 1548
1548 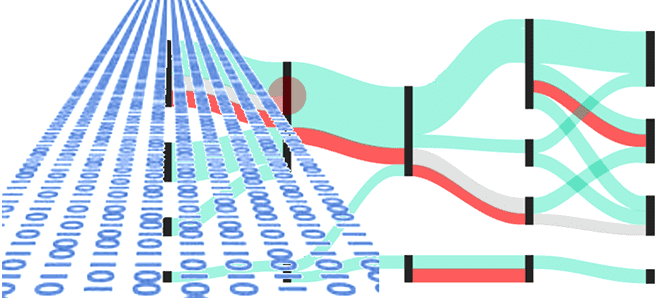
Содержание
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink.
Еще раз о разнице потоковой и пакетной парадигмы обработки данных
Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных. Они отличаются принципами работы и подходят для различных сценариев. Пакетная обработка автоматизируют повторяющиеся задачи, периодически обрабатывая большое количество записей в одном пакете за относительно длительный период, обычно измеряемый часами, днями или неделями.Ka
Типичное пакетное задание обрабатывает сохраненные данные и сохраняет результаты в базе данных, или в файле. Обновления или изменения применяются немедленно ко всем выбранным записям, файлам или байтам в пакете. Поэтому для пакетной парадигмы более важно эффективно управлять хранилищем данных, чем временем обработки, к которому предъявляются не очень жесткие требования. Чаще всего пакетное задание просто должно быть выполнено в течение установленного периода, например, ежедневные задания должны выполняться в течение 24 часов, а еженедельные не могут занимать больше недели. Помимо типовых бизнес-задач, например, формирование отчетов или вызов вычислений по конкретному датасету, пакетная обработка используется для сбора, компоновки и перемещения данных в ETL-процессах, в т.ч. внутри и между хранилищами облачных хранилищ.
Также задачи пакетной обработки могут использоваться вместе с окнами потоковых транзакций в гибридных конвейерах, которые выполняют внутреннюю сверку и при этом доставляют конечным пользователям обновления статуса в реальном времени. Например, онлайн-покупки, уведомления о статусах заказа или обновления складских запасов.
В отличие от пакетных систем, которые ждут сбора и компоновки данных перед их обработкой, системы потоковой обработки обрабатывают данные сразу после их создания, генерируя выходные данные в реальном времени. Потоковая обработка обрабатывает данные на лету по мере их поступления из различных внешних систем в режиме. В отличие от предсказуемых источников пакетных данных, потоковые данные поступают из меняющихся источников. Потоковые данные генерируются непрерывно, обычно в больших объемах и с высокой скоростью. Источник потоковых данных обычно состоит из непрерывных журналов с отметками времени, в которых фиксируются события по мере их возникновения. Например, события пользовательского поведения на сайте, изменения температуры в IoT-датчике, логи сервера, рекламных платформ в реальном времени, а также данных о потоках кликов из приложений и веб-сайтов.
Один источник потоковой передачи генерирует множество событий каждую минуту. В необработанном виде с этими данными очень сложно работать, поскольку отсутствие схемы и структуры затрудняет выполнение запросов с помощью аналитических инструментов на основе SQL. Поэтому нужна предварительная подготовка данных к анализу.
Пакетная обработка проще потоковой и более эффективна с точки зрения масштабирования, сохранности и точного анализа данных. Также пакетная парадигма позволяет лучше утилизировать вычислительные ресурсы, выполняя сложные операции в запланированное время, например, при невысокой нагрузке без дополнительного административного вмешательства. Однако, пакетная обработка большого объема данных выполняется достаточно медленно и может стать причиной отказа при интенсивных вычислениях.
Эти проблемы решает потоковая обработка с вычислениями в реальном времени. Однако, эта парадигма сложнее в проектировании и реализации, а также чревата потерями данных, которые не обработаны в заданных границах. Кроме того, сложность и точность потоковых вычислений намного меньше, чем при пакетной обработке. Потоковая передача отлично реализует параллелизм. Пакетная обработка может обрабатывать несколько источников данных, но не одновременно. Также пакетная парадигма предполагает однородные и конечные данные.
На практике пакетная и потоковая обработка часто дополняют друг друга и могут сочетаться в одном решении. Например, потоковая обработка для сбора данных о покупках в реальном времени вместе с пакетными операциями управления запасами в ночное время и проведения ежемесячных счетов. О сложностях проектирования и реализации такой архитектуры данных читайте в нашей новой статье, а пока, вспомнив разницу пакетной и потоковой парадигмы, далее рассмотрим, какие модели обработки данных в реальном времени сегодня существуют и как они реализуются.
