 628
628 
Содержание
Продолжая разговор про интеграцию Elasticsearch с Кафка, сегодня мы рассмотрим, с какими ошибками можно столкнуться при практическом использовании Apache Kafka Connect. Также рассмотрим, как Kafka Connect поддерживает обработку ошибок и какие параметры нужно настроить для непрерывной передачи данных или ее остановки в случае сбоя.
2 варианта обработки ошибок в Kafka Connect
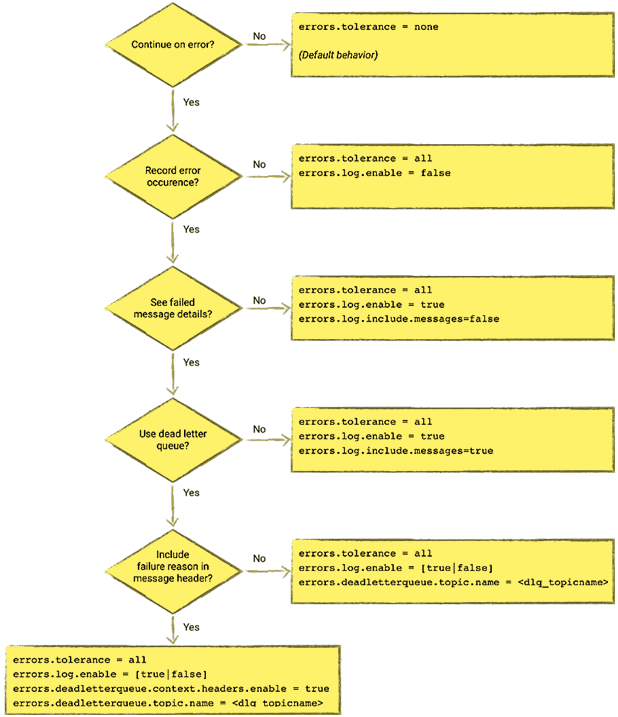
Начнем с того, как Kafka Connect поддерживает обработку ошибок при передаче данных, например, если сообщение в топике не соответствует заданному формату: JSON вместо AVRO, и наоборот. Kafka Connect включает опции обработки ошибок, в том числе отправку недоставленных сообщений в очередь. При этом возможны 2 варианта развития событий [1]:
- Высокая чувствительность к любым ошибочным сообщениям, когда они являются неожиданными и указывают на серьезную проблему в потоке данных. По умолчанию в этом случае Kafka Connect останавливает обработку данных. Это поведение задается настройкой tolerance = none в конфигурации коннектора.
- Низкая чувствительность к ошибкам, например, при передаче данных в хранилище для анализа или обработки с низкой критичностью к некорректным сообщениям. В этом случае параметр толерантности к ошибкам устанавливается так: tolerance = all. При обнаружении некорректного сообщения конвейер данных не остановится, а продолжит работу по передаче данных.
Максимально разрешающая конфигурация с низкой чувствительность к ошибкам задается следующими параметрами коннектора [2]:
- tolerance = all,
- log.enable = true,
- log.include.messages = true,
- on.malformed.documents = warn
Далее рассмотрим 10 самых распространенных ошибок при интеграции Elasticsearch с Кафка с помощью Kafka Connect.
ТОП-10 ошибок при передаче данных между Elasticsearch с Кафка
На практике при использовании Kafka Connect для интеграции с Elasticsearch наиболее часто случаются следующие ошибки [2]:
- тип поля считается как метаданные из-за некорректного наименования поля в сообщении Кафка – имеются символы _type. Уведомление об ошибке будет выглядеть так:
org.apache.kafka.connect.errors.ConnectException: Bulk request failed: [{«type»:»mapper_parsing_exception»,»reason»:»Field [_type] is a metadata field and cannot be added inside a document. Use the index API request parameters.»}]
Следует удалить или переименовать поле, например, с преобразованием одного сообщения или в источнике
- отказ от обновления маппинга, поскольку окончательное отображение имеется более 1 типа. Пример предупреждения об ошибки:
WARN Encountered an illegal document error when executing batch 4 of 1 records. Ignoring and will not index record. Error was [{«type»:»illegal_argument_exception»,»reason»:»Rejecting mapping update to [sample_topic] as the final mapping would have more than 1 type: [_doc, foo]»}] (io.confluent.connect.elasticsearch.bulk.BulkProcessor)`
Это происходит из-за того, что индекс Elasticsearch уже существует с другим типом в отображении или есть шаблон с динамическим отображением, где указано type.name. Для исправления ошибки следует удалить « type.name «:» « или использовать уже существующий тип – в примере это _doc.
- тип проверки (валидации) отсутствует. Ошибка: apache.kafka.connect.errors.ConnectException: Bulk request failed: {«root_cause»:[{«type»:»action_request_validation_exception»,»reason»:»Validation Failed: 1: type is missing;2: type is missing;3: type is missing;4: type is missing;5: type is missing;»}],»type»:»action_request_validation_exception»,»reason»:»Validation Failed: 1: type is missing;2: type is missing;3: type is missing;4: type is missing;5: type is missing;»}.
