 1077
1077 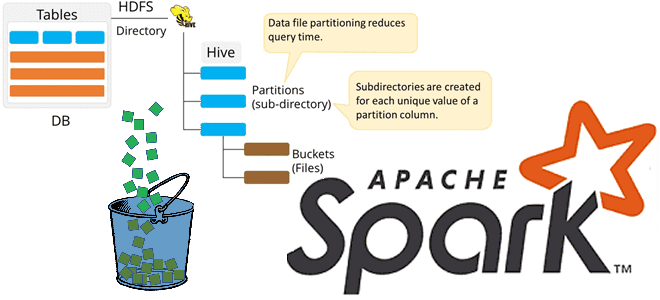
Содержание
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов.
Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark
Напомним, бакетирование ускоряет выполнение SQL-запросов, исключая рандомизацию при JOIN-соединениях и агрегациях за счет хранения данных в одних сегментах или столбцах кластеризации – бакетах (bucket). Apache Spark выполняет бакетирование таблиц в стиле Hive, разбивая разделы (partition) на бакеты [1]. Узнать, разделена ли таблица на бакеты и как, можно с помощью SQL-оператора spark.sql(«DESCRIBE EXTENDED table_name»).show(n=100). Аргумент n=100 добавлен в функцию show(), чтобы показать 100 первых строк таблицы, что актуально для больших таблиц, т.к. по умолчанию функция show() отображает только 20 строк. Конфигурация spark.conf.get(«spark.sql.sources.bucketing.enabled») используется для включения или отключения сегментирования.
Создать бакетированную таблицу можно следующим образом:
df.write\
.bucketBy(16, ‘key’) \
.sortBy(‘value’) \
.saveAsTable(‘bucketed’, format=’parquet’)
Команда bucketBy распределяет данные по фиксированному числу сегментов (в примере это 16) и используется, когда количество уникальных значений не ограничено. Иначе рекомендуется применять партиционирование таблиц – разбиение их записей на разделы, чтобы обрабатывать их параллельными и независимыми потоками [1].
При бакетировании таблиц в Apache Spark стоит помнить о следующих важных аспектах [2]:
- данные нужно сохранить в виде таблицы, т.к. необходимо хранить метаданные о сегментировании. Вызов saveAsTable() гарантирует, что метаданные сохранены в хранилище метаданных, например, в Apache Hive, откуда Spark возьмет информацию при доступе к таблице.
- вместе с методом bucketBy можно вызвать sortBy, который отсортирует каждый бакет по указанным полям. Однако, нельзя вызвать sortBy без вызова bucketBy.
- первый аргумент bucketBy — это количество сегментов, которые необходимо создать. При этом рекомендуется учитывать общий размер набора данных, а также количество и размер созданных файлов.
- Неаккуратное применение функции bucketBy() может привести к созданию слишком большого количества файлов, что потребует перераспределения DataFrame перед фактической записью.
Таким образом, основной проблемой на практике становится контроль количества создаваемых файлов, которые создает Spark для каждого бакета. Например, имеется набор данных 20 ГБ и 200 задач, каждая из которых обрабатывает примерно 100 МБ. Если данные в Spark-кластере распределены случайно, при создании 200 бакетов каждая из 200 задач будет нести данные для каждого из этих 200 сегментов, создавая 200 файлов. В итоге получится 40 000 маленьких файлов, а Apache Spark, как и другие технологии Big Data, ориентированы на обработку больших файлов. Решить эту проблему можно, обеспечив в вычислительно кластере распределение, аналогичное файловой системе хранилища данных. Если каждая задача имеет данные только для одного бакета, то она будет записывать только один файл. Впрочем, при бакетировании таблиц в Apache Spark дата-инженер может столкнуться с еще рядом сложностей, о которых мы поговорим далее.
Как разделить таблицу на оптимальное количество бакетов
Определение оптимального количества бакетов не просто, т.к. зависит от следующих факторов [2]:
- размер конечных сегментов, т.к. при считывании данных один сегмент обрабатывается одной задачей, у которой могут возникнуть проблемы с нехваткой памяти при большом размере бакета. В этом случае Spark будет перекидывать данные на диск во время выполнения, что снизит производительность. Чаще всего объема 150-200 МБ на бакет хватает, но точный размер каждого сегмента и их количество зависят от общего размера исходного набора данных.
- размер таблицы, которая постоянно растет со временем из-за добавления новых данных. Из-за этого также увеличивается размер бакетов. При равномерном распределении данных по разделам с учетом специфики запросов, например, если обычно нужны только данные за последние несколько месяцев, можно спроектировать сегменты так, чтобы их размер соответствовал этим данным. Общий размер бакета будет расти, но это не важно, т.к. он не запрашивается целиком. Но на практике чаще всего данные распределены неравномерно, когда для отдельного значения ключа сегментирования имеется намного больше записей, чем для других. Это приводит к перекосу данных и задача, которая будет обрабатывать большой сегмент, займет больше времени.
В заключение отметим, что бакетирование полезно при множественных соединениях и/или shuffle-преобразованиях с одним и тем же столбцом. Иначе этот метод оптимизации Spark SQL не принесет ощутимого эффекта [1].
Обычно, если таблицы разделены на одинаковое количество бакетов, бакетирование работает по умолчанию. Однако, на практике это не всегда так. Поэтому аналитику данных полезно знать некоторые подробности о таблице, чтобы ускорить выполнение запросов Spark SQL и понять возможности повышения производительности. Как это сделать, мы рассмотрим завтра.
Освойте все возможности Apache Spark для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники
- https://blog.clairvoyantsoft.com/bucketing-in-spark-878d2e02140f
- https://towardsdatascience.com/best-practices-for-bucketing-in-spark-sql-ea9f23f7dd53

