
Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...
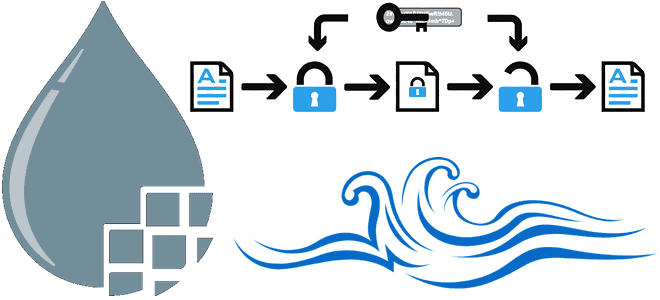
В этой статье для дата-инженеров поговорим про шифрование потока данных в Apache NiFi с помощью набора процессоров, поддерживающих спецификацию OpenPGP. Криптографическая защита целостности и конфиденциальности потока данных. Криптографические процессоры Apache NiFi Криптография является одним из наиболее распространенных методов защиты целостности и конфиденциальности данных с помощью шифрования и дешифрования. Сегодня чаще...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
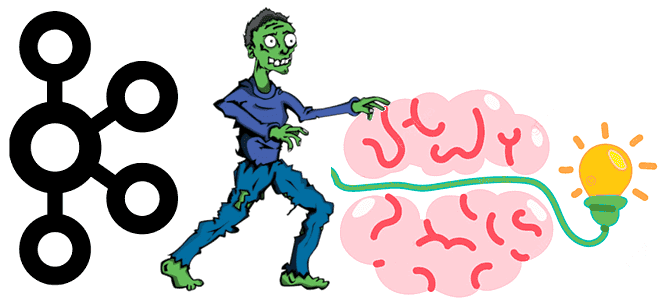
Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka. Проблема разделенного мозга или зомби-процессы в распределенных системах Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению....
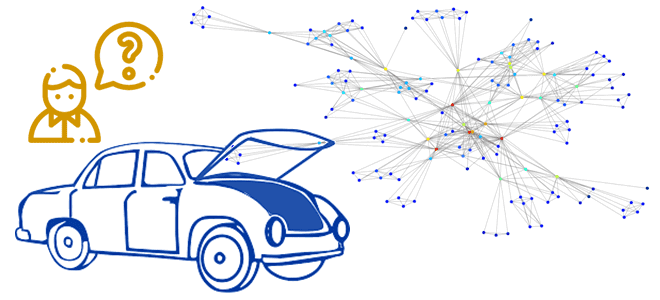
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
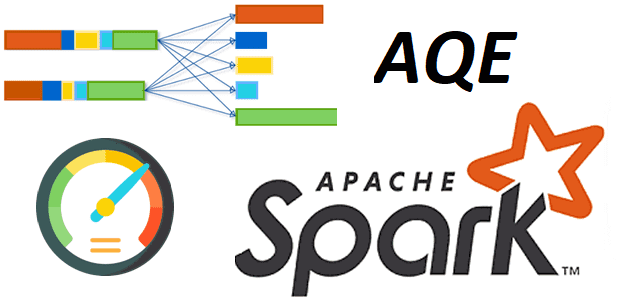
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...
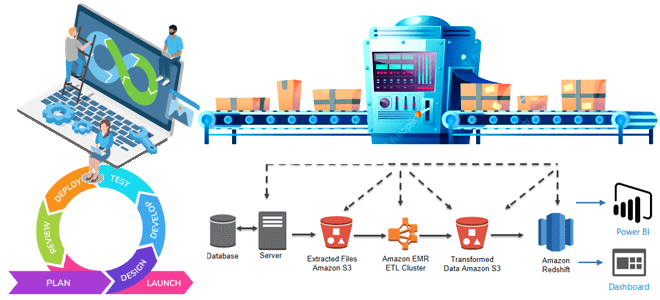
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...