Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов.
Потоковые примитивы и низкоуровневый API
Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев.
На самом нижнем уровне абстракции обработка потоков с сохранением состояния реализуется с помощью примитивов – строительных блоков, которые можно отнести к одной из следующих категорий:
- потоки – это основы потоковой обработки. Они могут быть неограниченными или ограниченными, т.е. наборами данных фиксированного размера. Flink имеет сложные функции для обработки неограниченных потоков, а также выделенных операторов для эффективной обработки ограниченных потоков. Flink поддерживает два способа обработки данных: потоковый (в реальном времени) по мере создания или сохранения потока в системе хранения, например, файловой системе или хранилище объектов, а также пакетный – последующая обработка ограниченного набора данных. Приложения Flink могут обрабатывать записанные потоки или потоки в реальном времени.
- Обычно потоковое приложение имеет состояние. Только приложения, которые применяют преобразования к отдельным событиям, не требуют состояния. Любому приложению, выполняющему базовую бизнес-логику, необходимо запоминать события или промежуточные результаты, чтобы получить к ним доступ в более поздний момент времени, например, при получении следующего события или по истечении определенного периода времени. Flink предоставляет примитивы состояния для различных структур данных, таких как атомарные значения, списки или сопоставления. Разработчик выбирает наиболее эффективный примитив состояния в зависимости от шаблона доступа к функции. Состояние приложения управляется и контролируется подключаемым сервером состояния, который хранит состояние в памяти или во встроенном key-value хранилище RocksDB. Также можно подключить бэкэнды с пользовательским состоянием. Механизмы контрольных точек и точек сохранения Flink гарантируют согласованность состояния приложения в случае сбоя. Flink способен поддерживать состояние приложения размером в несколько терабайт благодаря асинхронному и инкрементному механизму контрольных точек. Flink поддерживает масштабирование stateful-приложений путем перераспределения состояния между большим или меньшим количеством рабочих процессов.
- время — еще один важный компонент потоковых приложений. Большинству потоков событий присуща семантика времени, поскольку каждое событие создается в определенный момент времени. Более того, многие общие потоковые вычисления основаны на времени, например, агрегирование окон, разбивка по сеансам, обнаружение шаблонов и соединения на основе времени. Важным аспектом потоковой обработки является то, как приложение измеряет время, т. е. разницу между временем события и временем обработки. Flink имеет богатый набор функций, связанных со временем: приложения, которые обрабатывают потоки с семантикой времени события, вычисляют результаты на основе временных меток событий. Flink использует водяные знаки для определения времени в приложениях, реагирующих на события. Механизм watermark обеспечивает компромисс между задержкой и полнотой результатов. Для обработки запоздалых событий Flink позволяет перенаправить их через побочные выходы и обновление ранее завершенных результатов. Также фреймворк поддерживает режим вычислений, который подходит для приложений со строгими требованиями к малой задержке и допускает приблизительные результаты.
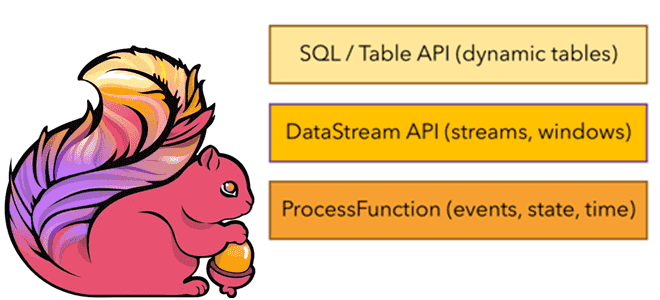
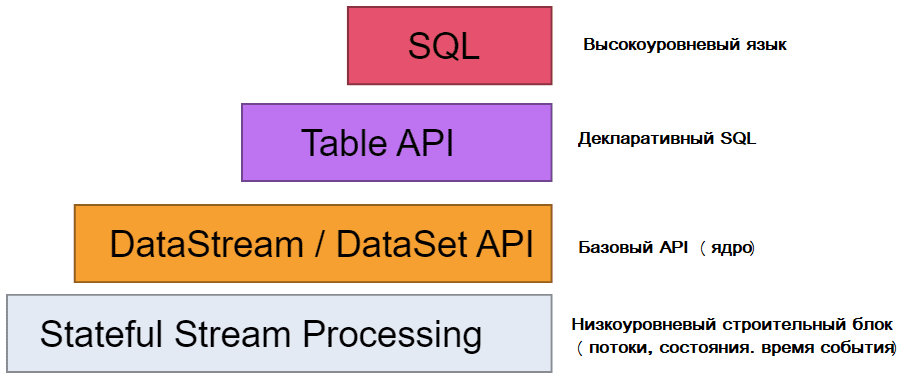
Впрочем, на практике совсем не обязательно напрямую использовать вышеперечисленные низкоуровневые абстракции. Вместо этого разработчик может использовать высокоуровневые API: DataStream/DataSet, Table и SQL. Эти гибкие API предлагают общие строительные блоки для обработки данных, такие как различные формы пользовательских преобразований, объединений, агрегаций, окон, состояния и пр. Типы данных, обрабатываемые в этих API, представлены как классы на соответствующих языках программирования. В частности, процессные функции низкого уровня интегрируются с API DataStream, что позволяет использовать абстракцию нижнего уровня по мере необходимости. API DataSet предлагает дополнительные примитивы для ограниченных наборов данных, такие как циклы/итерации. Начиная с версии 1.12, DataSet API считается устаревшим и будет удален в релизе Flink 2.0. Рекомендуется перейти с DataSet API на DataStream, о чем мы рассказываем здесь.
