
Бесплатный митап «Работа с источниками данных в Apache Spark» Школа Больших Данных продолжает серию митапов по Apache Spark. Митап состоится 14 июня в 17:00 МСК по теме «Установка Apache Spark - это просто». Митап рассчитан на инженеров данных, разработчиков и просто интересующихся: научимся загружать данные в Spark из файлов и...

17 мая 2022 года вышел очередной релиз главной платформы потоковой передачи событий. Смотрим самые важные обновления свежей Apache Kafka 3.2.0 с точки зрения разработчика распределенных приложений, дата-инженера и администратора кластера. ТОП-5 новинок свежей версии Apache Kafka для администратора кластера Apache Kafka 3.2.0 включает 2 новые фичи, 36 улучшений и 65...

Как писать UDF-функции Greenplum на Python: краткий обзор расширения PL/Python для дата-инженера и разработчика распределенных приложений. Как его установить, настроить и использовать: сопоставления типов данных, SQL-запросы, модули и функции. Поддержка Python в MPP-СУБД Поскольку освоить Python намного проще других языков программирования, например, Java или C#, неудивительно, что он сегодня очень...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
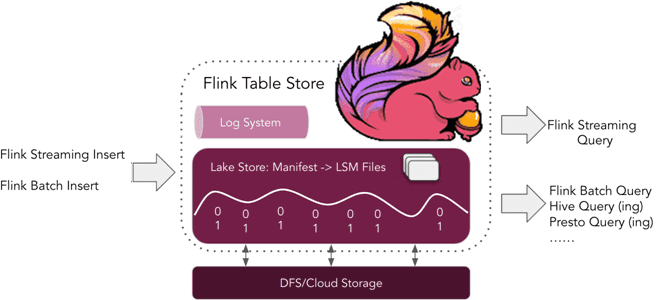
Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений. Что такое Flink Table Store и зачем это нужно Уже более полугода, с релиза 1.14, выпущенного в...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...
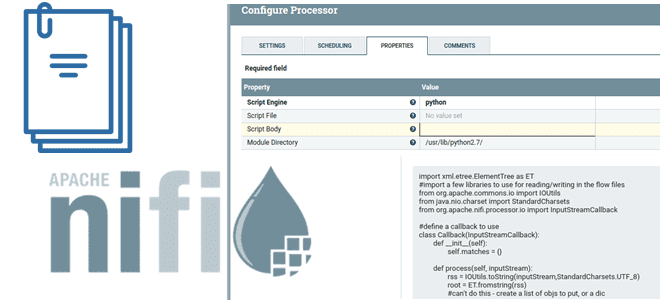
В этой статье для дата-инженеров разберемся, что такое NiFi Scripted Components и как они заполняют пробел между скриптами и пользовательскими компонентами: процессорами, контроллерами, сообщениями и средствами их чтения/записи. Рассмотрим примеры скиптовых процессоров и сервисов, а также определим реальные достоинства и недостатки этих компонентов. Почему просто скриптовых процессоров Apache NiFi недостаточно?...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...