Как планируются и исполняются задания Apache Flink: от пользовательского Java-кода до физического исполнения, а также отслеживание статуса задания в JobManager. Подробности преобразований с примерами кода.
3 этапа преобразования задания Apache Flink
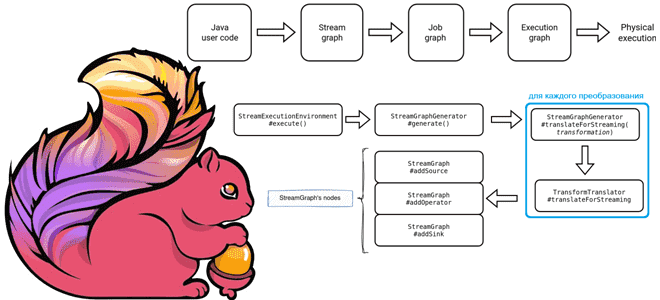
Задание Apache Flink проходит несколько этапов перед своим физическим выполнением:
- сперва пользовательский код преобразуется в потоковый граф (Stream Graph);
- затем узлы потокового графа преобразуются в узлы графа задания (JobGraph), который представляет собой низкоуровневое представление потока данных, принимаемое JobManager, где выполняется объединение нескольких операторов в один.
- наконец, в кластере с помощью JobManager запускается граф выполнения ExecutionGraph, где физической единицей является Задача.

Ресурсы выполнения во Flink определяются через слоты задач (Task Slots). Каждый менеджер задач (TaskManager) имеет один или несколько слотов задач, каждый из которых может запускать один конвейер параллельных задач. Конвейер состоит из нескольких последовательных задач, таких как n-й параллельный экземпляр MapFunction вместе с n-м параллельным экземпляром DownloadFunction. Flink часто выполняет последовательные задачи одновременно: для потоковых программ это происходит в любом случае, но и для пакетных программ это происходит часто.
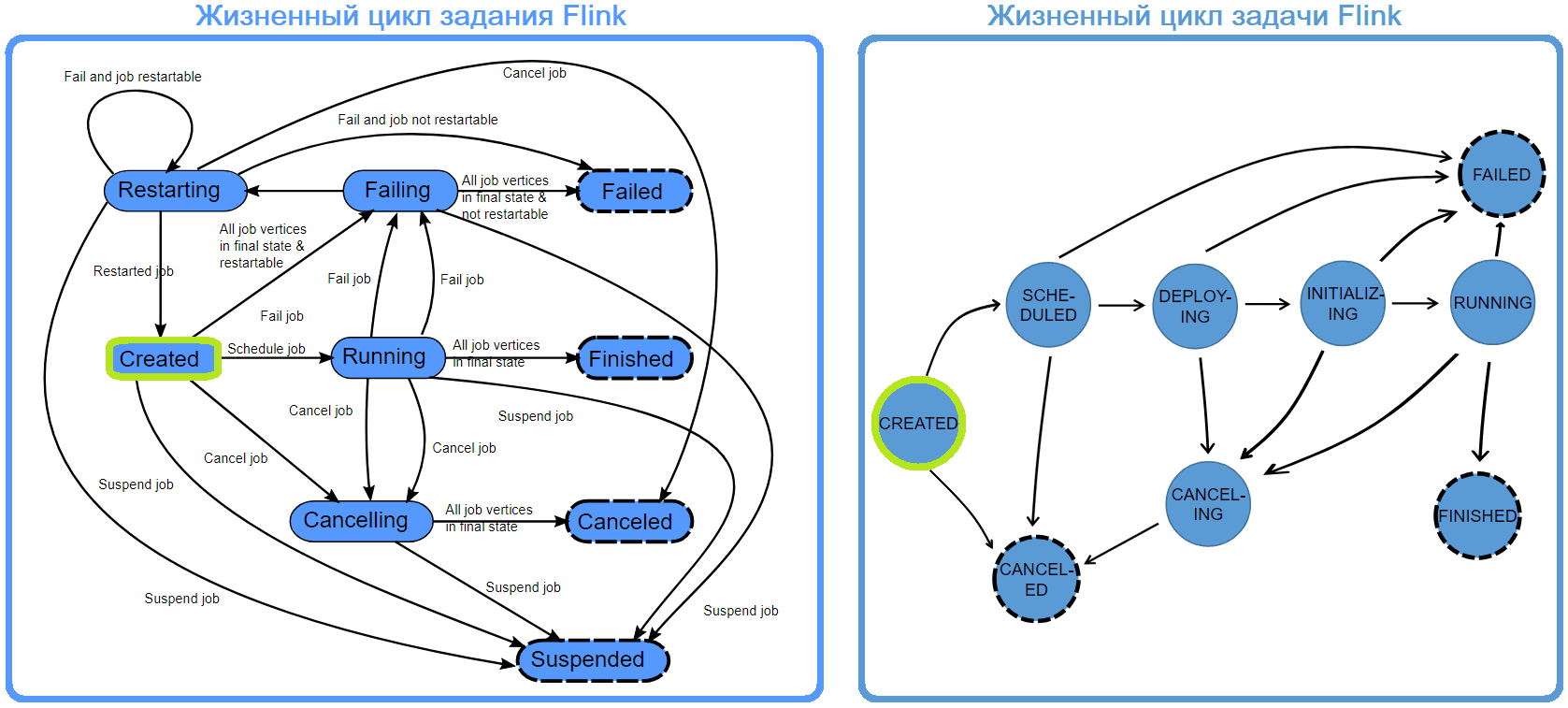
Во время выполнения задания менеджер заданий (JobManager) отслеживает распределенные задачи, решает, когда запланировать следующую задачу или набор задач, и реагирует на завершенные задачи или сбои выполнения. JobManager получает JobGraph, который представляет собой поток данных, состоящий из операторов (JobVertex) и промежуточных