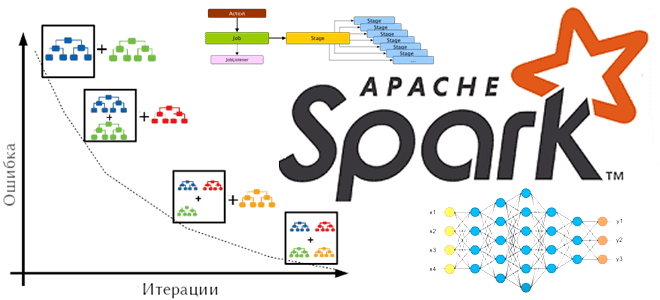
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
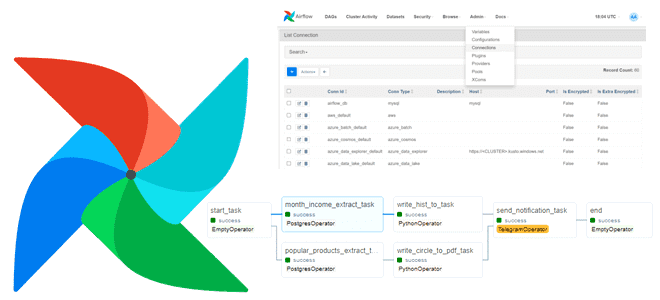
Сегодня на практическом примере посмотрим, как запускать в DAG Apache AirFlow параллельное исполнение нескольких задач, применим пару лучших практик реализации ETL-конвейера для работы с PostgreSQL, а также разберем неоднозначности программного добавления соединений с внешними системами. Постановка задачи Предположим, необходимо получить аналитику по продажам товаров интернет-магазина, выгрузив данные из PostgreSQL в...
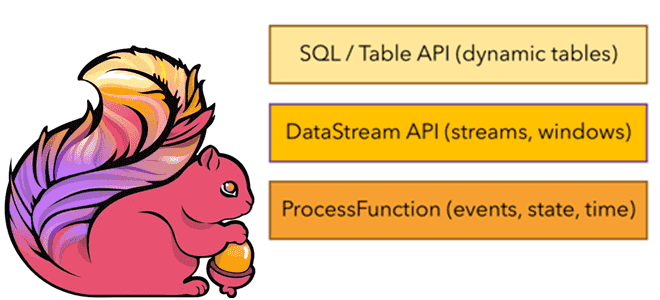
Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов. Потоковые примитивы и низкоуровневый API Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев. На...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
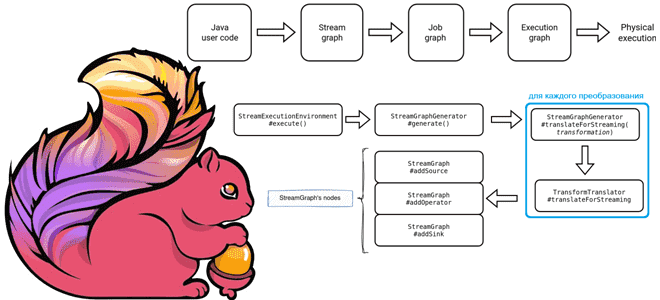
Как планируются и исполняются задания Apache Flink: от пользовательского Java-кода до физического исполнения, а также отслеживание статуса задания в JobManager. Подробности преобразований с примерами кода. 3 этапа преобразования задания Apache Flink Задание Apache Flink проходит несколько этапов перед своим физическим выполнением: сперва пользовательский код преобразуется в потоковый граф (Stream Graph);...
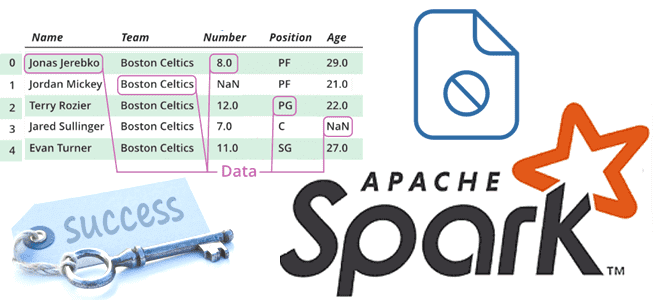
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab. Когда и зачем Spark-приложение создает файл _SUCCESS В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(),...
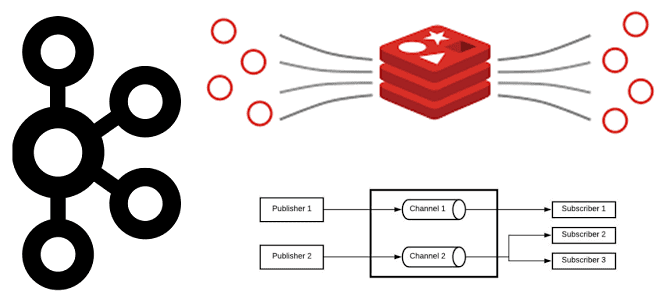
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...