
Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15.
Проблема неравномерного распределения в Big Data вообще и в Apache Flink в частности
Неравномерное распределение данных по разделам снижает скорость их обработки: одни задачи становятся перегруженными, в то время как другие простаивают. Рассмотрим это на примере анализа данных о пользовательском поведении, включая события просмотра страниц, клики и т.д. Платформа анализирует эти данные и связывает их с профилями посетителей, отправляя этот обогащенный поток событий в топик Kafka с частотой около 3000 (с всплесками до 5000) событий в секунду. Необходимо в режиме реального времени отслеживать обновления данных по количеству активных пользователей, самым просматриваемым страницам и продолжительности пользовательских сеансов. При этом требовалось создавать метрики временных рядов с минутной детализацией и предоставить возможность просмотра/выборки сводных данных по сайтам и переменным временным окнам.
Основным вычислительным механизмом решения является управляемый кластер Flink от AWS Kinesis Data Analytics в качестве инструмента обработки потоков. Агрегированные результаты минутной детализации сохраняются в базе данных PostgreSQL. При этом во входящем потоке данных присутствует неизбежная асимметрия, которая влияет на производительность задания Apache Flink. Перекос данных относится к несбалансированному распределению набора данных относительно отдельного поля. Например, население России распределено крайне неравномерно: почти 70% жителей сосредоточено в европейской части России, которая составляет примерно 21% всей территории страны. Впрочем, большинству наборов данных присуща неизбежная асимметрия, ведь большинство людей действительно живут в больших городах. Но при параллельной обработке неравномерно распределенных данных возникает проблема, когда некоторые узлы будут перегружены вычислениями с огромными объемами данных, в то время как остальные будут фактически простаивать.
В рассматриваемом примере задание Flink для создания и хранения поминутных агрегаций, столкнулось именно с этой проблемой: поле агрегации данных сильно искажено, что снижало производительность при попытке ввода по нему. В качестве примера рассмотрим крупный интернет-магазин одежды, который представляет собой огромный маркетплейс, включая множество различных фронтов, каждый со своим собственным брендом и веб-сайтами. Все события, заказы и общий трафик данных перенаправляются в центральный топик Apache Kafka, данные откуда используются для анализа пользовательского поведения. Предположим, сообщение, отправляемое в топик Kafka, имеет следующий формат:
{
“typeOfEntity”: “EVENT”,
“typeOfEvent”: “VIEW”,
“site”: “mainstream.com”,
“page”: “/homepage”,
“guestID”: “<<UUID>>”,
“sessionID”: “<<UUID>>”,
“timestamp”: “2022–10–17 12:57:20”
}
Чтобы подсчитать количество просмотров каждого сайта в минуту в реальном времени, можно построить следующий ETL-конвейер Apache Flink:
val windowResult = env.addSource(source) .name(“Messages”) .map(Message.fromLine(_)) .filter(m => m.typeOfEntity == “EVENT” && m.typeOfEvent == “VIEW”) .name(“FilteredEvents”) .keyingBy(_.site) .window(TumblingEventTimeWindows.of(Time.minutes(1))) .aggregate(new AggregateViews) .name(“ViewEventsAggregation”)
Атрибут keyingBy использует поле сайт. При запуске этого ETL-конвейера в кластере Flink, сообщения отправляются в подзадачи асимметричным образом в соответствии с количеством событий, которые есть на каждом сайте. При этом большая часть сообщений поступает с более крупных сайтов всего за несколько подзадач, а остальные простаивают. Решить проблему такого дисбаланса можно с помощью статических или динамических весов, учитывая количество ожидаемых по каждому сайту сообщений.
