
В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka. Проблемы масштабирования потоковой обработки в Kafka Streams Масштабная потоковая...
На протяжении всей истории человечества пандемии являлись причинами глобальных макроэкономических изменений. Например, эпидемия чумы привела к окончательному падению монгольской империи, изменив баланс сил между мусульманским и европейским миром в пользу последнего. А эпидемия испанки, разразившаяся в конце первой мировой войны, привела к окончательной капитуляции Германии. Последняя пандемия COVID-19 изменила мир...
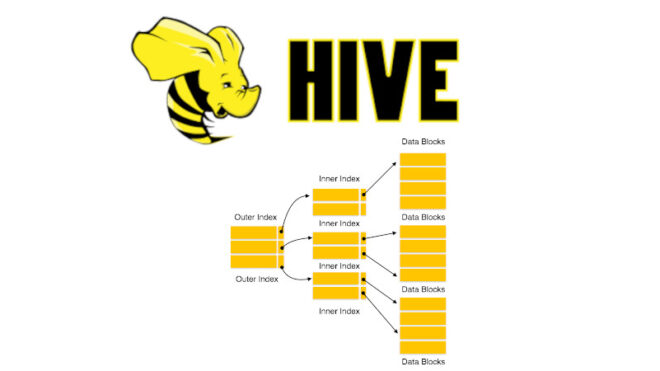
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
В рамках продвижения нашего нового курса по графовым алгоритмам на больших данных, сегодня разберем, что такое Pregel, и как API этой платформы реализован в Apache Spark GraphX. Читайте далее, как из RDD вершин и ребер образуется триплет, а также какие механизмы отвечают за отказоустойчивость графовой аналитики больших данных. Что такое...
Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...
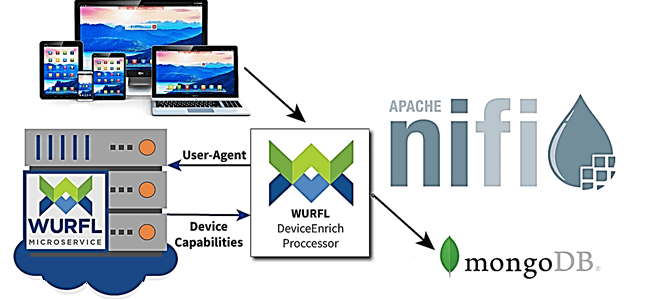
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi....

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....