
Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger.
Зачем нужна интеграция Apache Hive с Kafka
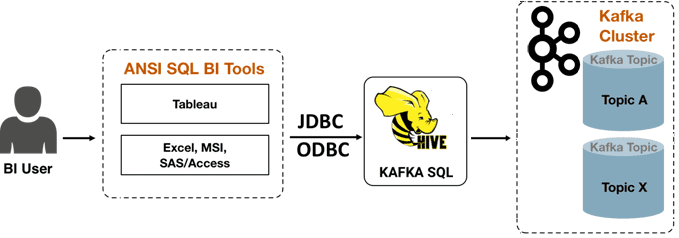
Необходимость связать Apache Hive с Kafka чаще всего возникает в сценариях, связанных с BI-аналитикой, исследованием данных и выявлением тенденций. В таких случаях дата-аналитики и специалисты по системам Business Intelligence выдвигают следующие требования к Kafka:
- возможность рассматривать топики и потоки Kafka как таблицы;
- поддержка ANSI SQL;
- поддержка сложных соединений по разным ключам, нескольким таблицам, с предикатами нетабличных ключей и пр;
- расширяемость с UDF-функциями;
- поддержка JDBC/ODBC;
- создание представлений для маскирования столбцов;
- расширенная поддержка ACL, включая безопасность на уровне столбцов.
Все это есть в Apache Hive – популярном NoSQL-хранилище, которое реализует возможность обращения к данным в Hadoop HDFS как к SQL-таблицам. Таким образом, удовлетворить вышеперечисленные требования позволяет обработчик хранилища Hive для Kafka, который позволяет пользователям просматривать топики Kafka в виде Hive-таблиц, применяя аналитические операции SQL-on-Hadoop, включая сложные соединения, агрегации, оконные функции, пользовательские функции, фильтрацию предикатов pushdown и пр.
Можно сказать, цель интеграции Hive-Kafka – дать пользователям возможность быстро подключать, анализировать и преобразовывать данные в Kafka с помощью SQL, позволяя создать внешнюю таблицу Hive, которая сопоставляется с топиком Kafka, без фактического копирования или материализации данных в HDFS или любом другом постоянном хранилище. Используя эту внешнюю таблицу Hive, пользователи смогут запускать любые SQL-операторы со встроенной поддержкой проверки подлинности и авторизации с помощью Ranger. Так можно выполнять специальные запросы через временные интервалы в потоке и строго однократно выгружать данные, контролируя положение в потоке. Еще допустимо маскировать, объединять, соединять и изменять кодировку сериализации исходного потока и создавать поток, сохраняемый в топике Kafka. Соединения могут быть связаны с любой таблицей измерений или любым потоком.
Наконец, пользователь Kafka может выгружать данные из нее в хранилище Hive (HDFS, S3 и пр.), а пользователь Hive – подключаться, анализировать и преобразовывать потоковые данные в реальном времени и включать их в свое приложение. При подключении к данным Kafka из Hive создается внешняя таблица, которая сопоставляется с топиком Kafka. Определение таблицы включает ссылку на обработчик хранилища Kafka, который подключается к этой платформе потоковой передачи событий. Во внешней таблице интеграция Hive-Kafka поддерживает специальные запросы, например, об изменении данных в потоке за определенный период времени.
Преобразовать данные Kafka можно следующими способами:
- выполнить маскирование данных;
- присоединить к таблицам измерений или любому потоку;
- агрегировать данные;
- изменить кодировку SerDe исходного потока;
- создать постоянный поток в топике Kafka.
Можно перезагрузить данные, контролируя их положение в потоке. Коннектор поддерживает несколько форматов сериализации и десериализации: JSON (по умолчанию), OpenCSV и AVRO. Как подключиться к топику Kafka из Hive, мы рассмотрим далее на практическом примере.
