 465
465 
Содержание
Сегодня на практическом примере посмотрим, как запускать в DAG Apache AirFlow параллельное исполнение нескольких задач, применим пару лучших практик реализации ETL-конвейера для работы с PostgreSQL, а также разберем неоднозначности программного добавления соединений с внешними системами.
Постановка задачи
Предположим, необходимо получить аналитику по продажам товаров интернет-магазина, выгрузив данные из PostgreSQL в виде табличных и графических PDF-отчетов. Пример простого Python-кода для этой задачи я показывала в блоге нашей Школы прикладного бизнес-анализа. Чтобы показать, как работает распараллеливание задач в рамках одного DAG Apache AirFlow, будем формировать 2 разных отчета: один с гистограммой распределения дохода по месяцам, а другой – по самым продаваемым товарам. После формирования обоих отчетов в Телеграм-бот должно приходить уведомление об успешном выполнении этих задач.
Как обычно, в качестве примера я возьму базу данных своего ранее спроектированного и реализованного интернет-магазина, которая имеет следующую схему для PostgreSQL

Итоговый отчет в виде неизменяемого PDF-файла должен содержать данные о помесячном доходе и количестве заказов, а также сведения о наиболее популярных, т.е. самых часто продаваемых товарах в текстовой и графической формах. Для визуализации помесячной выручки отлично подходят гистограммы, а для оценки популярности конкретного товара относительно других – круговая диаграмма. Все эти и другие виды графиков поддерживает Python-библиотека matplotlib. Помимо функций для работы с двумерной и трехмерной графикой, она также позволяет формировать PDF-документ с текстовыми, табличными, численными и графическими данными. Поэтому для решаемой задачи будем использовать именно ее методы API, формируя задачи для DAG AirFlow.
Реализация DAG AirFlow
Поскольку я запускаю AirFlow как Python-библиотеку в интерактивной среде Google Colab, сперва необходимо установить требуемые зависимости:
#Установка Apache Airflow и инициализация базы данных. !pip install apache-airflow !airflow initdb #Установка инструмента ngrok для создания безопасного туннеля для доступа к веб-интерфейсу Airflow из любого места !wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip !unzip ngrok-stable-linux-amd64.zip !pip install pyngrok #установка провайдеров !pip install apache-airflow-providers-telegram !pip install psycopg2-binary !pip install apache-airflow-providers-postgres #импорт модулей from pyngrok import ngrok import sys import os import json import datetime from airflow import DAG from airflow.providers.telegram.operators.telegram import TelegramOperator
Создадим директории, где будут храниться Python-файлы отдельных задач и SQL-запросов.
from google.colab import drive
drive.mount('/content/drive')
os.makedirs('/content/airflow/dags', exist_ok=True) #создание директории с py-файлами
os.makedirs('/content/airflow/files/reports', exist_ok=True) #создание директории с отчетами
os.makedirs('/content/airflow/sql', exist_ok=True) #создание директории с отчетами
dags_folder = os.path.join(os.path.expanduser("~"), "airflow", "dags")
os.makedirs(dags_folder, exist_ok=True)
os.makedirs("/root/airflow/dags/sql", exist_ok=True)
Далее запустим веб-сервер AirFlow
#запуска веб-сервера Apache Airflow на порту 8888. Веб-сервер Airflow предоставляет пользовательский интерфейс для управления DAGами, #просмотра логов выполнения задач, мониторинга прогресса выполнения !airflow webserver --port 8888 --daemon
Для доступа к веб-серверу AirFlow извне необходимо пробросить туннель для раскрытия порта, на котором он запущен. Как обычно, я делаю это с помощью утилиты ngrok:
#Аутентификация в сервисе ngrok с помощью auth_token
os.system(f"ngrok authtoken {auth_token}")
#Запуск ngrok, который создаст публичный URL для сервера через туннель
#для доступа к веб-интерфейсу Airflow из любого места.