Такое случается из-за использования пустого type.name в конфигурации Kafka Connect при индексации для Elasticsearch с параметром schemas.ignore = false. Проблема решается с помощью задания имени type.name в конфигурации коннектора Кафка.
- Задача прекращается и не восстанавливается автоматически, требуется ручной перезапуск. Сообщение об ошибке:
Task threw an uncaught and unrecoverable exception
org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
Task is being killed and will not recover until manually restarted
Таким образом фреймворк коннектора Кафка регистрирует сбой. Необходимо внимательно изучить рабочие логи Kafka Connect, чтобы найти фактическую ошибку, зарегистрированную этой задачей.
- java.io.CharConversionException: Invalid UTF-32 character, что случается при использовании JSON-конвертера (org.apache.kafka.connect.json.JsonConverter) для чтения данных в формате AVRO. Следует использовать AVRO-конвертер (io.confluent.connect.avro.AvroConverter)
Напомним, коннектор Кафка имеет два десериализатора: ключ (key) и значение (value), для каждого из которых используются разные форматы сериализации. Например, данные из KSQL могут иметь ключ String и ключ AVRO.
- Error deserializing Avro message for id -1 Unknown magic byte! – эта ошибка аналогична предыдущей и возникает по причине применения неверных конвертеров – AVRO (io.confluent.connect.avro.AvroConverter) для чтения JSON-данных.
org.apache.kafka.connect.errors.DataException: Failed to deserialize data for topic sample_topic to Avro:
org.apache.kafka.common.errors.SerializationException: Error deserializing Avro message for id -1
org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
Следует использовать JSON-конвертер (org.apache.kafka.connect.json.JsonConverter)
- невозможно определить отображение без схемы из-за попытки использовать бессхемный формат данных с параметром ignore = false
org.apache.kafka.connect.errors.DataException: Cannot infer mapping without schema
Следует использовать Avro или JSON со встроенной схемой и конвертером Kafka Connect, настроенным на его ожидание. Также возможно применить KSQL для повторной сериализации топика в Avro. Наконец, можно самостоятельно задать нужную структуру JSON и задать настройку value.converter.schemas.enable = true.
- JSON-конвертер требует полей «schema» и «payload» при установленном параметре enable=true, но некорректной JSON-структуре.
Caused by: org.apache.kafka.connect.errors.DataException: JsonConverter with schemas.enable requires «schema» and «payload» fields and may not contain additional fields. If you are trying to deserialize plain JSON data, set schemas.enable=false in your converter configuration.
По аналогии с предыдущим случаем, следует использовать Avro или создать свой JSON со схемой в правильной структуре, установив value.converter.schemas.enable=false. Если не хочется заботиться о схеме, следует задать schema.ignore = true для коннектора Elasticsearch. Напомним, параметр schemas.enable – это конфигурация конвертера, которую можно задать для value.converter и для key.converter, решив эту проблему для обоих полей.
- Compressor detection can only be called on some xcontent bytes при попытке прочитать JSON-данные из топика с помощью конвертера строк (org.apache.kafka.connect.storage.StringConverter) с установленным параметром enable=true. Из-за этого Elasticsearch выдает ошибку, когда коннектор пытается проиндексировать данные:
Bulk request failed: [{«type»:»mapper_parsing_exception»,»reason»:»failed to parse»,»caused_by»:{«type»:»not_x_content_exception»,»reason»:»Compressor detection can only be called on some xcontent bytes or compressed xcontent bytes»}}] (io.confluent.connect.elasticsearch.bulk.BulkProcessor:393)
Проблема решается с помощью JSON-конвертера (org.apache.kafka.connect.json.JsonConverter), если в топике Кафка данные представлены в формате JSON. Например, это можно сделать так:
«value.converter»:»org.apache.kafka.connect.json.JsonConverter»
- Неподдерживаемые параметры корневого сопоставления: [type : text]. Это ошибка Elasticsearch, которая может возникнуть по разным причинам. Например, аналогично вышеописанному случаю при попытке прочитать JSON-данные из топика с помощью конвертера строк (apache.kafka.connect.storage.StringConverter) при установленном параметре параметром schemas.ignore=false.
Как и в предыдущей ситуации, проблема решается через применение JSON-конвертера для чтения данных в этом формате: «Value.converter»: «org.apache.kafka.connect.json.JsonConverter».
Тему коннекторов Кафка мы также рассматриваем здесь. А в следующей статье мы продолжим говорить про интеграцию Elasticsearch с другими Big Data системами и рассмотрим, как связать ES с компонентами экосистемы Apache Hadoop: Spark, Storm, Hive, HDFS и MapReduce. А как на практике организовать интеграцию Apache Kafka с внешними источниками для потоковой обработки больших данных, вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
Источники
- https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/
- https://rmoff.net/2019/10/07/kafka-connect-and-elasticsearch/

