 1157
1157 
Содержание
Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на конвейерах пакетной и потоковой аналитики больших данных, а также с какими проблемами они столкнулись и как это было решено.
CDC-конвейер на Apache Kafka, NiFi, Spark и AirFlow для DWH на Greenplum
Проект разработки собственной платформы данных в российском отделении международного DIY-ритейлера Леруа Мерлен начался еще в 2019 году. 2 года спустя, в середине 2021 эта Big Data система была полностью реализована и сейчас активно используется в production, обрабатывая около 2000 запросов в минуту для 2 тысяч пользователей. В качестве ключевого элемента платформы, хранилища данных, была выбрана MPP-СУБД Greenplum из-за open-source статуса, поддержки ANSI SQL и совместимости с ранее внедренными решениями на базе PostgreSQL.
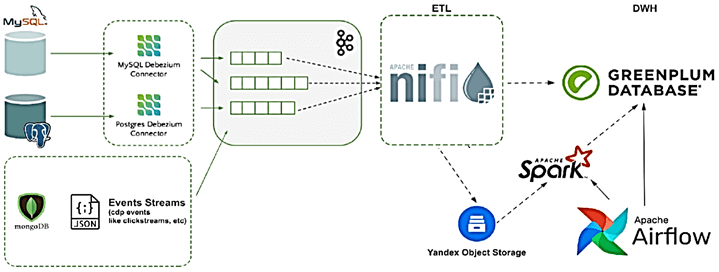
Прежде всего была организована интеграция данных из существующих реляционных СУБД в платформу, чтобы пользователи могли строить свои аналитические отчеты на едином источнике, а не множестве разрозненных баз. С учетом большого количества систем-источников (более 350 реляционных баз данных) на них был настроен механизм захвата измененных данных (CDC, Change Data Capture), которые с помощью Debezium отправлялись в Apache Kafka. Подробнее о том, как Debezium связан с Apache Kafka через фреймворк Connect мы рассказывали здесь и здесь. За дальнейшую маршрутизацию и обработку этих сообщений отвечал инструмент потокового ETL — Apache NiFi, отправляя сырые данные в первичный слой DWH-хранилища на Greenplum [1].
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, «сырые» данные из множества систем-источников записываются в топики Kafka в виде сообщений в формате AVRO и в режиме реального времени с помощью Apache NiFi отправляются в формате Parquet в облачное хранилище Amazon S3. Далее эти данные обрабатывают Spark-задания [2]:
- мелкие файлы объединяются в более крупные, чтобы снизить количество выходных файлов для оптимизации записи и последующего чтения, а также удаляются дубли с помощью методов distinct()и coalesce(). Результат также сохраняется в AWS S3 как архив исходных данных;
- далее выполняется синтаксический анализ или парсинг данных с последующим сохранением в плоские структуры согласно маппингу в метаданных. Так из одного входного файла могут получиться несколько плоских структур в виде сжатых CSV-файлов. Они также сохраняются в AWS.
Наконец, CSV-файлы загружаются в ODS-слой DWH на базе Greenplum путем создания временной внешней таблицы над данными из AWS S3 через PXF-коннектор. За оркестрацию заданий отвечает Apache Airflow, DAG’и для которого генерируются динамически на основании метаданных. По мере роста количества источников и разнообразия данных возникла потребность в модификации этого конвейера. В частности, некоторые источники данных не являлись реляцонными СУБД, а сами данные могли представлять собой не табличные записи со строго определенной структурой, а поток JSON-объектов. Поэтому дата-инженеры Леруа Мерлен разработали собственный конвертер схемы данных из AVRO в JSON, работающий с использованием Kafka Schema Registry и Spark-задания, преобразующего JSON-объекты в датафреймы.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Для работы с потоками событий, например, данных о пользовательском поведении (клики, просмотры и пр.), добавлено Yandex Object Storage, куда Apache NiFi отправлял файлы в формате Parquet. А Spark-задания выполняли парсинг этих данных и загружали их в Greenplum через PXF-коннектор [3].
