
При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

В этой статье мы рассмотрим наиболее значимые факторы по выбору образовательных курсов по Apache Kafka и другим технологиям больших данных (Big Data). А также расскажем, как эти условия реализуются в нашем учебном центре, чтобы сделать повышение квалификации ИТ-специалистов и руководителей максимально эффективным. Что важно при выборе курсов по Кафка Проанализировав...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...
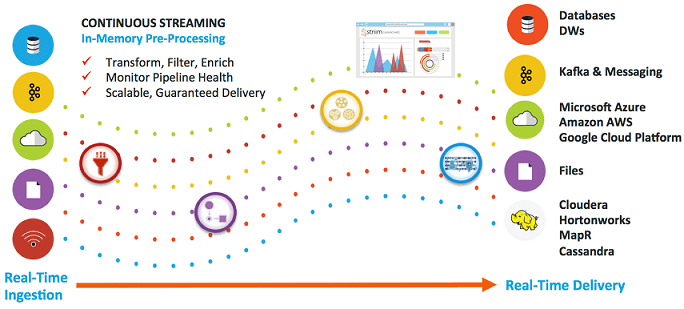
Рассмотрев пакетные ETL-инструменты больших данных, сегодня мы поговорим про потоковые средства загрузки и маршрутизации информации из различных источников: Apache NiFi, Fluentd и StreamSets Data Collector. Читайте в нашей статье про их сходства, различия, достоинства и недостатки. Также мы собрали для вас реальные примеры их практического использования в Big Data системах...
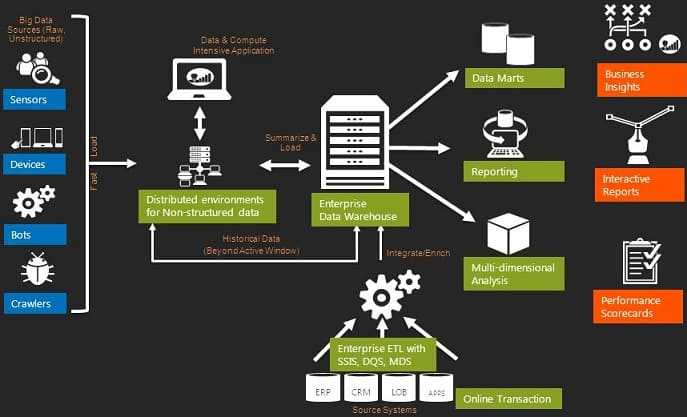
Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet...
Популярность Apache NiFi в Big Data системах и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), обусловлена широкими функциональными возможностями этой платформы по быстрой загрузке и маршрутизации данных любого формата между множеством источников и приемников информации. Также среди ключевых преимуществ NiFi отмечается распределенная архитектура, масштабируемость, наличие...