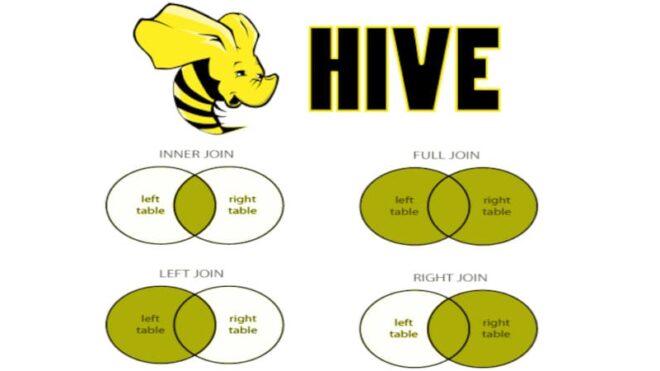
В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
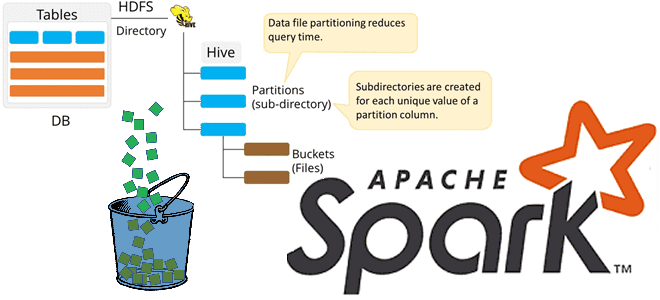
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

Сегодня в качестве пятничного развлечения для дата-инженеров, разработчиков распределенных приложений, администраторов, аналитиков и других специалистов по большим данным мы приготовили небольшой квиз по Apache Hadoop. Проверьте свое знание главной технологии Big Data, решив кроссворд, филворд и небольшой тест по основным компонентам и главным принципам работы этой платформы хранения и аналитики...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive. Что такое пользовательские функции...
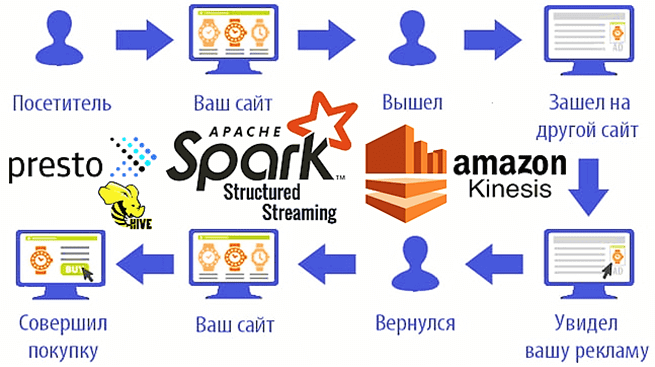
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

В прошлой статье мы рассматривали архитектуру Apache Hive и ее основные элементы. Сегодня поговорим про основные виды таблиц в Hive. Также подробно рассмотрим создание этих таблиц на практических примерах. Читайте далее про виды таблиц в Hive и их особенности. 2 основных вида таблиц для быстрой работы с большими данными в...

В этой статье мы поговорим про структуру системы управления базами данных (СУБД) Apache Hive. Также рассмотрим, какие базовые компоненты входят в структуру известной SQL-подобной СУБД, входящей в экосистему Hadoop. Читайте далее про основные компоненты структуры Apache Hive, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки больших...