#addr="8888" указывает на порт, на котором запущен веб-сервер Airflow, а proto="http" указывает на использование протокола HTTP
public_url = ngrok.connect(addr="8888", proto="http")
#Вывод публичного URL для доступа к веб-интерфейсу Airflow
print("Адрес Airflow GUI:", public_url)

Создадим пользователя AirFlow, задав ему логин и пароль:
!airflow db init #Инициализация базы данных Airflow !airflow upgradedb #Обновление базы данных Airflow #Создание нового пользователя в Apache Airflow с именем пользователя anna, именем Anna, фамилией Anna, адресом электронной почты anna.doe@example.com и паролем password. #Этот пользователь будет иметь роль Admin, которая дает полный доступ к интерфейсу Airflow. !airflow users create --username anna --firstname Anna --lastname Anna --email anna@example.com --role Admin --password password
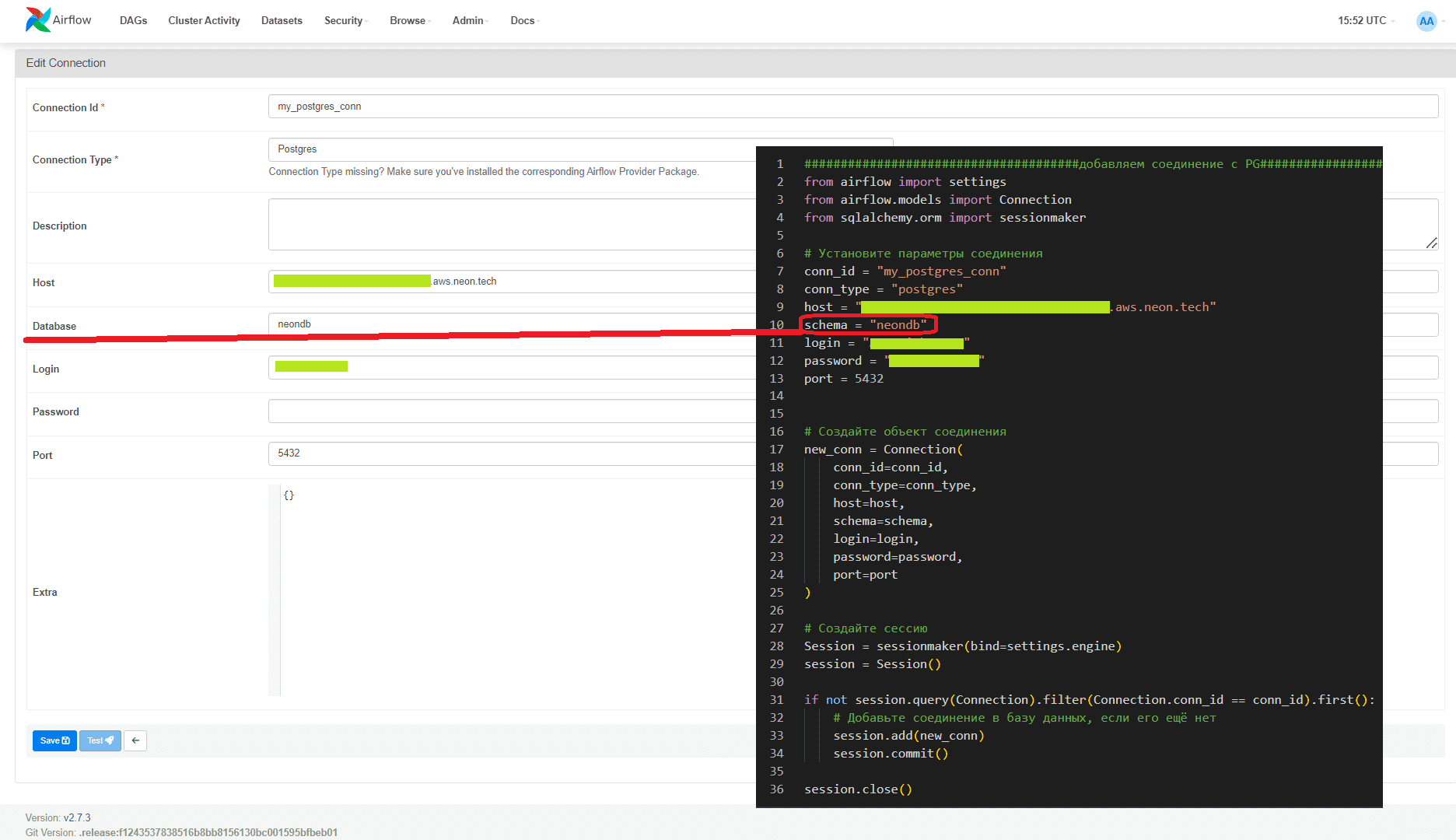
Поскольку указывать параметры подключения к внешним системам, таким как СУБД PostgreSQL или Telegram непосредственно в коде DAG считается плохой практикой, зададим это программным образом. Например, мой экземпляр PostgreSQL развернут в облачной платформе Neon:
######################################добавляем соединение с PG#################################
from airflow import settings
from airflow.models import Connection
from sqlalchemy.orm import sessionmaker
# Установите параметры соединения
conn_id = "my_postgres_conn"
conn_type = "postgres"
host = "my-v-host.aws.neon.tech"
schema = "neondb"
login = "username"
password = "password"
port = 5432
# Создайте объект соединения
new_conn = Connection(
conn_id=conn_id,
conn_type=conn_type,
host=host,
schema=schema,
login=login,
password=password,
port=port
)
# Создайте сессию
Session = sessionmaker(bind=settings.engine)
session = Session()
if not session.query(Connection).filter(Connection.conn_id == conn_id).first():
# Добавьте соединение в базу данных, если его ещё нет
session.add(new_conn)
session.commit()
session.close()
Примечательно, что при задании параметров соединения в ключе schema надо указать название БД, а не схему:
Аналогичным образом определим параметры подключения к TG-боту:
######################################добавляем соединение с TG#################################
