Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output Per Second), которая станет «бутылочным» горлышком всей системы. Читайте далее, как справиться с этим, не снижая качества, объемов и скоростей.
Где Apache NiFi хранит данные и как конфигурировать эти хранилища
Apache NiFi работает с потоковыми файлами (FlowFile), каждый из которых представляет собой единый фрагмент информации из заголовка и содержимого, аналогично HTTP-запросу. Заголовок содержит атрибуты, которые описывают тип данных содержимого, время создания и уникальный идентификатор (uuid), а также пользовательские свойства. Содержимое FlowFile — это просто необработанные данные, которые передаются: простой текст, JSON, байт-коды и пр. [1].
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
20 января, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Представьте типовой кластер Apache NiFi, который ежедневно обрабатывает ТБ данных. Каждый процессор, который читает, изменяет или записывает содержимое потоковых файлов, выполняет операцию ввода-вывода с жестким диском. Подробнее о том, как это происходит, читайте в нашей новой статье. Соответственно, тысячи потоков данных, которые обрабатывают тысячи потоковых файлов одновременно, создают тысячи операций ввода-вывода в секунду (IOPS). А если, как это особенно популярно сегодня, NiFi запускается поверх Kubernetes, количество таких операций увеличивается, а их качество становится значительно хуже, т.к. прибавляется передача данных по сети. В результате придется инвестировать больше средств в аппаратное обеспечение кластера Apache NiFi, покупая более дорогие ресурсы с увеличенным количеством ОЗУ и ПЗУ. Таким образом, возникает проблема организации хранения данных, где хранится содержимое каждого потокового файла. Однако NiFi позволяет настраивать репозитории контента как для постоянного (на диске), так и для временного хранения в ОЗУ [2].
Напомним, репозиторий контента хранит содержимое всех FlowFiles в системе. По умолчанию он устанавливается в тот же корневой каталог установки, что и все другие репозитории. Однако, рекомендуется не размещать репозиторий контента на том же диске, что и репозиторий FlowFile. При обработке большого объема данных, репозиторий контента может заполнить диск, повредив репозиторий FlowFile, если он находится там же. За реализацию репозитория контента отвечает параметр nifi.content.repository.implementation, который по умолчанию установлен org.apache.nifi.controller.repository.FileSystemRepository. Изменять его нужно очень осторожно. В частности, чтобы хранить содержимое потокового файла в памяти, а не на диске с риском потери данных в случае сбоя питания у конкретной машины, для этого свойства следует задать значение org.apache.nifi.controller.repository.VolatileContentRepository [3]. Также имеет смысл использовать значение VolatileFlowFileContentRepository, если нет необходимости в постоянном хранении контента: репозиторий FlowFile будет очищаться, поэтому в нем будут храниться метаданные уже удаленного содержимого.
Изменяя реализацию репозитория контента, можно столкнуться с новыми проблемами, такими как ошибка Content Repository out of space из-за уменьшения объема памяти в RAM по сравнению с диском, JavaHeapSpace и пр. Поэтому, при использовании VolatileContentRepository следует настроить 2 новых свойства — nifi.volatile.content.repository.max.size и nifi.volatile.content.repository.block.size. Настройка этих свойств в соответствии с ресурсами, которые будут предоставлены кластеру Apache NiFi, предотвратит появление упомянутых выше ошибок.
Таким образом, изменив репозиторий контента с диска на RAM, можно не только резко снизить количество операций ввода-вывода в секунду, но также и улучшить производительность потоков данных, поскольку операции с RAM намного быстрее, чем с дисками, в т.ч. при работе с контейнерами. Обратной стороной этого преимущества является потребность в более дорогой оперативной памяти вместо SSD или жесткого диска. Но, поскольку имеется рост производительности, данные не будут оставаться в репозитории контента слишком долго, поэтому требуемый объем RAM не сравним с дисковым пространством.