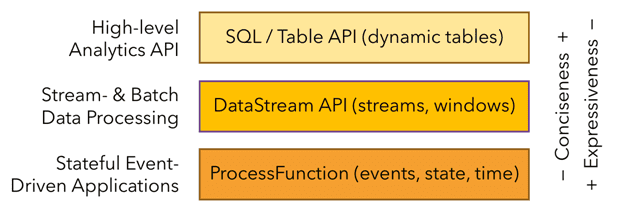
ProcessFunctions — это наиболее выразительные функциональные интерфейсы, которые предлагает Flink для обработки отдельных событий из одного или двух входных потоков или событий, сгруппированных в окне. ProcessFunctions обеспечивают детальный контроль над временем и состоянием, может произвольно изменять свое состояние и регистрировать таймеры, которые в будущем вызовут функцию обратного вызова. Следовательно, ProcessFunctions может реализовать сложную бизнес-логику для каждого события, что требуется для многих приложений, управляемых событиями. Потоковые примитивы встроены в API DataStream через процессные функции, позволяя пользователям обрабатывать события из одного или нескольких потоков и обеспечивая согласованное отказоустойчивое состояние. Также разработчик может регистрировать время событий и обратные вызовы времени обработки, чтобы выполнять сложные вычисления.
Высокоуровневые API
API DataStream предоставляет примитивы для типовых операций потоковой обработки, таких как управление окнами, единоразовые преобразования записей и обогащение событий путем запроса внешнего хранилища данных. API DataStream доступен для Java и Scala и основан на таких функциях, как map(), reduce() и aggregate(). Функции могут быть определены путем расширения интерфейсов или как лямбда-функции Java или Scala.
Помимо DataStream, Flink предоставляет Table API – декларативный DSL, основанный на таблицах, которые могут быть динамически изменяющимися таблицами при представлении потоков. API таблиц следует расширенной реляционной модели: к таблицам прикреплена схема аналогично таблицам в реляционных базах данных, и предлагает сопоставимые операции, такие как выборка, проекция, соединение, группировка, агрегация и пр. Table API позволяет декларативно определить, какую логическую операцию следует выполнить, вместо того, чтобы точно задавать ее программный код. Хотя Table API можно расширить с помощью различных UDF-функций, он менее выразителен, чем Core API, и более лаконичен в использовании. Кроме того, программы Table API перед выполнением проходят через оптимизатор, который повышает эффективность программных конструкций. Конструкции высокоуровневых API можно конвертировать между собой, а также использовать вместе. Абстракция самого высокого уровня, предлагаемая Flink, — это SQL. Эта абстракция похожа на Table API как по семантике, так и по выразительности, но представляет программы как выражения SQL-запросов.
Оба API являются унифицированными API для пакетной и потоковой обработки, т.е. запросы выполняются с одинаковой семантикой для неограниченных потоков реального времени или ограниченных записанных потоков и дают одинаковые результаты. Table API и SQL используют Apache Calcite для анализа, проверки и оптимизации запросов. Эти реляционные API-интерфейсы Flink отлично подходят для приложений анализа данных, конвейерной обработки данных и ETL-процессов.
Читайте в нашей новой статье, как будет изменен API фреймворка в релизе 2.0.
Освойте возможности Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