результатов (IntermediateDataSet ). У каждого оператора есть свойства, такие как параллелизм и код, который он выполняет. Кроме того, к JobGraph имеется набор подключенных библиотек, необходимых для выполнения кода операторов. JobManager преобразует JobGraph в ExecutionGraph, который представляет собой параллельную версию JobGraph. Для каждой JobVertex он содержит ExecutionVertex для каждой параллельной подзадачи. Оператор с параллелизмом 100 будет иметь один JobVertex и 100 ExecutionVertices. ExecutionVertex отслеживает состояние выполнения конкретной подзадачи. Все ExecutionVertices из одного JobVertex хранятся в ExecutionJobVertex, который отслеживает состояние оператора в целом. Помимо вершин, ExecutionGraph также содержит общий промежуточный результат (IntermediateResult) и разделенный по разделам (IntermediateResultPartition). Первый отслеживает состояние IntermediateDataSet, второй — состояние каждого из его разделов. С каждым ExecutionGraph связан статус задания, который указывает текущее состояние его выполнения. Задание Flink сначала находится в состоянии создано, затем переходит в состояние выполнения и по завершении всей работы переходит в состояние завершения. В случае сбоя задание сначала переключается на сбой , при котором все запущенные задачи отменяются. Во время выполнения ExecutionGraph каждая параллельная задача проходит несколько этапов: от создания до завершения или сбоя. Задача может выполняться несколько раз, например, при устранении сбоя. По этой причине выполнение ExecutionVertex отслеживается в Execution. Каждая ExecutionVertex имеет текущее выполнение и предыдущие исполнения.
Разобравшись с основными принципами преобразования задания, далее рассмотрим их более подробно.