Интеграционные настройки и конфигурации
Чтобы подключиться к топику Kafka из Hive, нужно создать внешнюю таблицу, выполнив соответствующий DDL-запрос для представления потока. Определение внешней таблицы обрабатывается реализацией обработчика хранилища под названием «KafkaStorageHandler». Обработчик хранилища использует два обязательных свойства таблицы для сопоставления имени темы Kafka и строки подключения брокера. Например, следующий запрос создает внешнюю Hive-таблицу с именем, указывающим формат Avro в определении этой таблицы:
CREATE EXTERNAL TABLE kafka_t_avro
(`timestamp` timestamp , `page` string, `newPage` boolean, added int, deleted bigint, delta double)
STORED BY
'org.apache.hadoop.hive.kafka.KafkaStorageHandler'
TBLPROPERTIES
("kafka.topic" = "test-topic", "kafka.bootstrap.servers"="localhost:9092",
"kafka.serde.class"="org.apache.hadoop.hive.serde2.avro.AvroSerDe");
Напомним, что записи в Kafka хранятся в виде пар ключ-значение, поэтому нужно предоставить классы сериализации/десериализации для преобразования массива байтов значений в набор столбцов. Сериализация/десериализация предоставляется с использованием свойства таблицы kafka.serde.class. По умолчанию используется JsonSerDe, также есть стандартные серверы для других форматов(CSV, AVRO и пр). В дополнение к столбцам схемы, определенным в DDL-запросе, обработчик хранилища фиксирует столбцы метаданных для раздела Kafka, включая сам раздел, метку времени и смещение. Столбцы метаданных позволяют Hive оптимизировать запросы для «путешествий во времени», сокращения разделов и поиска на основе смещения.
Начиная с версии 0.10.1, каждое сообщение Kafka имеет связанную с ним временную метку, семантика которой настраивается: например, когда лидер или потребитель получает сообщение и пр. Hive добавляет это поле временной метки в виде столбца во внешнюю таблицу данных из платформы потоковой передачи событий. С помощью этого столбца можно использовать предикаты фильтрации для путешествий во времени, чтобы, к примеру, выбрать записи только для чтения после заданного момента времени. Это достигается с помощью пользовательского общедоступного API Kafka OffsetsForTime, который возвращает смещение для самого раннего смещения каждой секции, чья отметка времени больше или равна заданной. Hive анализирует дерево выражения фильтра и ищет любой предикат в следующей форме, чтобы обеспечить оптимизацию смещения на основе времени: __timestamp [>= , >, =] Constant_int64. Клиенты используют эту мощную оптимизацию, создавая основанные на времени представления данных в платформе потоковой передачи событий.
Еще одной важной оптимизацией SQL-запросов при интеграции Hive-Kafka является сокращение разделов (partition pruning), когда таблицы партиционируются на основе столбца метаданных __partition. Любой предикат фильтра для этого столбца можно использовать для исключения неиспользуемых разделов. Коннектор также использует преимущества поиска на основе смещения, что позволяет пользователям искать определенное смещение в потоке. Так для поиска в потоке можно использовать любой предикат, который можно использовать в качестве начальной точки, например, __offset > Constant_64int. Поддерживаются все арифметические операторы: =, >, >=, <, <=.
В заключение отметим, что для тех кластеров Hive, которые используют Kerberos для проверки подлинности, коннектор с Kafka поддерживает два режима, переключение между которыми происходит через конфигурацию connect.hive.security.kerberos.auth.mode. Конфигурация connect.hive.security.kerberos.ticket.renew.ms управляет интервалом (в миллисекундах) для обновления ранее полученного (во время входа в систему) токена Kerberos.
При настройке режима Keytab файл keytab должен быть доступен по одному и тому же пути на всех рабочих кластерах Hive Connect. Коннектор позволяет поддерживать несколько принципалов Kerberos в одном рабочем процессе Connect. Если таблица ключей недоступна, аутентификация Kerberos может выполняться с использованием подхода пользователя и пароля:
connect.hive.security.kerberos.user = user_name connect.hive.security.kerberos.password=user_password connect.hive.security.kerberos.krb5=/path_to_the/krb5 connect.hive.security.kerberos.jaas=/path_to_the/jaas
Освойте практические навыки эксплуатации Apache Hive и Kafka для построения эффективных ETL-конвейеров с целью аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://dzone.com/articles/introducing-hive-kafka-integration-for-real-time-k
- https://docs.lenses.io/5.0/integrations/connectors/stream-reactor/sources/hivesourceconnector/
- https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.4/integrating-hive/content/hive-kafka-integration.html