from airflow import settings
from airflow.models import Connection
from sqlalchemy.orm import sessionmaker
# Создайте объект соединения
new_conn = Connection(
conn_id='my_TG_conn',
conn_type='http',
login='login',
password='API-token TG',
host='telegram_chat_id', # telegram_chat_id
schema='', # нет схемы
port=None, # нет порта
extra=json.dumps({"telegram_token": telegram_token, "telegram_chat_id": telegram_chat_id})
)
# Создайте сессию
Session = sessionmaker(bind=settings.engine)
session = Session()
# Используйте conn_id из объекта соединения для проверки
if not session.query(Connection).filter(Connection.conn_id == new_conn.conn_id).first():
# Добавьте соединение в базу данных, если его ещё нет
session.add(new_conn)
session.commit()
session.close()
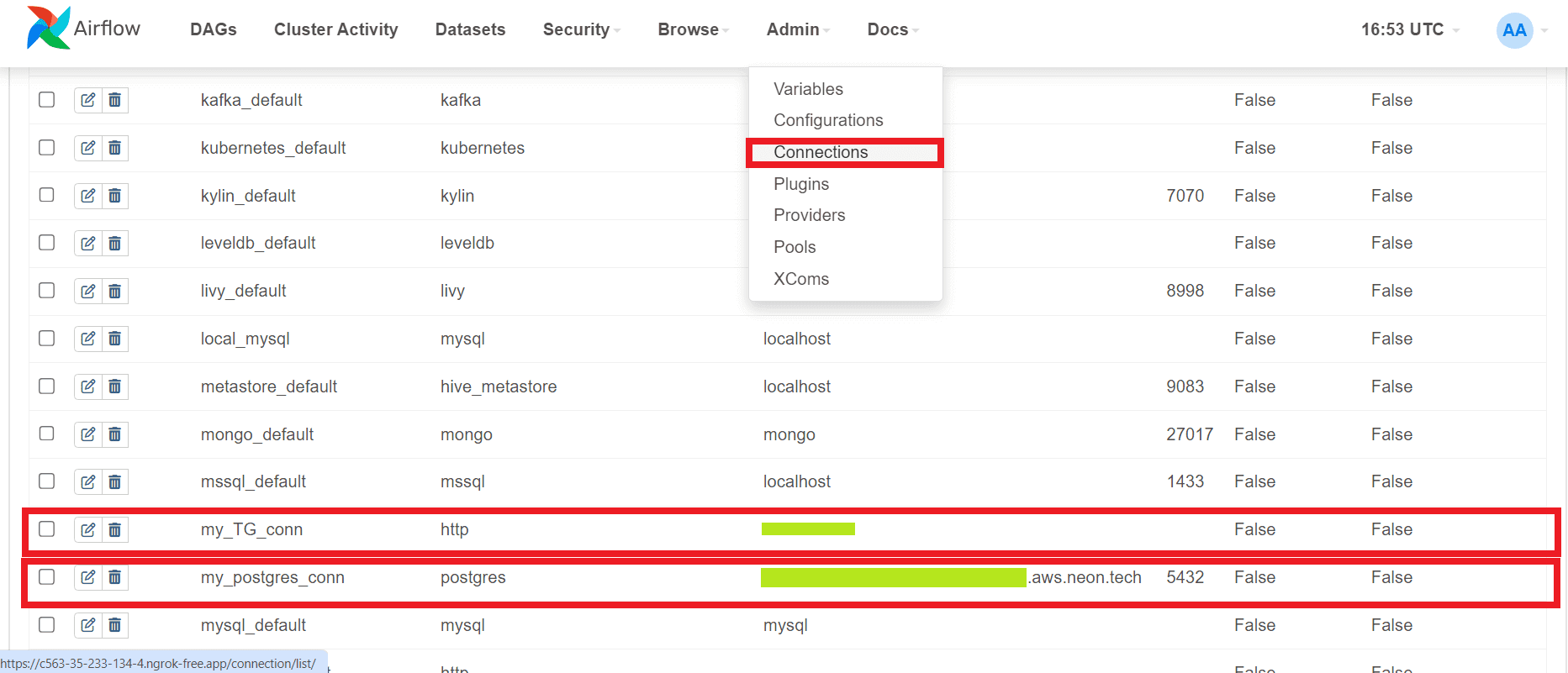
Созданные подключения отобразятся в GUI веб-сервера AirFlow:
Отмечу, что подключения рекомендуется задавать именно в Connections, а не в переменных, что рассматривается в новой статье. Аналогично подключениям, вписывать текст SQL-запроса непосредственно в Python-файл задачи DAG считается плохой практикой. Лучше описать его в отдельном sql-файле, который потом будет использоваться как параметр для задачи оператора PostgreSQL. Чтобы считать данные из файла с SQL-запросами, AirFlow должен иметь доступ к нему, т.е. файл должен размещаться в той же среде, где работает AirFlow и должен быть доступен для чтения. При использовании PostgresOperator и указания пути к файлу с SQL-запросом, AirFlow ожидает, что он будет находиться внутри директории dags или в папке, которая указана в настройках sql для Airflow. По умолчанию SQL-файлы ищутся в папке dags и подпапках. Поэтому будем сохранять их в ранее созданной директории /root/airflow/dags/sql:
Файл с SQL-запросом получения помесячной выручки из БД создается таким образом:
###################################SQL-запрос получения помесячной выручки из БД (сумма всех заказов, сгруппированных по месяцам)################
from google.colab import files
code = '''
SELECT to_char(orders.date, 'Month') AS mes, SUM(orders.sum) AS income, COUNT(orders.sum) AS quantity
FROM orders
GROUP BY mes
ORDER BY (MIN(orders.date));
'''