Например, запуская кластер Apache NiFI на Kubernetes, вместо 7 узлов по 500 ГБ жесткого диска, 32 ГБ ОЗУ и 12 ядер ЦП, можно использовать 3 узла с 50 ГБ жесткого диска, 50 ГБ ОЗУ и 8 ядрами ЦП. Уменьшение загрузки ЦП происходит из-за лучшей производительности репозитория содержимого ОЗУ. Таким образом, несложная смена конфигурационных параметров позволяет эффективно работать на меньшем кластере с меньшими ресурсами, снизив IOPS с 8000 на узел до 400. Примечательно, что помимо экономии затрат на ресурсы, это также повысило производительность потоков данных, позволив кластеру Apache NiFi ежедневно обрабатывать примерно в 5 раз больше данных [2]. Тем не менее, любая оптимизация не проходит даром: когда контент хранится в ОЗУ, кластер NiFi становится ненадежным. Как решить эту проблему с помощью Apache Kafka, мы рассмотрим далее.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
20 января, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Еще раз о пользе синергии с Apache Kafka
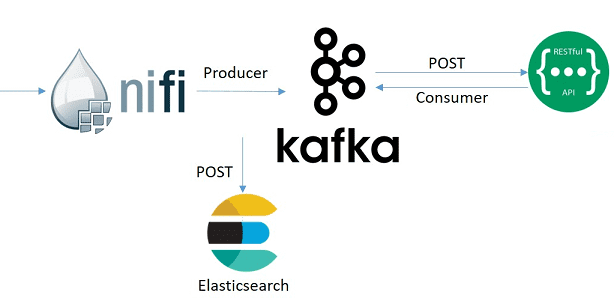
Итак, если оптимизировать хранение потоковых файлов NiFi, разместив репозиторий контента в памяти, а не на диске, кластер становится энергозависимым, что значительно снижает его надежность. Эту проблему поможет решить другая Big Data система для работы с потоковыми данными – Apache Kafka. Она отлично подходит для роли временного хранилища данных, являясь не просто брокером сообщений, а целой стриминговой платформой с низкими требованиями к оборудованию, в т.ч. IOPS. Дополнительно к тому можно добавить компонент ELK-стека Logstash, который позволяет прослушивать Kafka, фильтруя нужные события, и отправлять их далее, например, в Elasticsearch. Как именно связать NiFi с Kafka, читайте здесь.
Возвращаясь к проблеме IOPS, следует отметить, что Logstash практически не производит операций ввода-вывода с диском, выполняя обработку данных в оперативной памяти. Более того, Logstash очень прост и удобен в установке и обслуживании, особенно при работе с Kubernetes. Таким образом, добавление новых компонентов в систему далеко не всегда увеличивает накладные расходы [2]. Подробнее о совместном использовании Apache Kafka с NiFi мы рассказывали здесь.
В заключение отметим, что одним из важных достоинств Apache NiFi является его масштабируемость и гибкая настройка кластера к особенностям решаемой задачи. Например, если NiFi отвечает только за перемещение данных с FTP-сервера в Apache HDFS, потребуется немного ресурсов. Но в случае приема данных из сотен источников, фильтрации, маршрутизации, выполнения сложных преобразований и, наконец, доставки потоков Big Data в несколько разных мест, это потребует дополнительных аппаратных мощностей [4].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
20 января, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Поэтому задачей администратора Big Data и инженера данных является подбор таких конфигурационных настроек, которые позволят эффективно решать рабочие задачи без чрезмерных инвестиций в оборудование. Как сделать это на практике, вы узнаете на специализированных курсах для администраторов и разработчиков Data Flow в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.zirous.com/2019/07/03/nifi-vs-kafka-or-is-it/
- https://medium.com/swlh/apache-nifi-the-iops-problem-2974d21eb67c
- https://nifi.apache.org/docs/nifi-docs/html/administration-guide.html
- https://blog.cloudera.com/benchmarking-nifi-performance-and-scalability/