4 модели потоковой парадигмы обработки данных
Начнем с синхронной микропакетной обработки. Этот способ знаком большинству дата-инженеров. Например, нужно запускать вычисления с данными, накопленными за последний час. Это и есть пакет. Микропакетный подход разделит этот часовой диапазон на несколько меньших, что дает следующие преимущества:
- данные в каждой микропакетной единице будут обработаны быстрее благодаря меньшему размеру;
- сокращаются нагрузки на потребление вычислительных ресурсов, поскольку данные обрабатывается постепенно, небольшими порциями;
- снижается задержка, поскольку обработка принимает данные почти сразу по их прибытии, в зависимости от продолжительности микропакета.
Однако, микропакетная модель сталкивается с проблемой неравномерности данных. Если одна задача в микропакете должна обработать больше данных, чем другие, она заблокирует обработку и увеличит общую задержку, даже если другие задачи выполняются быстро. Также микропакетная обработка имеет задержку, поскольку запускается периодически и обрабатывает все данные, накопленные за этот период. Такой подход реализован в Apache Spark Streaming.
Впрочем, микропакетная обработка может быть и асинхронной. Это решает проблему неравномерности данных, т.к. триггерный механизм основан на задачах, а не на жестко заданном расписании. Это означает, что каждый микропакет по-прежнему будет обрабатывать большое количество записей, но они не обязательно начнутся одновременно. Поэтому задача с перекосом данных будет иметь большую задержку, а другие — нет. Поскольку задачи изолированы, реализовать согласованное агрегирование для асинхронных микропакетов сложнее, чем в синхронной версии. Подобный подход есть в Apache Spark Structured Streaming.
Асинхронная микропакетная обработка отличается от streaming-модели, где поток определяются как граф операторов, который представляет данные, поступающие от источников к приемникам. В отличие от микропакетов, в потоке данных задачи полностью изолированы друг от друга. Узлы графа потока данных не нужно синхронизировать, т.е. этап сопоставления (Map) из вычислительной модели MapReduce не будет обрабатывать несколько событий вместе, как это происходит в микропакете. Вместо этого он обрабатывает каждую запись и передает ее следующему оператору как можно скорее. Сразу после этого он начинает обработку следующей записи и так далее, и так далее. Если какую-то запись невозможно обработать, она не перейдет к следующему оператору. Например, именно так работает Apache Flink и Dataflow в Google Cloud Platform. В частности, программы Flink параллельны и распределены. Во время выполнения поток имеет один или несколько разделов, и каждый оператор имеет одну или несколько подзадач оператора. Подзадачи оператора независимы друг от друга и выполняются в разных потоках, возможно, на разных машинах или контейнерах. Количество подзадач оператора определяется параллелизмом этого конкретного оператора. Разные операторы одной и той же программы могут иметь разные уровни параллелизма. Это еще одна из причин, почему Flink-приложения работают быстрее Spark, о чем мы писали здесь.
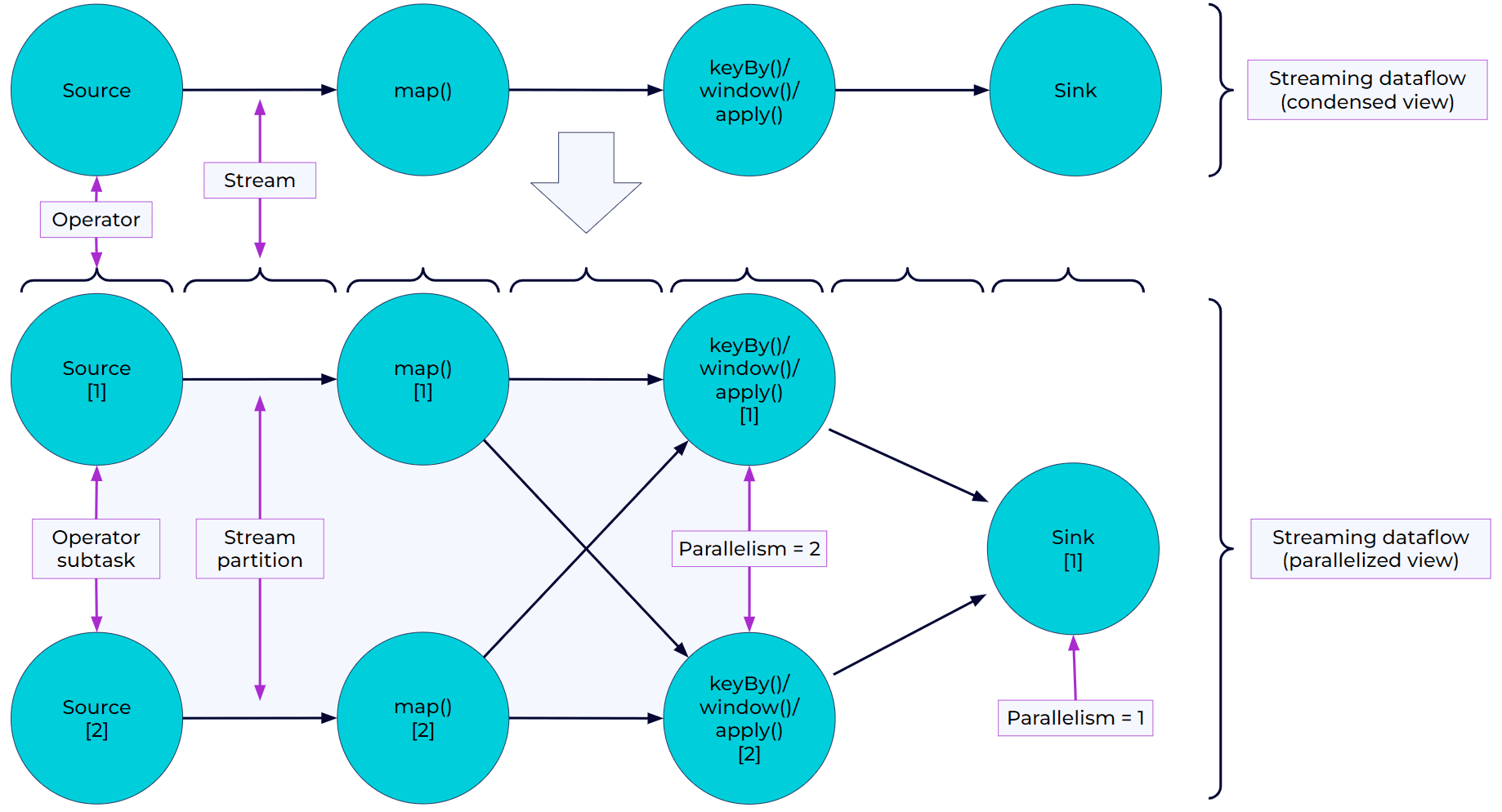
