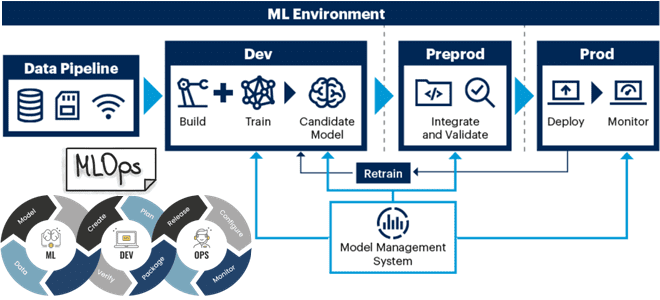
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...
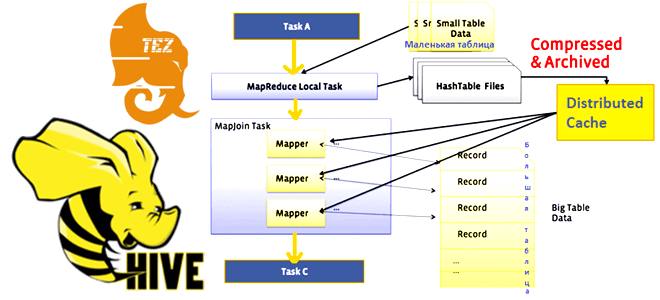
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...

Недавно мы писали про главные новинки свежего релиза Apache Flink 1.15, особенно важные с точки зрения обучения разработчиков распределенных приложений и дата-инженеров. Сегодня рассмотрим подробнее, зачем в этом выпуске введены дополнительные режимы восстановления потоковых stateful-заданий из моментальных снимков, когда и какой режим использовать, а также как выбрать формат точки сохранения...

В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике. Что такое Data Fabric...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
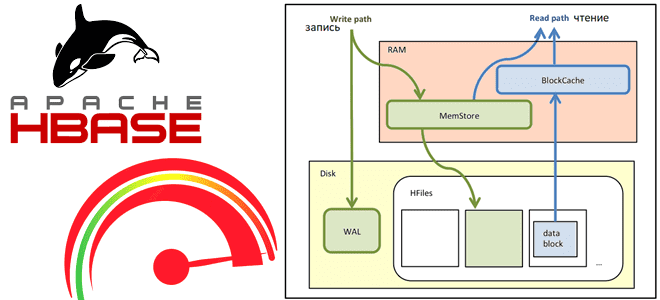
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений. OOM, большие графы и пакетные транзакции в Neo4j...

Недавно мы писали про Apache AirFlow 2.3.0 от 30 апреля 2022 года. Сегодня более подробно разберем одну из главных новинок этого релиза – динамическое сопоставление задач. Что это такое, как работает и зачем нужно дата-инженеру. Что такое динамическое сопоставление задач в ETL-конвейере Напомним, динамическое сопоставление задач (Dynamic Task Mapping) считается...