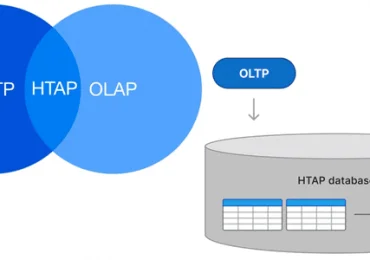
В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно представляет собой это внешнее хранилище для Apache Hive, зачем оно нужно и как его настроить.
Роль Apache Hive в экосистеме Hadoop и особенности версии Arenadata
Apache Hive считается одним из самых популярных инструментов SQL-on-Hadoop, позволяя анализировать данных в Hadoop HDFS с помощью SQL-подобного языка структурированных запросов HiveQL (HQL). Однако, Hive не очень подходит для анализа и транзакций в реальном времени из-за пакетного характера вычислений. Чтобы сопоставить схемы таблиц и баз данных с информацией в HDFS, Хайв использует хранилище метаданных (MetaStore). Этот принцип также применяется в универсальном SQL-движке Trino, о котором мы рассказываем здесь.
Хранилище метаданных Хайв отвечает за хранение всех метаданных о таблицах базы данных в Presto и Hive. По умолчанию MetaStore хранит эту информацию в локальной встроенной базе данных Derby на постоянном томе. Эта конфигурация по умолчанию работает для небольших кластеров. Поэтому для повышения производительности в качестве базы данных Hive Metastore на практике часто используется объектно-ориентированная СУБД PostgreSQL [1].
Кроме того, наличие внешней базы данных обеспечивает постоянство метаданных Хайв для распределенных приложений и заданий. А также является средством обмена таблицами Spark между разными платформами этого фреймворка [2].
Код курса
HIVE
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Именно поэтому разработчики Arenadata Hadoop включили в новый релиз этого продукта External PostgreSQL для Hive Metastore, чтобы позволить всем версиям Spark обмениваться данными друг с другом. В Arenadata Hadoop 2.1.4 помимо Spark 2.x включен свежий выпуск этого фреймворка – 3.1, о котором мы писали здесь. Хотя в Arenadata Hadoop обе версии Spark работают независимо друг от друга, может возникнуть потребность в интеграции данными между ними. За это и отвечает внешняя база данных PostgreSQL для хранилища метаданных Hive [3].
Такое решение упрощает установку и администрирование экосистемы Hadoop, облегчая переход со встроенной базы данных Derby, которая не подходит для больших систем, на PostgreSQL, широко распространенную в крупных проектах. На практике прежде чем запустить хранилище метаданных Хайв с внешней СУБД PostgreSQL, Hadoop-администратор должен выполнить целый ряд действий:
- настроить драйвер JDBC для удаленной базы данных PostgreSQL;
- настроить исходную схему базы данных;
- настроить учетную запись пользователя PostgreSQL для пользователя Хайв.
В результате получится примерно следующий файл конфигурации [4]:
spec: hive: spec: metastore: storage: create: false config: db: url: "jdbc:postgresql://postgresql.example.com:5432/hive_metastore" driver: "org.postgresql.Driver" username: "REPLACEME" password: "REPLACEME"
Настройка внешней базы данных для хранилища метаданных Хайв важна, поскольку с ней напрямую взаимодействует Apache Spark, что мы подробнее рассмотрим далее.
Зачем Spark-разработчику внешняя база данных для хранилища метаданных Хайв
Spark SQL поддерживает чтение и запись данных в Хайв. Spark SQL использует его хранилище метаданных для управления метаданными постоянных реляционных сущностей (например, баз данных, таблиц, столбцов, разделов) в реляционной базе данных для более быстрого доступа. По умолчанию Spark SQL использует встроенный режим развертывания Hive Metastore с базой данных Apache Derby. Но если вместо Derby используется другая СУБД, например, PostgreSQL, это следует указать в свойствах конфигурации spark.sql.hive.metastore.
Начиная с версии 1.4.0, одну двоичную сборку Spark SQL можно использовать для работы с разными хранилищами метаданных Hive. Однако, поскольку Хайв имеет большое количество зависимостей, эти зависимости не включены в дистрибутив Spark по умолчанию. Если эти зависимости можно найти в пути к классам, Spark загрузит их автоматически. Важно, что все эти зависимости также должны присутствовать на каждом рабочем узле кластера, поскольку им потребуется доступ к библиотекам сериализации и десериализации (SerDe), чтобы получить данные из этой NoSQL-СУБД.
Когда SparkSession создается с поддержкой Хайв, внешний каталог хранилища метаданных HiveExternalCatalog использует директорию spark.sql.warehouse.dir для размещения баз данных и свойства javax.jdo.option для подключения к базе данных ханилища метаданных Хайв. Поэтому, чтобы использовать внешнее хранилище метаданных, следует включить его поддержку в SparkSession, указать нужные классы в CLASSPATH и установить для свойства внутренней конфигурации spark.sql.catalogImplementation значение hive.
Определить hive.metastore.warehouse.dir следует в ресурсе конфигурации hive-site.xml. При отсутствии этого, SparkSession автоматически создает metastore_db в текущем каталоге запущенного Spark-приложения. Главными преимуществами использования внешнего хранилища метаданных Hive для разработчиков Spark являются следующие [6]:
- возможность одновременного доступа нескольких приложений или сеансов;
- одно Spark-приложение может использовать статистику таблицы без запуска команды «ANALYZE TABLE» при каждом выполнении.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
12 мая, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
Таким образом, возвращаясь к новому релизу российской платформы хранения и аналитики больших данных Arenadata Hadoop 2.1.4 с Apache Spark 3 и External PostgreSQL для Hive Metastore, можно сделать вывод, что этот выпуск позволит еще более эффективно работать с Big Data на корпоративном уровне. О проблемах очистки устаревших путей в Hive Metastore и способах их решения с Beekeeper читайте в нашей новой статье. А преимущества и перспективы этого хранилища метаданных смотрите здесь.
Основы Hadoop
Код курса
INTR
Ближайшая дата курса
по запросу
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Узнайте больше про администрирование и эксплуатацию Apache Hadoop и Hive для разработки распределенных приложений и аналитики больших данных в рамках Arenadata и не только на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
Источники
- https://docs.openshift.com/container-platform/4.6/metering/configuring_metering/metering-configure-hive-metastore.html
- https://docs.datamechanics.co/docs/creating-hive-metastore
- https://arenadata.tech/about/news/hadoop-spark-3-external-postgresql-for-hive-metastore/
- https://docs.openshift.com/container-platform/4.6/metering/configuring_metering/metering-configure-hive-metastore.html
- https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
- https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-hive-metastore.html