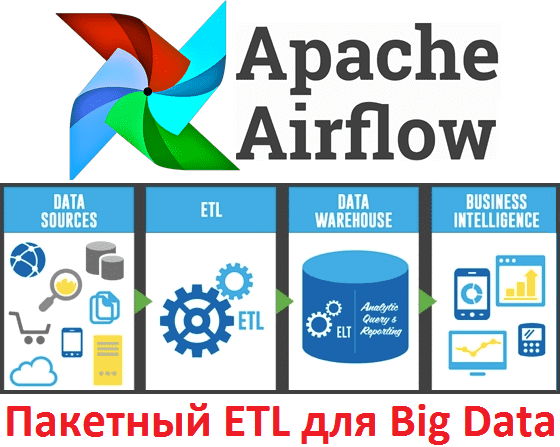
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...

Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala. Что такое RBAC для SQL-on-Hadoop...

Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...

В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop. Что общего между Apache Hive и Cloudera Impala:...

Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...
Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet...

Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...
В последних версиях Apache HIVE пытается внедрить CBO (cost based optimizer) и оптимизация операций JOIN одна из главных его составляющих. Поэтому понимание сценариев оптимизации применения операций JOINs (объединений) является одним из ключевых факторов настройки производительности HiveQL. Рассмотрим каждый вид объединений на практических примерах и определим их различия: Shuffle Join (Common...