN SELECT gp_segment_id, count(*)
FROM contributions
GROUP BY gp_segment_id;
План выполнения этого SQL-запроса в Greenplum и его диаграмма, полученные в сервисе компании «Тензор» https://explain.tensor.ru/, будут выглядеть следующим образом [4]:
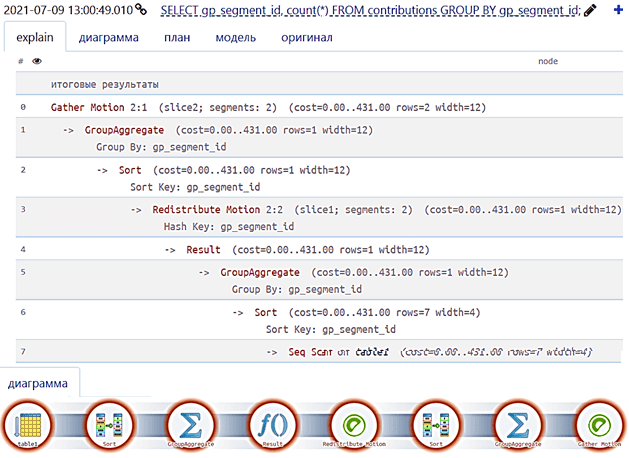
Модель выполнения выглядит так [4]:
Process
-> Redistribute Motion
-> Result
-> Process
-> Scan Table table1
Этот план имеет восемь узлов, отмеченных оранжевым цветом, а каждый узел содержит три оценки стоимости [1]:
- cost — стоимость при последовательном чтении страниц с диска, включая стоимость получения первой строки и общую стоимость получения всех строк;
- rows — количество строк, выводимых узлом плана, что может быть меньше фактического количества строк, обработанных или отсканированных узлом из-за избирательности условий WHERE. При этом общая стоимость предполагает, что будут извлечены все строки, что на практике бывает не всегда, например, условие ограничено параметром LIMIT.
- width — общая ширина в байтах всех столбцов, выводимых узлом плана.
Оценки стоимости в узле включают стоимость всех его дочерних узлов, поэтому самый верхний узел плана, обычно Gather Motion, имеет предполагаемые общие затраты на выполнение плана. Это число, которое планировщик запросов стремится минимизировать. Поэтому при оптимизации SQL-запроса следует сперва выявить узлы плана, где расчетная стоимость выполнения операции очень высока, оценив предполагаемое количество строк и затраты на выполнение операции. Как это сделать мы рассмотрим в следующей статье, разобрав из чего еще состоит план выполнения SQL-запросов в Greenplum и как влияют разные операторы сканирования, соединения, перемещения на результаты. А также выясним, что именно из вывода команды EXPLAIN поможет разработчику распределенных приложений и дата-аналитику оптимизировать SQL-запросы с учетом кластерной специфики этой MPP-СУБД.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освойте тонкости администрирования и эксплуатации Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на авторских курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
Источники
- https://gpdb.docs.pivotal.io/6-16/best_practices/tuning_queries/
- https://postgrespro.ru/docs/postgresql/13/sql-explain
- https://habr.com/ru/company/tensor/blog/531620/
- https://explain.tensor.ru/