{
“mainstream.com”: 500,
“niche1.com”: 20,
“niche2.com”: 15,
“niche3.com”: 12
}
Зная, насколько популярен каждый сайт, можно построить карту этих весов и использовать ее для повторной балансировки агрегации. При этом целесообразно применить прием добавления так называемой «соли» через функцию случайного хэширования, что будет включать веса и соединяться их в качестве нового значения атрибута keyingBy. Это позволит разделить датасеты по самым популярным сайтам на более мелкие фрагменты и обрабатывать их равномерно. Но если сайты локализованы в разных частях мира, то время суток активно влияет на их посещаемость и создает неравномерность. Поэтому вместо статических весов следует использовать динамические. Это влечет за собой сохранение относительного количества событий, полученных за последние несколько минут с каждого сайта, а затем использование этой информации для создания нового набора весов каждые X минут. Но это решение вызывает дополнительные накладные расходы, связанные вычислением весов. Поэтому можно уменьшить количество записей, отправляемых в оконную функцию, путем предварительной агрегации и соединения нескольких записей в одну. Это известный шаблон MapReduce Combiner, который часто используется в экосистеме Apache Hadoop. Как применить его к рассматриваемому случаю во Flink-заданиях, и почему вместо него лучше использовать Bundle оператор, мы рассмотрим далее.
Что такое MapReduce Combiner и чем полезен Bundle оператор
Итак, чтобы сократить объем вычислений, нужно соединить поступающие события в более мелкие фрагменты относительно количества просмотров, а затем отправить эти пакеты на последний этап агрегирования.
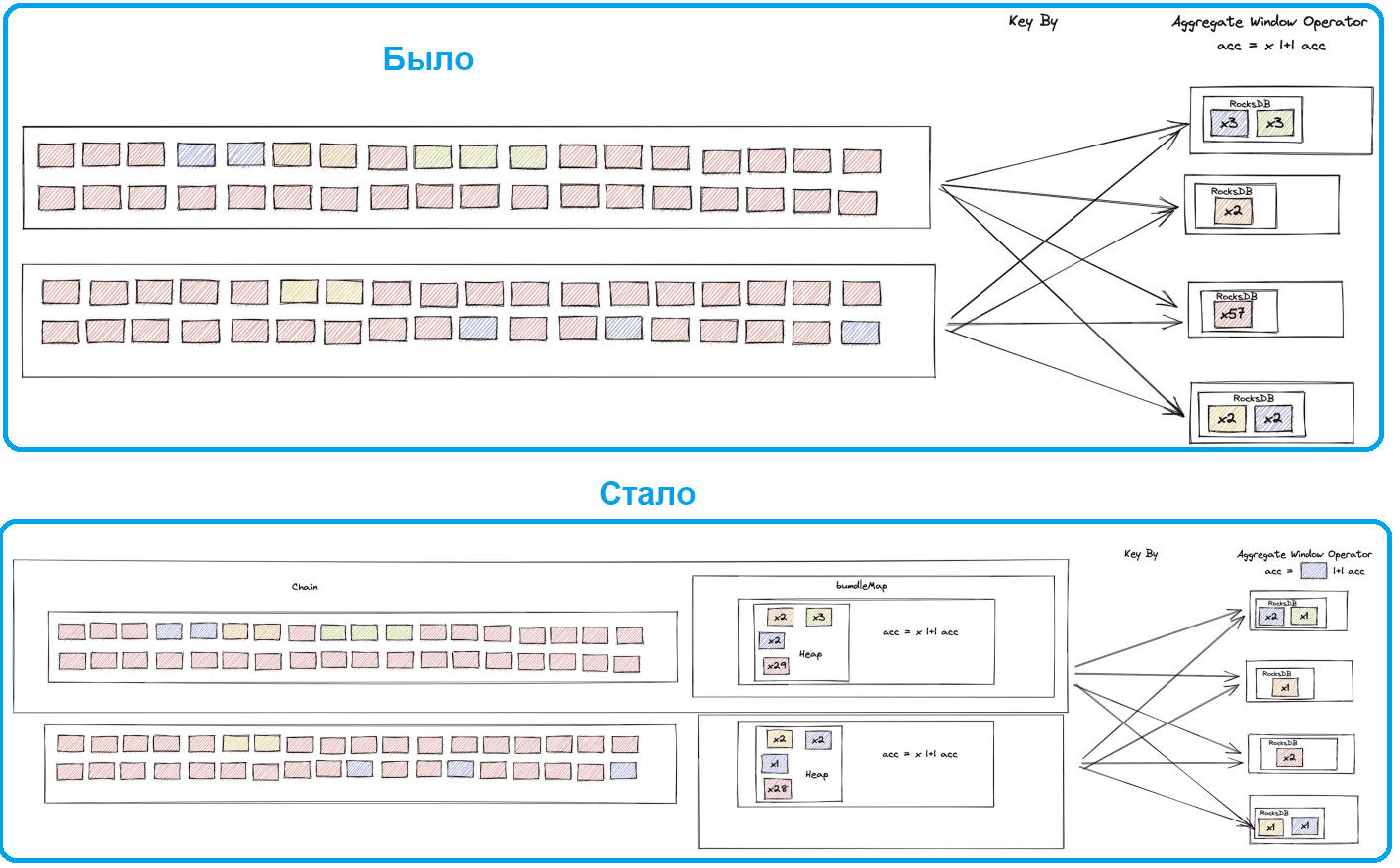
Самый прямой и интуитивно понятный способ реализовать эту идею сводится к написанию простой функции плоского сопоставления из шаблона MapReduce Combiner в качестве предварительной агрегации. Однако, это не учитывает водяные знаки, и к тому времени, когда предварительное соединение будет завершено, некоторые записи будут за пределами их временных окон и будут считаться опоздавшими событиями. Решить эту проблему позволит оператор Bundle, который есть в Apache Flink 1.15. Работа оператора Bundle заключается в накоплении значений в одну запись до тех пор, пока не будет выполнено условие закрытия пакета. Обычно это определенное количество записей, объединенных в пакет. Затем пакет отправляется во вторую агрегацию, которая вычисляет окончательные числа и отправляет результат в приемник, например, база данных PostgreSQL.
