
В продолжение темы про проявление Agile-принципов в Big Data системах, сегодня мы рассмотрим, как DevOps-подход отражается в использовании Apache Kafka. Читайте в нашей статье про кластерную архитектуру коннекторов Кафка и KSQL – SQL-движка на основе API клиентской библиотеки Kafka Streams для аналитики больших данных, о которой мы рассказывали здесь. Из...

Мы уже рассказывали, как некоторые принципы Agile отражаются в Big Data системах. Сегодня рассмотрим это подробнее на примере коннекторов Кафка и KSQL – SQL-движка для Apache Kafka. Он который базируется на API клиентской библиотеки для разработки распределенных приложений с потоковыми данными Kafka Streams и позволяет обрабатывать данные в режиме реального...

Продолжая разговор про интеграцию Elasticsearch с Кафка, сегодня мы рассмотрим, с какими ошибками можно столкнуться при практическом использовании Apache Kafka Connect. Также рассмотрим, как Kafka Connect поддерживает обработку ошибок и какие параметры нужно настроить для непрерывной передачи данных или ее остановки в случае сбоя. 2 варианта обработки ошибок в Kafka...

Сегодня поговорим, как связать Elasticsearch с Apache Kafka: рассмотрим, зачем нужны коннекторы, когда их следует использовать и какие особенности популярных в Big Data форматов JSON и AVRO стоит при этом учитывать. Также читайте в нашей статье, что такое Logstash Shipper, чем он отличается от FileBeat и при чем тут Kafka...

Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную...

Вчера мы рассматривали интеграцию ClickHouse с Apache Kafka с помощью встроенного движка. Сегодня поговорим про проблемы, которые могут возникнуть при его практическом использовании и разберем способы их решения для корректной связи этих Big Data систем. Почему случаются тайм-ауты: многопоточность и безопасность Напомним, интеграцию ClickHouse и Kafka обеспечивает встроенный движок (engine),...

В этой статье рассмотрим интеграцию ClickHouse с Apache Kafka: когда и зачем она нужна, как связать эти две Big Data системы, каковы ограничения и недостатки существующих способов и каким образом их можно обойти. Также разберем, почему кластер Кликхаус использует Zookeeper и что такое материализованное представление таблицы Кафка. Big Data маркетинг,...

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...
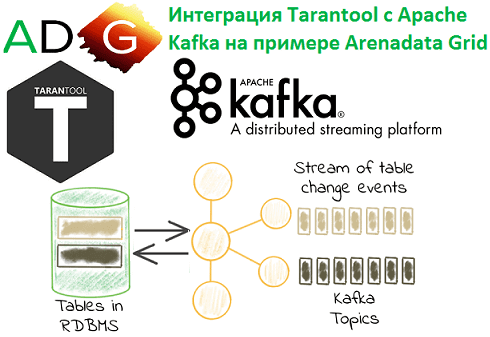
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...