
Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим проблемы неконстистентности чтения из графовой СУБД Neo4j и способы их решения. Что такое bookmarks-механизм, как работает объект сеанса в Neo4j в кластерном режиме и при чем здесь драйверы. Зачем нужны закладки в Neo4j Драйверы графовой...

Недавно мы писали про рекомендательную систему американской медиа-компании Meredith Corporation на основе графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Продолжая эту тему в рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как построить простой рекомендательный движок с помощью выражений и операторов языка запросов Cypher...
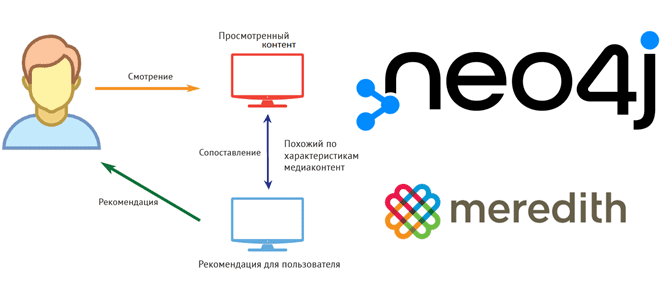
Развивая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим американского медиаконгломерат Meredith Corporation по персонализации пользовательских профилей с помощью графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Постановка задачи: сложности идентификации анонимных клиентов Различными контент-продуктами конгломерата Meredith Corporation ежемесячно пользуется более 180 миллионов человек через приложения,...
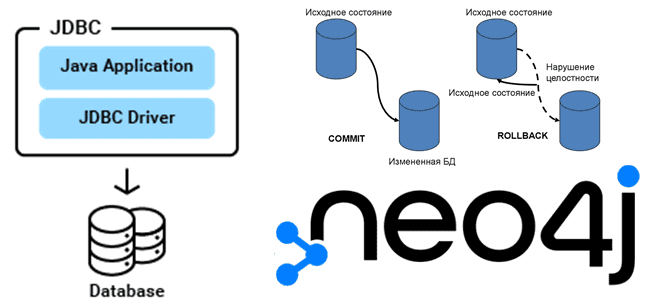
Зачем проверять подключение к Neo4j, какую URI-схему выбрать, чем плохи транзакции с автофиксацией и как передавать переменные в Cypher-запросы: рекомендации по использованию драйверов графовой СУБД в реальных приложениях аналитики больших данных. Драйверы и особенности подключения к базе данных Напомним, драйвер – это сущность, которая реализует определённые API-интерфейсы для взаимодействия с...
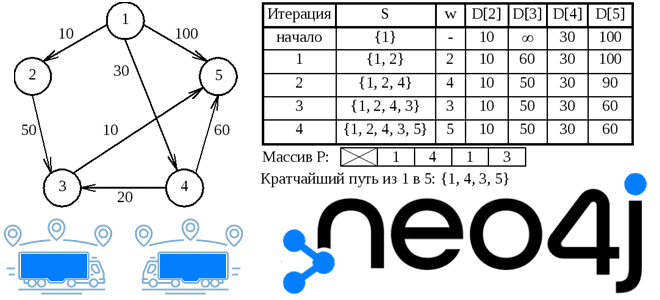
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...

В рамках обучения ИТ-архитекторов и разработчиков распределенных приложений рассмотрим, что представляет собой Transactional Outbox и как этот паттерн проектирования микросервисной архитектуры можно реализовать с помощью Neo4j и Apache Kafka, чтобы создать масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта. Постановка задачи: проблемы микросервисной архитектуры и способы их...
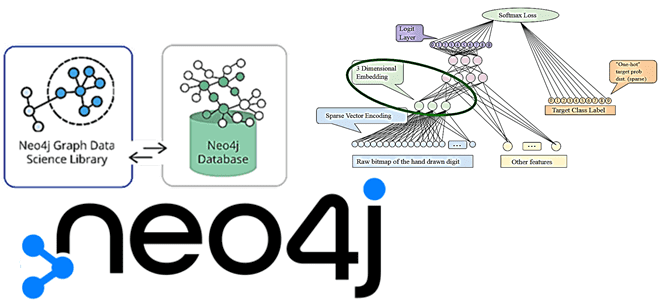
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

В рамках нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим популярную сегодня тему про невзаимозаменяемые токены в криптовалютах и не только. Пример анализа графа по NFT-транзакциям в графовой СУБД Neo4j с помощью инструкций языка запросов Cypher. Что такое NFT и причем здесь блокчейн с криптовалютами Уникальный или невзаимозаменяемый...

Продвигая наш новый курс по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим применение теории графов к задаче анализа социальных связей на практическом примере возможностей библиотеки Graph Data Science СУБД Neo4j и ее языка запросов Cypher. А также разберем сопутствующую теорию: что такое центральность графа, почему эта мера не подходит для сетей...