with open('/root/airflow/dags/sql/SQL-zapros_month_income.sql', 'w') as f:
f.write(code)
!cp ~/airflow/dags/sql/SQL-zapros_month_income.sql /content/airflow/sql/SQL-zapros_month_income.sql
Файл с SQL-запросом получения наиболее популярных товаров создается так:
###################################SQL-запрос получения больше всего востребованных товаров из БД
######################(тех товаров во всех заказах, которых купили больше 500 единиц)################
from google.colab import files
code = '''
SELECT product.name AS tovar, SUM(order_product.quantity) AS kolichestvo
FROM order_product
JOIN product on product.id=order_product.product
JOIN orders on orders.id=order_product.order
WHERE (EXTRACT(MONTH FROM orders.date) BETWEEN 1 AND 6)
GROUP BY tovar
HAVING SUM(order_product.quantity)>500
ORDER BY kolichestvo;
'''
with open('/root/airflow/dags/sql/SQL-zapros_popular_products.sql', 'w') as f:
f.write(code)
!cp ~/airflow/dags/sql/SQL-zapros_popular_products.sql /content/airflow/sql/SQL-zapros_popular_products.sql
Создадим Python-файл с задачей формирования гистрограммы по данным из SQL-запроса помесячной выручки:
############################задача формирования PDF-документа с гистограммой##################################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
import pandas as pd
import datetime
import os
def write_hist_to_pdf_function(**kwargs):
results = kwargs['ti'].xcom_pull(task_ids='month_income_extract_task')
for result in results:
df = pd.DataFrame(results, columns=['МЕСЯЦ', 'ДОХОД', 'КОЛИЧЕСТВО ЗАКАЗОВ'])
# Получаем текущую дату
current_date = datetime.datetime.now()
# Форматируем дату в строку (например, '2023-03-15')
date_str = current_date.strftime('%Y-%m-%d')
filename = '/content/airflow/files/HIST_report_' + date_str + '.pdf'
with PdfPages(filename) as pdf:
fig_table, ax_table = plt.subplots(figsize=(6, 10)) # Выберите подходящий размер фигуры
# Задание заголовка
ax_table.set_title(f"Доходы по месяцам")
# Задание содержимого таблицы со статистикой
ax_table.axis('tight') # задаем границы области для таблицы так, чтобы они плотно обрамляли содержимое
ax_table.axis('off') # выключаем отображение осей для таблицы (нет границ и делений)
