 1209
1209 
Содержание
Сегодня поговорим, как связать Elasticsearch с Apache Kafka: рассмотрим, зачем нужны коннекторы, когда их следует использовать и какие особенности популярных в Big Data форматов JSON и AVRO стоит при этом учитывать. Также читайте в нашей статье, что такое Logstash Shipper, чем он отличается от FileBeat и при чем тут Kafka Connect.
Когда и зачем нужна интеграция Elasticsearch с Apache Kafka: 3 практических примера
Напомним, в ELK Stack компонент Logstash отвечает за сбор, преобразование и сохранение в общем хранилище данных из разных файлов, СУБД, логов и прочих мест в режиме реального времени. Это похоже на основное назначение Apache Kafka – распределенной стриминговой платформы, которая собирает и агрегирует большие данные разных форматов из множества источников. Возникает вопрос: зачем добавлять Kafka в ELK-стек, используя дополнительное средство сбора потоковых данных? Здесь можно выделить несколько сценариев [1]:
- временная остановка кластера Elasticsearch (ES) с целью обновления версии или внесения других изменений. Чтобы не потерять данные, приходящие из разных систем, Kafka можно использовать в качестве временного буфера для сохранения информации. Когда ELK-кластер возобновит работу, Logstash продолжит собирать, преобразовывать и отправлять в ES пропущенные данные, считывая их из топиков Apache Kafka с того места, где случился останов.
- Выравнивание пропускной способности компонентов ELK, чтобы, например, при внезапном увеличении объема данных ES-кластер не «захлебнулся» от высокой скорости поступления новой информации. На практике такая ситуация может возникнуть в случае ошибки в обновленном Big Data приложении или аномальном непредвиденном росте пользовательской активности.
Таким образом, добавление Кафка в Эластик-стек позволяет не зависеть от мониторинга событий. Совместное использование FileBeat с Kafka дает возможность создавать разные топики для каждого сервиса, улучшая «реактивность» всей Big Data системы. Напомним, FileBeat – это легковесный серверный агент для отправки определенных типов рабочих данных в Elasticsearch. Он занимает использует гораздо меньше системных ресурсов, чем Logstash. Хотя функциональные возможности Logstash по вводу, фильтрации и выводу для сбора, обогащения и преобразования данных из различных источников гораздо больше, чем у FileBeat. Можно сказать, что Logstash «дороже», чем FileBeat.
Возвращаясь к преимуществам включения Kafka в ELK Stack, отметим, что любая команда разработчиков или администраторов Big Data систем может подписаться на топики Kafka для сбора метрик или выдачи сигналов тревоги, уведомляющих о случившихся или потенциальных авариях. Это весьма востребована, поскольку на практике, в основном, Elasticsearch с Kibana используются для информирования, а не для оповещения или мониторинга [2].
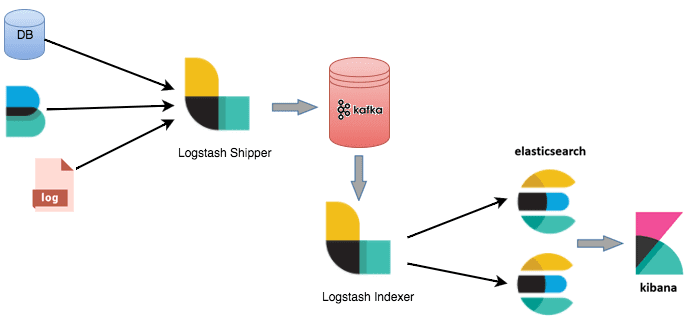
Например, в этом случае можно использовать 2 экземпляра Logstash – для отправки и индексации данных соответственно. Отправитель (Logstash Shipper) будет немедленно сохранять данные в топиках Кафка. А индексатор (Logstash Indexer) считывает из Кафка данные со своей собственной скоростью, выполняя при этом дорогостоящие преобразования, включая поиск и индексацию в Elasticsearch. Также FileBeat может отслеживать файлы и отправлять их в Kafka через приемник Logstash [1].
