 1041
1041 
Содержание
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3.
Пример потокового конвейера обработки данных на технологиях Big Data
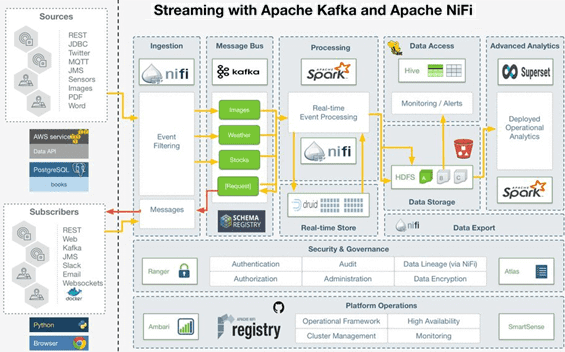
Разберем кейс, когда необходимо использовать несколько источников, включая каналы REST, социальные каналы, сообщения, изображения, документы и реляционные данные. Типовой конвейер обработки данных (data pipeline) в этом случае будет выглядеть следующим образом [1]:
- Apache NiFi принимает потоковые данные, фильтрует их, обрабатывает и отправляет в соответствующие топики Apache Kafka с учетом схем для записи форматов сообщений.
- Дополнительная обработка событий для последующей аналитики больших данных и тренировки алгоритмов машинного обучения выполняется в рамках приложений Kafka Streams, Spark и NiFi.
- Для оперативной аналитики и генерации сводок в реальном времени данные сохраняются в Apache Druid– колоночной СУБД, ориентированной на быструю обработку больших, редко изменяющихся массивов данных и немедленного предоставления доступа к ним. Обычно Druid применяется в решениях, где необходим прием информации в реальном времени из одного большого потока данных [2].
- В качестве постоянного хранилища данных используются Apache Hive, HDFS и AWS S3
- За машинное обучение отвечают Spark ML, TensorFlow и Apache MXNet.
- Отправка очищенных и агрегированных данных подписчикам выполняется через Kafka и NiFi.
- Конечная аналитика и визуализация данных реализуется через интерактивные дэшборды с помощью Apache Superset, Superset и Spark SQL.
- Обеспечение базовой информационной безопасности поддерживается в виде авторизации, аутентификации, аудита, шифрования и передачи данных через Apache Ranger, Atlas и NiFi.
- Для управления исходным кодом в лучших практиках DataOps используются реестр NiFi и github.
- Комплексное администрирование экосистемы Hadoop выполняется в рамках Apache Ambari.
Как обычно, в Apache NiFi подобный data pipeline реализуется в графическом виде через создание и конфигурирование процессоров обработки потоковых данных (Flow File Processor), а также соединений (Connection), которые отвечают за определение того, как потоковый файл (FlowFile) передается между процессорами.

Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Обогащение данных и еще пара плюсов Apache NiFi
В этот типовой конвейер обработки Big Data можно также внести этап обогащения данных, которое представляет собой получение данных из внешнего источника (СУБД, файл, API и пр.) для добавления дополнительных деталей, контекста или других полезных сведений к загружаемой информации. Обычно при этом добавляемые данные содержат не фактическую информацию, а ссылки, например, идентификаторы, для обращения к другим источникам данных через запрос определенного атрибута нужного объекта. Часто обогащение выполняется в пакетном режиме с помощью операции соединения (JOIN). Потоковый режим обогащения данных Apache NiFi поддерживает с версии 1.3 через процессоры LookupAttribute и LookupRecord, а также специальные сервисы поиска, такие как Simple Key Value Lookup Service или MongoDB Lookup Service [3].
Примечательно, что Apache NiFi упрощает работу Big Data инженера не только благодаря наглядному веб-GUI, но и внутренней оптимизации взаимодействия с потоками данных. В частности, чтобы не превысить объем памяти JVM, который является типичным ограничением экосистемы Hadoop, когда данные проходят через NiFi, в качестве FlowFile передается указатель на данные. Доступ к содержимому потокового файла осуществляется только по необходимости. Это позволяет работать с полезными данными в потоковом режиме, не считывая большой трафик. Таким образом, экономится объем памяти JVM. Например, типичным шаблоном переноса данных в HDFS из NiFi является использование процессора MergeContent непосредственно перед процессором PutHDFS. MergeContent может взять много файлов малого или среднего размера и объединить их вместе, чтобы сформировать файл подходящего размера для HDFS. Процессор делает это путем копирования всех входных потоков из исходных файлов в новый выходной поток, объединяя большое количество файлов без превышения объема памяти JVM [4].
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
22 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Это не единственный пример удобства использования Apache NiFi с точки зрения разработчика потоков данных (Data Flow). Еще один интересный кейс отмечает отечественная ИТ-компания Axmor, которая использует этот Big Data инструмент в качестве ETL-интерфейса, реализуя основную обработку данных с помощью Apache Spark. Дополнительным преимуществом NiFi Axmor считает наличие библиотеки Jolt для работы с полуструктурированными данными в формате JSON [5]. С помощью процессора JoltJsonTransform она позволяет преобразовать JSON-файл к нужной структуре [6], а также дает возможность посмотреть параметры блока входных данных и выходных данных сразу на одном экране, что очень удобно. В частности, Axmor забирает нужные данные с помощью SQL-запроса с удаленного сервера и преобразует их в JSON, добавляя в него служебную информацию с помощью Jolt. Полученные данные в нужной схеме записываются в корпоративную СУБД MongoDB [5].
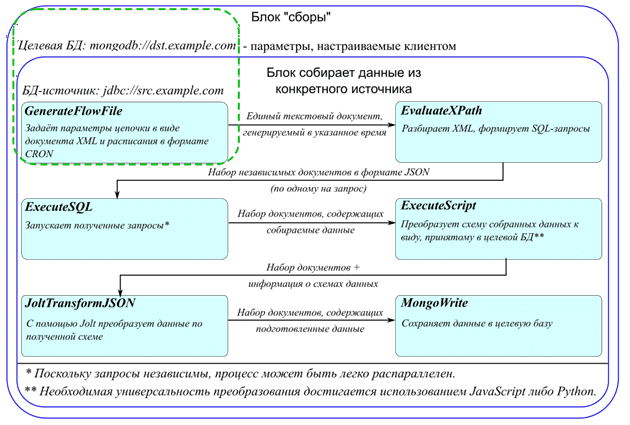
В следующей статье мы подробнее рассмотрим, как Apache NiFi позволяет использовать SQL-запросы для фильтрации определенных столбцов, строк или полей, их переименования, вычислений, агрегаций и маршрутизации потоковых данных. А научиться эффективно администрировать и использовать Apache NiFi, Spark и Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://community.cloudera.com/t5/Community-Articles/Real-Time-Stock-Processing-With-Apache-NiFi-and-Apache-Kafka/ta-p/249221
- https://ru.bmstu.wiki/Apache_Druid
- https://community.cloudera.com/t5/Community-Articles/Data-flow-enrichment-with-NiFi-part-1-LookupRecord-processor/ta-p/246940
- https://cwiki.apache.org/confluence/display/NIFI/FAQs
- https://axmor.ru/articles/kak-primieniat-apache-nifi-v-bi-proiektakh/
- http://ijokarumawak.github.io/nifi/2016/11/22/nifi-jolt/