Таким образом, следует написать функцию, реализующую Bundle оператор, и добавить новый шаг в ETL-конвейер, который предварительно агрегирует записи с помощью этого метода.
val windowResult = env.addSource(source)
.name("Messages")
.map(Message.fromLine(_))
.filter(m => m.typeOfEntity == “EVENT” && m.typeOfEvent == “VIEW”)
.name("FilteredEvents")
.transform (
"PreAggregation",
new MapBundleOperator[(String, Instant), Int, Message, Message] (
new AggregateViewsBundleFunction,
new CountBundleTrigger(100),
new KeySelector[Message,(String, Instant)] {
override def getKey(in: Message) = (in.site, in.timestamp)
}
)
)
.keyingBy(_.site)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new AggregateViews)
.name("ViewEventsAggregation")
Шаг PreAgregation использует MapBundleOperator и MapBundleFunction:
class AggregateViewsBundleFunction extends MapBundleFunction[(String, Instant), Int, Message, Message] { override def addInput(value: Int, input: Message): Int = value + 1 override def finishBundle (
buffer: java.util.Map[(String, Instant), Int],
out: Collector[Message]
): Unit = {
val outputValues = buffer.asScala.map(Message.fromMap _)
.toSeq.sortBy(_.timestamp.toEpochMilli)(Ordering[Long].reverse)
outputValues.foreach(out.collect)
}
}
В ситуациях с низкой пропускной способностью ограничение записи для пакетов будет игнорироваться, поскольку окно водяных знаков (по умолчанию 200 мс) почти всегда будет закрываться первым и принудительно закрывать пакет. Оба этих параметра (ограничение пакета и окно водяных знаков) можно точно настроить. Таким образом, применение оператора Bundle в коде Flink приложения позволяет выровнять распределение нагрузки между подзадачами и повысить производительность, а также дает возможность управлять перекосом данных во всем наборе без ущерба для скорости обработки.
Еще одним преимуществом этого способа является его гибкость, поскольку он позволяет справиться с неожиданными всплесками неравномерной пропускной способности, например, крупная распродажа на одном из сайтов большого интернет-магазина.
О другом способе ускорить SQL-запросы с оператором JOIN к неравномерно распределенным данными в Apache Flink с помощью мини-пакетных агрегаций для потоковых таблиц, читайте в нашей новой статье. А о том, как ускорить выполнение распределенной программы, используя внутренний механизм спекулятивного выполнения пакетных заданий, вы узнаете здесь.
Освойте тонкости использования Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/@sanr_71172/dealing-with-data-skew-in-flink-b7e4c82c35ef
- https://data-flair.training/blog/hadoop-combiner-tutorial/

