 1033
1033 
Содержание
Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при чем здесь Apache Calcite.
5 особенностей работы с SQL-запросами в Apache NiFi
Итак, в Apache NiFi есть обработчики (процессоры), которые позволяют пользователям писать SQL-операторы SELECT для обработки их данных по мере прохождения через систему. При этом каждый потоковый файл (FlowFile) в NiFi можно рассматривать как таблицу базы данных с именем FLOWFILE. Этот подход позволяет фильтровать данные по столбцам, полям или строкам, переименовывать их, выполнять вычисления, агрегацию и маршрутизацию данных с помощью типовых SQL-запросов. Примечательно, что по сравнению с другими системами, которые предоставляют механизм SQL для произвольных данных вне СУБД, Apache NiFi обладает следующими отличительными характеристиками [1]:
- локальное выполнение запросов без отправки данных в какой-либо внешний сервис, например, Amazon Это позволяет обойтись без облачного хранилища, а также экономит время и средства на передачу трафика или создание временных «промежуточных таблиц» в СУБД.
- запросы встраиваются в конвейеры передачи и обработки данных (data pipeline). В частности, поскольку данные уже передаются через NiFi, можно просто добавить к существующему data pipiline’у новый процессор, такой как QueryRecord, который оценивает SQL-запрос относительно содержимого FlowFile и передает результат его выполнения в выходной поток.
- результаты выполнения запроса могут быть записаны в любом формате. Эту возможность обеспечивает конфигурируемый процессор со служебными контроллерами чтения и записи: «Record Reader» Controller Service и «Record Writer» Controller Service. По умолчанию он может считывать форматы CSV, JSON, AVRO и даже лог-файлы. Результаты запроса могут быть записаны в CSV, JSON, AVRO или в тексте произвольной формы, например, в формате лога с использованием встроенного языка выражений NiFi (Expression Language). Если данные находятся в другом формате, можно написать собственную реализацию служебного контроллера чтения или записи данных в уникальном формате. Также есть возможность обернуть существующую библиотеку возврата объектов типа запись (Record) из входящего потока (InputStream), что позволяет запускать SQL поверх любого формата данных.
- высокая скорость выполнения запросов, которая во многом зависит от производительности дисков и их количества. Данные должны быть прочитаны с диска, запрошены, а затем результаты записаны на диск. Однако в большинстве случаев чтения данных с диска можно избежать благодаря кэшированию на уровне операционной системы.
- Возможность отслеживать происхождение данных (Data Provenance), что позволяет понять, как именно выглядели данные в каждой точке потока, и точно определить, что и когда стало некорректным, а также идентифицировать, откуда эти данные и куда они пошли. При обновлении потока, данные можно легко воспроизвести снова и проверить новые результаты.
Далее мы подробнее рассмотрим, как процессор QueryRecord Processor работает с данными через механизм SQL-запросов.
Как работают процессоры для SQL-запросов в Apache NiFi
С точки зрения реализации, процессор QueryRecord основан на Apache Calcite – cтандартном SQL-анализаторе, валидаторе и JDBC-драйвере, широко используемом в промышленной разработке. Он позволяет подключаться к внешним источникам данных, просматривать метаданные и оптимизировать запросы с помощью правил реляционной алгебры. Можно сказать, этот фреймворк представляет собой среду управления динамическими данными со множеством элементов типичной СУБД, но без некоторых ее функций, таких как хранение, алгоритмы обработки и репозиторий для хранения метаданных. Поскольку Calcite намеренно не участвует в хранении и обработке данных, это делает его отличным средством для посредничества между приложениями, хранилищами данных и механизмами их обработки. Кроме того, это идеальная основа для создания базы данных, куда их нужно просто добавить [2].
Для работы с процессором QueryRecord его следует просто добавить на граф конвейера обработки потоковых данных. Как обычно в Apache NiFi, это делается в рамках наглядного веб-GUI. Далее следует настроить службу контроллера для чтения данных и записи результатов, выбрав нужный формат, а также задать необходимый SQL-запрос. Перед запуском SQL-запроса следует задать схему данных для их считывания. Для этого можно использовать атрибут FlowFile, который включает схему в формате AVRO. Или обратиться к реестру схем для хранения уникальной схемы и доступа к ней по имени или по идентификатору и версии. Это задается через соответствующее свойство при настройке службы контроллера [1].
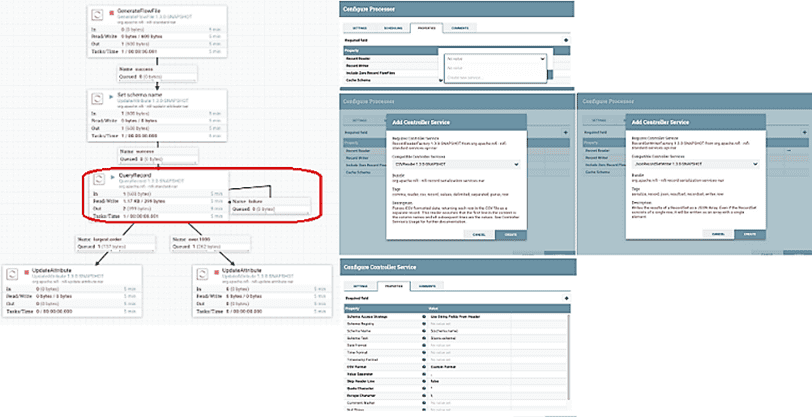
Подробные примеры выполнения SQL-запросов и конфигурационных параметров QueryRecord для работы с CSV-файлами в [1].
Подводя итог работе с SQL-запросами в Apache NiFi, отметим еще один процессор – ExecuteSQL, который предоставляет запрос SQL SELECT с выдачей результатов в формате AVRO. Его запуск можно запланировать по расписанию (таймеру) или cron-выражению или от входящего FlowFile. В последнем случае атрибуты этого потокового файла будут доступны при оценке запроса. В частности, атрибут FlowFile ‘executesql.row.count‘ указывает количество выбранных строк [3]. На практике именно может ExecuteSQL процессор использоваться для соединения Apache NiFi с Cloudera Impala через JDBC-драйвер [4]. Разумеется, все рассмотренные SQL-процессоры могут быть добавлены в потоковый ETL-конвейер обработки и маршрутизации Big Data на базе Apache NiFi, Kafka и Spark Streaming подобно тому, как мы рассматривали здесь. В следующей статье мы продолжим разговор про потоковую обработку больших данных и рассмотрим кейс китайской компании Fano Labs, которая построила на Apache Kafka конвейер для своей NLP-системы речевой аналитики с помощью алгоритмов машинного обучения.
Больше подробностей по администрированию и эксплуатации Apache NiFi для потоковой обработки и аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://community.cloudera.com/t5/Community-Articles/Real-Time-SQL-On-Event-Streams/ta-p/246336
- https://calcite.apache.org/docs/
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.5.0/org.apache.nifi.processors.standard.ExecuteSQL/index/
- https://community.cloudera.com/t5/Community-Articles/Connecting-Nifi-to-Impala-using-Simba-JDBC-driver/ta-p/294226