table = ax_table.table(cellText=df.values, colLabels=df.columns, loc='center') #задаем содержимое ячеек таблицы, заголовки столбцов и расположение таблицы
table.set_fontsize(10) # устанавливаем размер шрифта для текста в таблице вручную
table.scale(1.2, 1.2) # Можно изменить масштаб таблицы для лучшего отображения
# Сохранение в pdf и закрытие страницы в файле, чтобы освободить память, связанную с этим объектом Figure в Matplotlib
pdf.savefig(fig_table)
plt.close(fig_table)
# Создание фигуры и осей для гистограммы
fig_hist, ax_hist = plt.subplots(figsize=(14, 6)) # Выберите подходящий размер фигуры
# Установим метки на оси X с названиями месяцев
ax_hist.set_xticks(range(1+len(df['МЕСЯЦ'])))
# Строим столбики гистограммы
ax_hist.bar(df['МЕСЯЦ'], df['ДОХОД'], width=0.4, edgecolor="white", label='доход за месяц', linewidth=0.7)
# Рисуем число заказов
ax_hist.plot(df['МЕСЯЦ'], 5000*df['КОЛИЧЕСТВО ЗАКАЗОВ'], 'r', label='количество заказов (в масштабе x5000)', linewidth=2.0)
# Задание содержимого таблицы со статистикой
ax_hist.set_title(f"Доход от заказов и их количество по месяцам")
#Задание осей гистограммы
ax_hist.set_xlabel('Месяц')
ax_hist.set_ylabel('Доход')
# Добавляем легенду на график
ax_hist.legend()
#Сохранение в pdf и закрытие страницы в файле, чтобы освободить память, связанную с этим объектом Figure в Matplotlib
pdf.savefig(fig_hist)
plt.close(fig_hist)
return current_date
'''
with open('/root/airflow/dags/ANNA_HIST_report_PDF_task.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_HIST_report_PDF_task.py /content/airflow/dags/ANNA_HIST_report_PDF_task.py
Python-файл с задачей формирования круговой диаграммы по данным из SQL-запроса о наиболее популярных товарах:
############################задача формирования PDF-документа с круговой диаграммой##################################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
import pandas as pd
import datetime
import os
def write_circle_to_pdf_function(**kwargs):
results = kwargs['ti'].xcom_pull(task_ids='popular_products_extract_task')
for result in results:
df = pd.DataFrame(results, columns=['ТОВАР', 'КОЛИЧЕСТВО'])
# Получаем текущую дату
current_date = datetime.datetime.now()
# Форматируем дату в строку (например, '2023-03-15')
date_str = current_date.strftime('%Y-%m-%d')
