 1109
1109 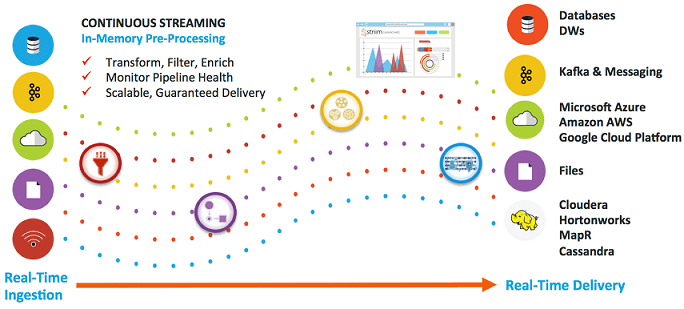
Содержание
Рассмотрев пакетные ETL-инструменты больших данных, сегодня мы поговорим про потоковые средства загрузки и маршрутизации информации из различных источников: Apache NiFi, Fluentd и StreamSets Data Collector. Читайте в нашей статье про их сходства, различия, достоинства и недостатки. Также мы собрали для вас реальные примеры их практического использования в Big Data системах и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial IoT, IIoT).
Как используется Apache Flume для потоковых ETL-задач
Из систем потоковой загрузки данных среди проектов фонда Apache Software Foundation (ASF), кроме NiFi, на практике часто используется Apache Flume – распределенная и высоконадежная система для эффективного сбора, агрегации и сохранения больших объемов логов из множества различных источников в централизованное хранилище данных. Изначально созданный для потоковой обработки логов в конвейерах, Flume масштабируется горизонтально и управляется событиями. Этот ETL-инструмент характеризуется низкой временной задержкой (low latency), отказоустойчивостью и гибкими возможностями дополнения за счет мощного API-интерфейса и SDK (software development kit).
Из недостатков Flume стоит отметить, что он, как и Apache NiFi, гарантирует доставку сообщений в семантиках «максимум один раз» (at most once) и «по крайней мере один раз» (at least once). Это позволяет быстро перемещать данные и удешевлять обеспечение отказоустойчивости за счет минимизации состояний, которые нужно хранить. Также Flume позволяет доставлять события «по крайней мере один раз», но это сказывается на пропускной способности системы и может привести к дублированию сообщений [1].
Тем не менее, на практике Apache Flume широко используется в качестве ETL-средства для Big Data. В частности, сингапурская ИТ-компания Capillary Technologies, которая предоставляет облачную платформу электронной коммерции и сопутствующие услуги для розничных продавцов и брендов Omnichannel Customer Engagement, применяет Flume для агрегации логов с 25 различных источников данных. Корпорация Mozilla использует Flume вместе с ElasticSearch в проекте BuildBot по созданию своего инструмента непрерывной интеграции при разработке программного обеспечения, который автоматизирует цикл компиляции или тестирования, необходимый для проверки изменений в коде проекта. Сейчас это средство используется в Mozilla, Chromium, WebKit и многих других проектах. Один из крупнейших травел-агрегаторов Индии, компания Goibibo также применяет Flume для передачи журналов из своих производственных систем в HDFS [2].
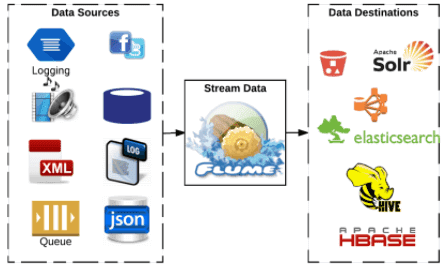
Другие решения для потокового ETL в Big Data
Среди платформ загрузки и маршрутизации данных, не являющихся проектами фонда ASF, наиболее часто для передачи информации между разными источниками и приемниками используются следующие:
- Fluentd – открытый коллектор данных, предназначенный для объединения и систематизации масштабируемой инфраструктуры логов. Собранные с помощью Fluentd могут быть переданы для хранения и дальнейшей обработки в базы данных (MySQL, PostgreSQL, CouchBase, CouchDB, MongoDB, OpenTSDB, InfluxDB) распределенные файловые системы, включая HDFS, облачные сервисы (AWS, Google BigQuery), поисковые инструменты (Elasticsearch, Splunk, Loggly) [3].
- StreamSets Data Collector – наиболее похожая на Apache NiFi корпоративная инфраструктура непрерывного приема больших данных с открытым исходным кодом. Благодаря наличию пользовательского веб-GUI она позволяет разработчикам, инженерам, аналитикам и ученым по данным легко создавать ETL-конвейеры со сложными сценариями загрузки. StreamSets Data Collector интегрирован со множеством распределенных систем, от файловых хранилищ до реляционных СУБД, включая NoSQL и системы управления очередями сообщений: HDFS, HBase, Hive, Cassandra, MongoDB, Apache Solr, Elasticsearch, Oracle, MS SQL Server, MySQL, PostgreSQL, Netezza, Teradata и другие реляционные СУБД с поддержкой JDBC, Apache Kafka, JMS, Kinesis, Amazon S3 и т.д. [4]. В отличие от Apache NiFi, управляемого потоковыми файлами (FileFlow), StreamSets Data Collector управляется записями, что обусловливает дальнейшую разницу в эксплуатации этих систем. Подробнее про сходства и различия Apache NiFi и StreamSets Data Collector читайте в нашей новой статье.
В практическом применении Fluentd часто используется как DevOps-инструмент и средство системного администрирования для сбора и анализа логов из множества распределенных приложений. Оно позволяет работать с контейнерами и системами управления контейнеризованными приложениями, в частности, Docker и Kubernetes. Это существенно облегчает процессы тестирования и развертывания в соответствии с методологией непрерывной интеграции и поставки программного обеспечения [5].