Что такое Kafka Connect и как это работает
Разумеется, есть еще множество других кейсов по совместному использованию Apache Kafka с компонентами ELK Stack. Причем Кафка также может выступать приемником данных из Elasticsearch. Для всех вариантов отлично подходит Kafka Connect – компонент Кафка, который обеспечивает потоковую интеграцию с внешними хранилищами данных, включая JDBC, Elasticsearch, IBM MQ, S3, BigQuery и другие. Наличие расширенного API позволяет дополнить Kafka Connect собственными коннекторами. А REST API облегчает их настройку и управления. Модульная природа Kafka Connect делает возможным гибко удовлетворить все интеграционные потребности [3]:
- коннекторы (connectors) – это файлы JAR, которые определяют, как интегрироваться с внешним хранилищем данных;
- конвертеры (converters) используются для сериализации и десериализации данных;
- преобразования (transforms) отвечают за дополнительную обработку сообщений «на лету».
Обычно для каждой внешней системы используются свой коннектор. В частности, за интеграцию Кафка с ELK отвечает коннектор Kafka Connect Elasticsearch. Он позволяет перемещать данные, записывая их из топика Кафка в индекс Elasticsearch с приведением к одному типу. Например, в кейсах по аналитике больших данных каждое сообщение в Кафка рассматривается как событие, которое коннектор идентифицирует по топику (topic), разделу (partition) и смещению (offset), чтобы преобразовать в уникальные ES-документы. При использовании Elasticsearch в качестве key-value хранилища ключи из сообщений Кафка будут идентификаторами ES-документов, гарантируя упорядоченное обновления. Оба рассмотренные варианта использования поддерживают идемпотентную семантику записи Elasticsearch, т.е. точно однократную доставку (exactly once). Подробнее о гарантиях доставки сообщений в Кафка мы рассказывали здесь.
Также стоит упомянуть про маппирование или отображение данных, которое определяет, как документ и содержащиеся в нем поля хранятся и индексируются в ES. Пользователи могут явно определять сопоставления типов в индексах. Если отображение не задано явно, Elasticsearch может определять имена и типы полей из данных. Однако такие типы, как метка времени (timestamp) и десятичная дробь, могут быть выведены некорректно. Kafka Connect Elasticsearch позволяет выводить сопоставления из схем сообщений Кафка. Таким образом, благодаря эволюционной поддержке схем данных, коннектор может обрабатывать изменения схемы в обратной, прямой и полностью совместимой конфигурации. В ряде случаев доступны некоторые несовместимые изменения схемы, например, конвертация поля из целого числа в строку [4].
5 особенностей интеграции ES с Кафка, о которых нужно знать
Следует помнить несколько важных моментов, при использовании Kafka Connect Elasticsearch [5]:
- данные сериализуются на основе значений по умолчанию, указанных в ваших worker’ах Kafka Connect, например, Avro. Если нужно что-то другое, следует вручную добавить переопределения.
- При передаче данных в Elasticsearch из KSQL (Kafka SQL), необходимо установить для преобразователя ключей значение STRING. Пока, все что относится к поддержке ключей выражается так: «Key.converter»: «org.apache.kafka.connect.storage.StringConverter»
- Коннектор автоматически изменяет имена топиков в верхнем регистре на имена индексов в нижнем регистре в Elasticsearch, вручную сопоставлять не нужно.
- Можно использовать регулярные выражения для сопоставления нескольких топиков, определив regex в конфигурации топика.
- отдельно стоит сказать про параметр ignore. Если он равен True, можно просто передать JSON-документ в Elasticsearch – сопоставление типов полей выполнится автоматически. Это актуально, если в данных отсутствует явная схема, например, формат JSON, CSV и пр. При использовании формата AVRO или JSON со встроенной схемой следует установить schema.ignore = false. Это позволит Kafka Connect явно создать сопоставление типов в Elasticsearch при предаче данных. На практике в большинстве случаев используется schema.ignore = true, что позволяет передать данные, не вдаваясь в технические подробности.
В следующей статье мы продолжим разговор про коннекторы Apache Kafka Connect и рассмотрим наиболее распространенные ошибки интеграции с Elasticsearch. А практические детали по связыванию Apache Kafka с другими внешними источниками для потоковой обработки больших данных вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
Источники
- https://www.elastic.co/blog/just-enough-kafka-for-the-elastic-stack-part1
- https://medium.com/inside-freenow/centralized-logs-with-elastic-stack-and-apache-kafka-7db576044fe7
- https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained/
- https://docs.confluent.io/current/connect/kafka-connect-elasticsearch/index/
- https://rmoff.net/2019/10/07/kafka-connect-and-elasticsearch/