filename = '/content/airflow/files/CIRCLE_report_' + date_str + '.pdf'
with PdfPages(filename) as pdf:
fig_table, ax_table = plt.subplots(figsize=(6, 10)) # Выберите подходящий размер фигуры
#Задание заголовка
ax_table.set_title(f"Самые часто покупаемые товары за 1-ые полгода")
# Задание содержимого таблицы со статистикой
ax_table.axis('tight') #задаем границы области для таблицы так, чтобы они плотно обрамляли содержимое
ax_table.axis('off') #выключаем отображение осей для таблицы (нет границ и делений)
table = ax_table.table(cellText=df.values, colLabels=df.columns, loc='center') #задаем содержимое ячеек таблицы, заголовки столбцов и расположение таблицы
#table.auto_set_font_size(True)
table.set_fontsize(8) #устанавливаем размер шрифта для текста в таблице вручную
table.scale(1.2, 1.2) # Можно изменить масштаб таблицы для лучшего отображения
#Сохранение в pdf и закрытие страницы в файле, чтобы освободить память, связанную с этим объектом Figure в Matplotlib
pdf.savefig(fig_table)
plt.close(fig_table)
# Создание фигуры и осей для круговой диаграммы
fig_circle, ax_circle = plt.subplots(figsize=(10, 8)) # 10 - ширина, 8 - высота фигуры в дюймах
#Задание заголовка
ax_circle.set_title(f"Самые часто покупаемые товары за 1-е полгода")
# Строим круговую диаграмму с отображением данных
ax_circle.pie(df['КОЛИЧЕСТВО'], labels=df['ТОВАР'], autopct='%1.1f%%', startangle=90)
# Устанавливаем соотношение сторон диаграммы как 1, чтобы круг выглядел как круг, а не эллипс
plt.axis('equal')
#Сохранение в pdf и закрытие страницы в файле, чтобы освободить память, связанную с этим объектом Figure в Matplotlib
pdf.savefig(fig_circle)
plt.close(fig_circle)
return current_date
'''
with open('/root/airflow/dags/ANNA_popular_products_PDF_report_task.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_popular_products_PDF_report_task.py /content/airflow/dags/ANNA_popular_products_PDF_report_task.py
Наконец, напишем Python-код для DAG, включив туда ранее созданные задачи:
########################из разных файлов DAG чтения из PostgreSQL и записи в PDF-файл############################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.providers.telegram.operators.telegram import TelegramOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