Подробности преобразований с примерами кода
При первом преобразовании пользовательского кода в потоковый граф, когда вызывается оператор, он добавляется во внутренний список преобразований, присутствующих в классе StreamExecutionEnvironment.
public class StreamExecutionEnvironment implements AutoCloseable {
public void addOperator(Transformation<?> transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
Все преобразования преобразуются в StreamNode при вызове функции Execute()/
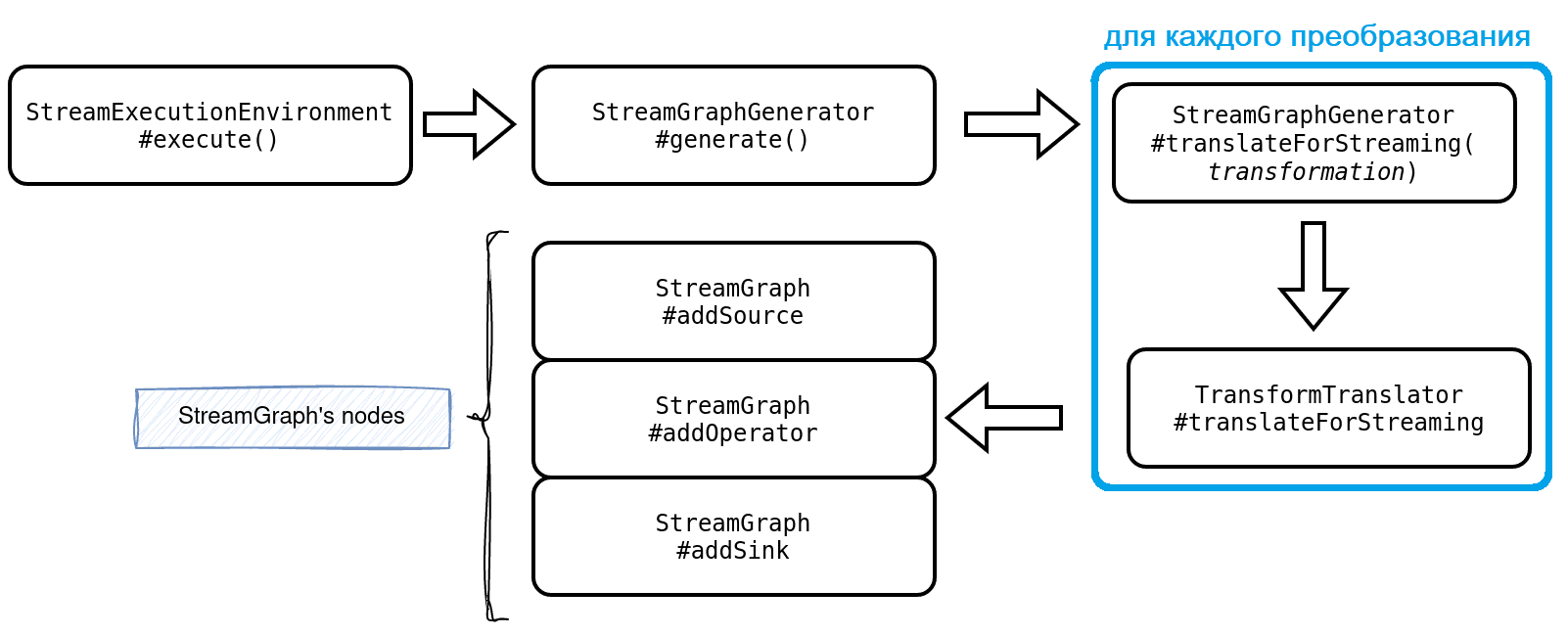
Внутри StreamGraph хранит оператор или его идентификатор в различных структурах:
public class StreamGraph implements Pipeline {
private Map<Integer, StreamNode> streamNodes;
private Set<Integer> sources;
private Set<Integer> sinks;
private Map<Integer, Tuple2> virtualSideOutputNodes;
private Map<Integer, Tuple3, StreamExchangeMode>>
virtualPartitionNodes;
public StreamNode getStreamNode(Integer vertexID) {
return streamNodes.get(vertexID);
}
Источники и приемники используются в генераторе планов JSON, а два последних сопоставления участвуют в создании StreamGraph, узлами которого являются streamNodes, которое позже используется для создания графа задания.
