 635
635 
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab.
Когда и зачем Spark-приложение создает файл _SUCCESS
В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(), saveAsTable() или запись в DataFrame, выходные данные сохраняются в указанный каталог контрольных точек __cpLocation. При этом создается пустой файл _SUCCESS, который представляет собой файл маркера, указывающий на успешное завершение операции записи. Этот файл обычно используется в сценариях, где есть несколько выходных файлов или разделов.
Наличие файла _SUCCESS помогает внешним системам или процессам определить, успешно ли завершилось задание, без проверки каждого отдельного файла. Файл _SUCCESS сигнализирует о том, что выходные данные в нем завершены и готовы к дальнейшей обработке. Примечательно, что файл _SUCCESS не является обязательным для корректности данных. Его цель – внешний мониторинг и координация.
Можно отключить создание файла _SUCCESS, настроив следующее свойство в конфигурации фреймворка перед записью результатов в файлы:
spark.conf.set("spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs", "false")
Однако, лучше этого не делать, поскольку _SUCCESS файл важен для Spark-приложения по следующим причинам:
- Он является индикатором завершения задания, свидетельствуя о его успешном завершении. Это особенно важно в автоматизированных рабочих процессах, где последующие шаги зависят от успешного завершения предыдущих.
- Гарантия согласованности данных, что очень важно в конвейерах обработки данных. По сути, файл _SUCCESS действует как контрольная точка, гарантируя, что данные, считываемые последующими приложениями, являются полными, а не частичными или поврежденными.
- Координация рабочего процесса. В сложных ETL-процессах этот файл может служить простым, но эффективным способом координации между различными этапами конвейера или даже разными системами.
Практический пример
Рассмотрим создание файла _SUCCESS на практическом примере, написав простое PySpark-приложение, которое создает датафрейм и выполняет операцию записи, сохраняя его в CSV-файл. Код приложения, написанного и запущенного в Google Colab, выглядит так. Сперва установим библиотеки и импортируем пакеты:
!pip install pyspark !apt-get install openjdk-8-jdk-headless -qq > /dev/null !pip install faker #импорт модулей from pyspark.sql import SparkSession import pyspark import sys import os import random os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" # Импорт модуля faker from faker import Faker from faker.providers.address.ru_RU import Provider
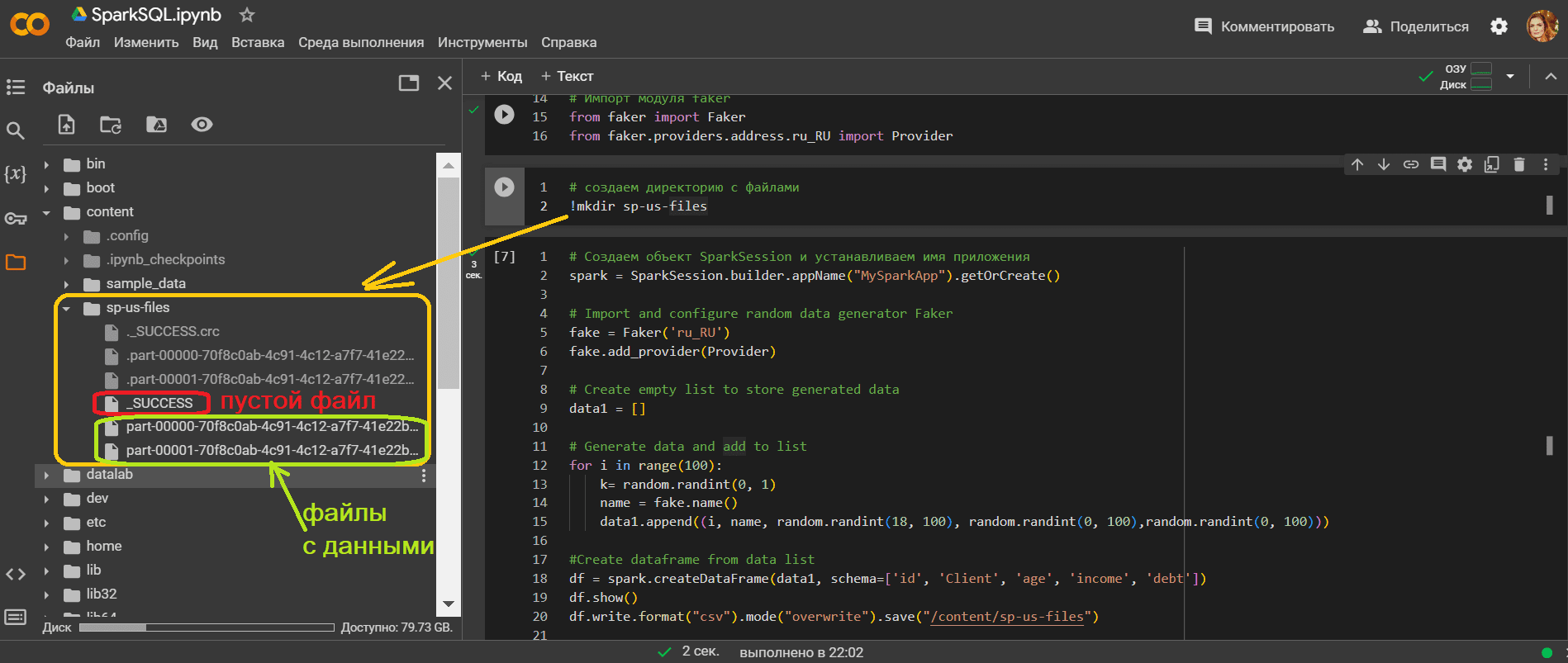
Создадим директорию, куда будем сохранять CSV-файлы:
!mkdir sp-us-files
Создадим приложение, которое генерирует случайные данные о клиентах с помощью библиотеки Faker:
spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
fake = Faker('ru_RU')
fake.add_provider(Provider)
data1 = []
for i in range(100):
k= random.randint(0, 1)
name = fake.name()
data1.append((i, name, random.randint(18, 100), random.randint(0, 100),random.randint(0, 100)))
df = spark.createDataFrame(data1, schema=['id', 'Client', 'age', 'income', 'debt'])
df.show()
df.write.format("csv").mode("overwrite").save("/content/sp-us-files")
Запустив этот PySpark-приложение, увидим в директории для сохранения файлов не только сами файлы с данными, но и пустой файл, свидетельствующий об успешном завершении операции записи.
Узнайте больше про возможности PySpark и других интерфейсов этого распределенного движка для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