from ANNA_popular_products_PDF_report_task import write_circle_to_pdf_function
from ANNA_HIST_report_PDF_task import write_hist_to_pdf_function
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_PG_2_TG',
default_args=default_args,
schedule_interval='@daily'
#schedule_interval='*/5 * * * *'
)
start_task = DummyOperator(task_id='start_task', dag=dag)
extract_hist_task = PostgresOperator(
task_id='month_income_extract_task',
postgres_conn_id='my_postgres_conn',
sql="sql/SQL-zapros_month_income.sql",
dag=dag
)
extract_circle_task = PostgresOperator(
task_id='popular_products_extract_task',
postgres_conn_id='my_postgres_conn',
sql="sql/SQL-zapros_popular_products.sql",
dag=dag
)
make_report_HIST_task = PythonOperator(
task_id='write_hist_to_task',
provide_context=True,
python_callable=write_hist_to_pdf_function,
dag=dag
)
make_report_CIRCLE_task = PythonOperator(
task_id='write_circle_to_pdf_task',
provide_context=True,
python_callable=write_circle_to_pdf_function,
dag=dag
)
now=datetime.now()
send_notification_task = TelegramOperator(
task_id='send_notification_task',
telegram_conn_id='my_TG_conn',
text='Reports has been created at {}'.format(
datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
),
dag=dag
)
end_task = DummyOperator(
task_id='end',
dag=dag,
)
start_task >> extract_hist_task
extract_hist_task >> make_report_HIST_task
make_report_HIST_task >> send_notification_task
start_task >> extract_circle_task
extract_circle_task >> make_report_CIRCLE_task
make_report_CIRCLE_task >> send_notification_task
send_notification_task >> end_task
'''
with open('/root/airflow/dags/ANNA_DAG_PG_2_TG.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_DAG_PG_2_TG.py /content/airflow/dags/ANNA_DAG_PG_2_TG.py
!airflow dags unpause ANNA_DAG_PG_2_TG
Чтобы созданный DAG отобразился в GUI веб-сервера, запустим планировщик AirFlow:
!airflow scheduler --daemon
При отсутствии ошибок DAG отобразится в списке всех конвейеров и его можно запустить:
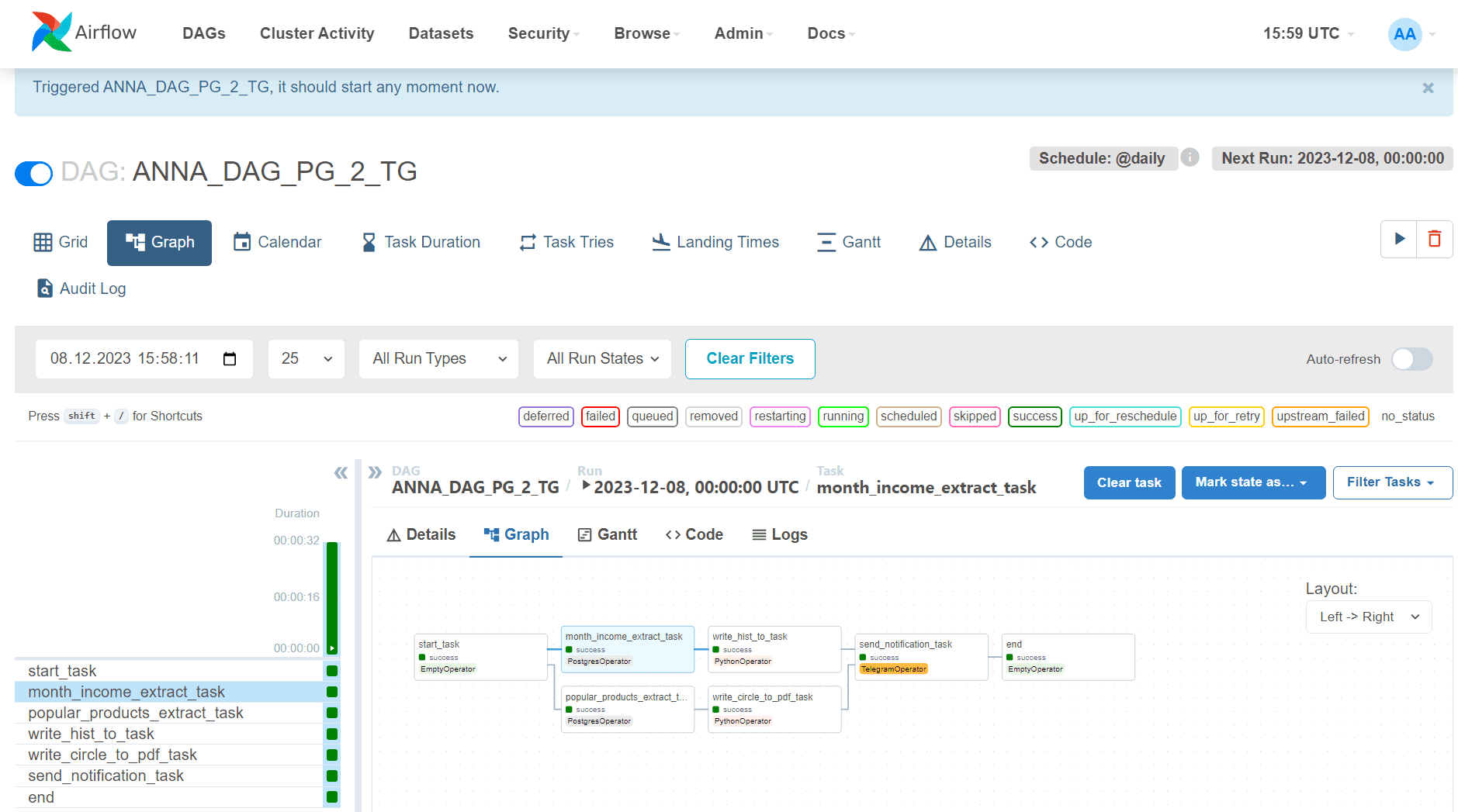
В результате успешного выполнения этого конвейера из 7 задач в заданной директории временного пространства Google Colab создадутся необходимые отчеты.