Следующий шаг состоит в трансляции StreamNodes и StreamGraph в классы JobVertex и JobGraph соответственно. JobGraph — это низкоуровневое представление потока данных, принимаемое JobManager. Если вы знакомы с Apache Spark, этот второй шаг можно рассматривать как оптимизацию логического плана, поскольку он улучшает высокоуровневый StreamGraph с помощью различных операций, таких как объединение нескольких операторов в один.
Преобразование StreamNode в JobVertex происходит в методе createJobVertex() класса StreamingJobGraphGenerator и состоит из различных шагов:
- настройка операторов цепочки, когда оператор выполняется в том же потоке, что и его предшественник. В результате эти несколько связанных операторов становятся одним, состоящим из нескольких шагов. Это похоже на этап Apache Spark, где несколько преобразований выполняются в одном процессоре;
- установка характеристик ресурсов, таких как ЦП, память (в куче и вне кучи), предпочтительные или минимальные;
- установка вызываемого класса, который позже будет вызываться для выполнения, который передается из StreamNode в методе setInvokableClass(streamNode.getJobVertexClass());
- определение параллелизма.
Получив логически оптимизированный план, на следующем этапе Apache Flink преобразует его в граф выполнения, который является базовой структурой данных для уровня планирования. Здесь экземпляры JobVertex преобразуются в экземпляры ExecutionVertex, а экземпляры IntermediateDataSets — в IntermediateResultPartition. Здесь уже появляется параллелизм, поскольку ExecutionGraph представляет собой распараллеленную версию JobGraph: количество вершин равно заданному параллелизму. Эта структура представляет собой представление того, что должно физически работать в кластере.
Состояние каждой ExecutionVertex отслеживается классом состояния Execution и может выполняться несколько раз, например, из-за восстановления, реконфигурации или повторных вычислений. Состояние выполнения отслеживает все эти контексты времени выполнения. Кроме того, с каждым выполнением связан идентификатор ExecutionAttempID. Он предоставляет уникальный идентификатор для выполнения задачи и его можно повторить или восстановить.
На этом этапе Apache Flink не только транслирует JobGraph, но и инициализирует другие компоненты, участвующие в обработке потока, такие как CheckpointCoordinator, CoordinatorStore или KvStateLocationRegistry.
Наконец, на последнем этапе в кластере с помощью JobManager запускается ExecutionGraph – граф выполнения, узлами которого являются задачи:
public class Task {
/** The vertex in the JobGraph whose code the task executes. */
private final JobVertexID vertexId;
/** The execution attempt of the parallel subtask. */
private final ExecutionAttemptID executionId;
Задача создается из класса Executing:
class Executing extends StateWithExecutionGraph implements ResourceConsumer {
private void deploy() {
for (ExecutionJobVertex executionJobVertex :
getExecutionGraph().getVerticesTopologically()) {
for (ExecutionVertex executionVertex : executionJobVertex.getTaskVertices()) {
if (executionVertex.getExecutionState() == ExecutionState.CREATED
|| executionVertex.getExecutionState() == ExecutionState.SCHEDULED) {
deploySafely(executionVertex);
}
}
}
}
private void deploySafely(ExecutionVertex executionVertex) {
try {
executionVertex.deploy();
} catch (JobException e) {
handleDeploymentFailure(executionVertex, e);
}
}
После создания и отправки в кластер Задача может быть физически выполнена. Класс реализует интерфейс Runnable, поэтому его физическое выполнение осуществляется в реализованном методе run(), где выполняется следующее:
- меняется состояние жизненного цикла задачи, включая переход в любое конечное состояние, связанное с уведомлением, отправленным в TaskManager;
- инициализация интерфейса TaskInvokable, который создает выделенный экземпляр для конкретного типа задачи и содержит реальную логику вычислений, выполняемую Задачей. Для потоковых конвейеров будут реализации StreamTask.
- вызов метода TaskInvokable(), который запускает выполнение кода задачи;
- управление завершением задачи при необходимости, т.к. долго выполняющаяся задача может остановиться из-за сбоя или отмены.
Освойте лучшие практики применения Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