Потоки могут передавать данные между двумя операторами по следующим шаблонам:
- один к одному (one-to-one), например, между операторами Source и map(), где сохраняется разделение и порядок элементов. Это означает, что подзадача[1] оператора map() будет видеть те же элементы в том же порядке, в котором они были созданы подзадачой[1] оператора Source.
- перераспределение потоков (Redistributing), как между map() и keyBy/window, а также между keyBy/window и Sink. Это изменяет разделение потоков: каждая подзадача оператора отправляет данные различным целевым подзадачам в зависимости от выбранного преобразования. В частности, оператор keyBy(), который перераспределяет путем хеширования ключа, Broadcast() или rebalance(), который перераспределяет данные в случайном порядке. При перераспределяющем обмене порядок элементов сохраняется только внутри каждой пары подзадач отправки и получения: подзадача[1] функции map() и подзадача[2] функции keyBy/window. Перераспределение между операторами keyBy/window и Sink вносит недетерминированность в отношении порядка, в котором агрегированные результаты для разных ключей поступают в Sink.
Streaming-модель рассматривает потоковые ресурсы данных, такие как окна, как завершенные в какой-то момент. За определение этого момента отвечает водяной знак (watermark), решая, следует ли закрывать окно для задачи. Это означает, что ни больше, ни меньше, чем очень поздние записи не будут интегрированы в окно. Однако, для большинства потоковых приложений очень важно иметь возможность повторно обрабатывать исторические данные с помощью того же кода, который используется для обработки данных в реальном времени, и независимо от этого получать детерминированные, согласованные результаты. Поэтому появилась модель непрерывного обновления, которая не считает потоковые ресурсы завершенными и всегда обновляет их, даже если события действительно устарели относительно отметки времени водяного знака. Модель непрерывного обновления рассматривается в этом случае как поток изменений, где каждое изменение обновляет состояние вычислений над данными.
Такая модель имеет возможность сброса состояния, например, для обработки сценариев оповещения, когда предупреждение будет срабатывать всякий раз при первом выполнении условия. Без возможности сброса оно бы срабатывало для всех последующих событий, даже если они происходят на день позже и не должны рассматриваться как тревожные. Именно так работает топология приложения Kafka Streams.
Узнайте больше про архитектуры данных и технологии их потоковой обработки на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Практическая архитектура данных
- Потоковая обработка в Apache Spark
- Потоковая обработка данных с помощью Apache Flink
- Apache Kafka для инженеров данных
Источники
- https://www.ververica.com/blog/batch-processing-vs-stream-processing
- https://www.upsolver.com/blog/streaming-data-architecture-key-components
- https://www.ververica.com/what-is-stream-processing
- https://www.waitingforcode.com/data-engineering-patterns/stream-processing-models/read
- https://docs.confluent.io/cloud/current/flink/concepts/overview/