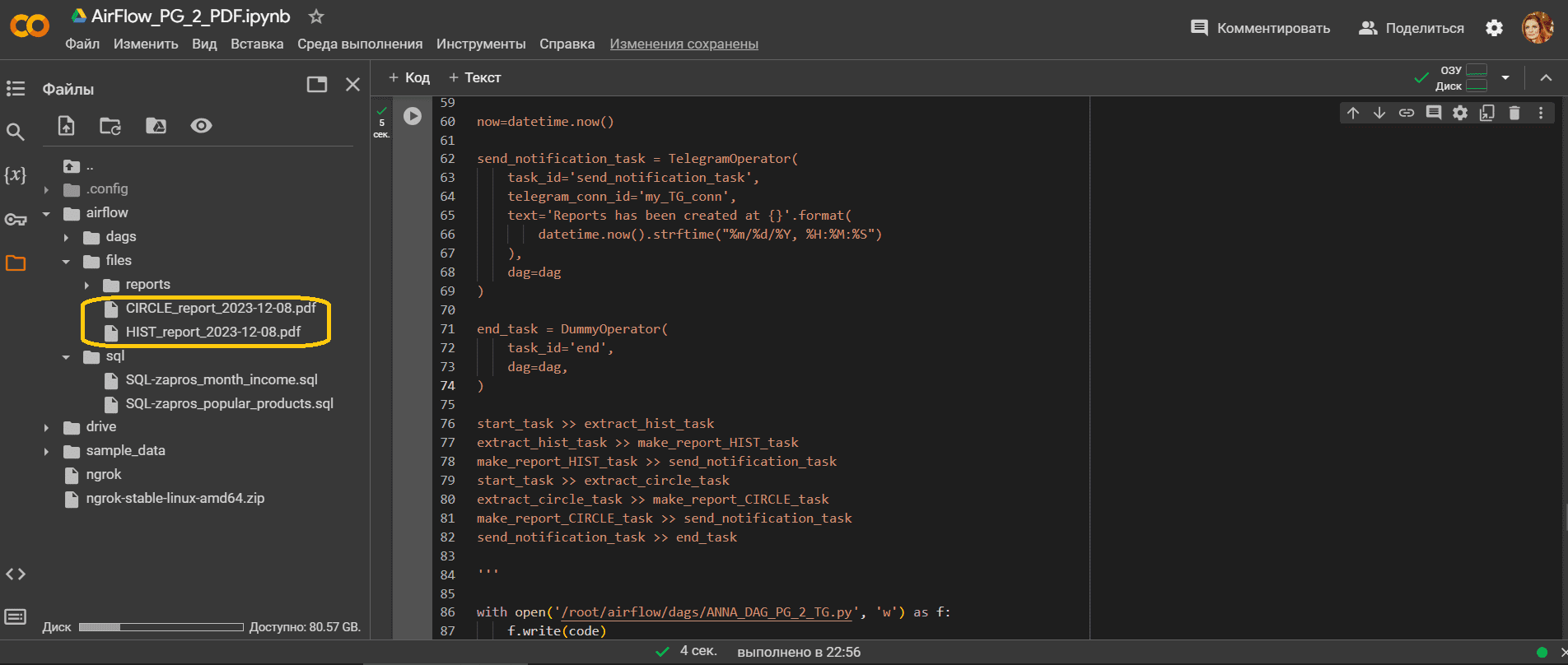
А также сообщение об успешном создании уйдет в Telegram-бот
Сами PDF-файлы отчетов доступны по ссылкам:
Узнайте больше про Apache AirFlow и его практическое использование в дата-инженерии, машинном обучении и аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

