
В рамках нового курса Эксплуатация Apache NIFI, сегодня разберем особенности развертывания этого маршрутизатора потоков Big Data на платформе управления контейнерными приложениями Kubernetes. Советы дата-инженерам, как сократить расходы на AWS, избежать сбоев узлов и потерь данных, обеспечить безопасность и автоматическое масштабирование облачного кластера Apache NiFi в Amazon EKS, а также зачем...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...

Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при...
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...
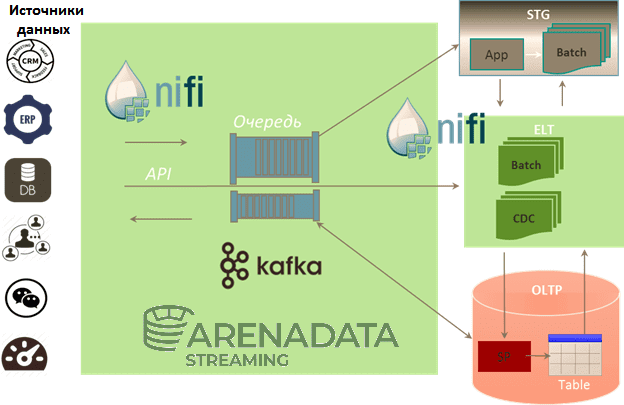
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
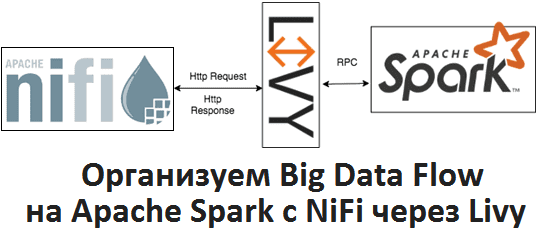
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...