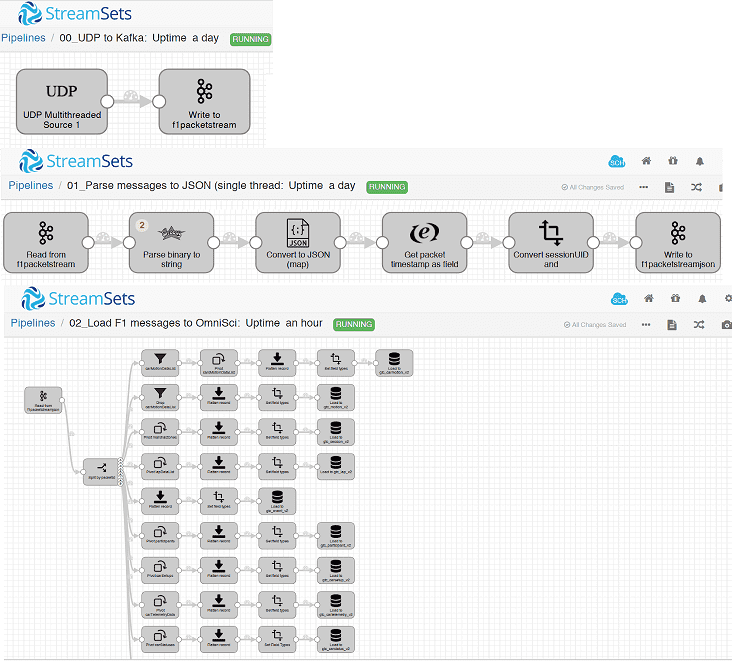
Из примеров практического использования StreamSets Data Collector отметим опыт американской компании OmniSci, которая разрабатывает программное обеспечение графических и центральных процессоров для визуализации больших данных. В частности, при создании реалистичных видеоигр по мотивам соревнований «Формула 1», с помощью StreamSets Data Collector был построен конвейер получения телеметрических данных о вождении автомобилей с периферийных IIoT-устройств, упаковка данных в UDP-пакет и непрерывная отправка информации в брокер сообщений Apache Kafka. Далее выполняется перевод двоичного потока в строки и конвертация в файл JSON, который дополняется временными метками и уникальным идентификатором сессии. Затем обогащенные данные снова записываются в кластер Kafka, откуда они расходятся по различным системам-приемникам: базам данных, BI-дэшбордам и т.д. Вся эта сложная схема маршрутизации телеметрических данных о движущемся автомобиле с целью их интерактивного отображения на визуальных панелях была построена в рамках StreamSets Data Collector [6].
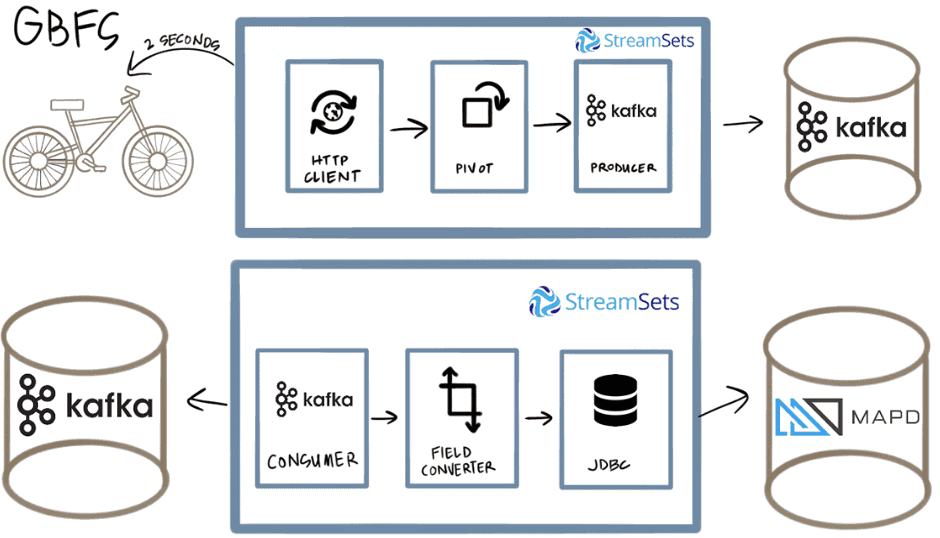
Аналогичным образом, в рамках IIoT-направления, разработчик распределенных решений One Click Retail использовала StreamSets Data Collector для чтения данных о локации и состоянии прокатных велосипедов Ford GoBike и отправки их в базу данных MapD через Kafka и JDBC-подключение [7].
Больше примеров практического использования StreamSets Data Collector, его сходства и отличия от Apache NiFi читайте в нашей следующей статье.
Освойте все тонкости установки, администрирования и эксплуатации потокового ETL в Big Data на нашем практическом курсе Кластер Apache NiFi в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- https://moluch.ru/archive/202/49512/
- https://www.dezyre.com/article/sqoop-vs-flume-battle-of-the-hadoop-etl-tools-/176
- https://blog.selectel.ru/sbor-i-analiz-logov-s-fluentd/
- https://github.com/streamsets/datacollector
- https://habr.com/ru/company/selectel/blog/250969/
- https://streamsets.com/blog/omnisci-f1-demo-real-time-data-ingestion-streamsets/
- https://streamsets.com/blog/real-time-bike-share-data-pipeline-streamsets-kafka-mapd/