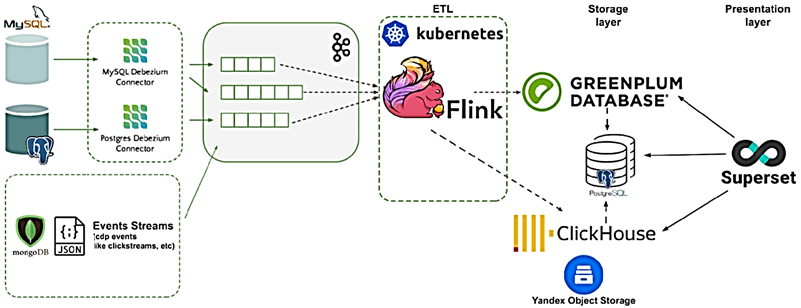
Потоковая аналитика больших данных с Apache Flink и Superset
В рамках эксплуатации пользователи и администраторы платформы столкнулись со следующими проблемами и ограничениям [3]:
- отсутствие возможности строить отчеты по бизнес-показателям в реальном времени;
- низкая скорость выполнения аналитических запросов из-за большого количества накопленных данных и разнообразия самих запросов, не адаптированных к особенностям Greenplum. В итоге обработка 150 млн CDC-событий занимала до 4 часов.
- отсутствие возможности прямого подключения BI-инструментов к Greenplum для конечных пользователей;
- высокое потребление ресурсов.
Чтобы удовлетворить самую большую потребность пользователей (в операционных данных), был разработан новый сервис на базе аналитического фреймворка Apache Flink, который начиная с версии 1.11 поддерживает CDC-потоки, генерируемые Debezium. Как и Apache Spark, Flink имеет SQL-модуль и поддерживает реестр схем Kafka Confluent, а также имеет большое количество коннекторов к различным источникам и приемникам данных. Но, в отличие от Spark, Flink реализует не микро-пакетный, а настоящий потоковый режим обработки событий. ClickHouse выбран как средство операционной отчетности поверх Yandex Object Storage и AWS S3.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
1 июня, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
В качестве презентационного слоя для конечных пользователей выбран Apache Superset – веб-интерфейс для написания SQL-запросов и визуализации результатов на наглядных дэшбордах и графиках с поддержкой функций администрирования и CI/CD-задач. Таким образом, Greenplum формируются аналитические витрины, которые выгружаются в PostgreSQL с помощью PXF-коннектора и дополняются оперативными данными из ClickHouse.
Развернув вышеописанное решение в production, дата-инженеры Леруа Мерлен столкнулись со следующими проблемами [1, 3]:
- Большое количество топиков Apache Kafka из-за подхода «один источник данных – один топик». Много таблиц в одном источнике данных хранятся в одном топике Kafka. При необходимости обработать данные одной таблицы из одного источника с помощью Flink приходится читать весь поток по этому источнику.
- Отсутствие метаданных из Debezium. В используемой версии Apache Flink 1.12 нет возможности получить метаданные из полей Debezium, т.е. определить имя таблицы по имени сообщения из Kafka с данными CDC-потока.
- Ограничения генерации схем – текущая версия Flink не позволяет генерировать схему данных из заголовка сообщений без использования Schema Registry;
- Трудность конфигурирования Apache Superset — большое количество параметров с ограничениями на количество обрабатываемых и выгружаемых строк;
- Сложность подключения проприетарных источников, в частности Oracle и DB2 требуют установки дополнительных драйверов и пакетов.
- Высокая частота обновлений Apache Superset из-за «молодого» возраста этого open-source проекта.
Также дата-инженеры строительного ритейлера отметили сложность первоначальных настроек сети Greenplum, ускоренный износ жестких дисков из-за большого количества IOPS-операций и чрезмерное потребление вычислительных ресурсов (ЦП, память). Поэтому было решено перевести всю инфраструктуру в гибридное облако, чтобы сэкономить и управлять ей как кодом с помощью набора DevOps-инструментов и средств мониторинга: Terraform, Ansible, Jenkins, ELK, Consul, Prometheus и Grafana. В результате этого решения дата-инженеры Леруа Мерлен получили качественную и масштабируемую платформу данных на open source продуктах в облачной инфраструктуре [3].
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Больше полезных примеров администрирования и эксплуатации Apache Kafka, Spark, Flink, NiFi, AirFlow, Greenplum и других технологий Big Data для разработки распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и дата-аналитиков в Москве:
- Greenplum для инженеров данных
- Эксплуатация Apache NIFI
- Data Pipeline на Apache Airflow
- Apache Kafka для разработчиков
- Потоковая обработка в Apache Spark
Источники

