
Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow. Аналитика системных метрик Apache AirFlow с ADA и Amundsen ADA — это микросервис, созданный для...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...
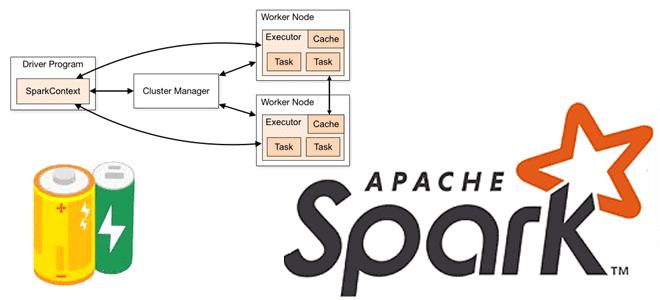
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...

Подводим итоги нарушений информационной безопасности в Apache NiFi за первую половину 2023 года. Инъекции кода, десериализация недоверенных данных и неправильное ограничение ссылок на внешние объекты XML. Какие уязвимости в Apache NiFi найдены и исправлены за первую половину 2023 года За 2023 год в Apache NiFi выявлено и исправлено всего 3...
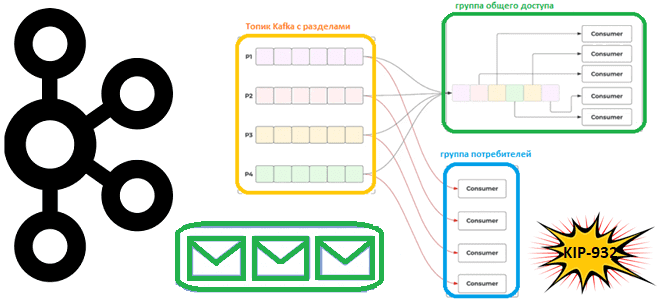
Что такое группы общего доступа для потребителей, чем это отличается от существующей концепции группы потребителей, почему в Apache Kafka появляются очереди и чем это улучшит потоковую обработку событий. Что такое KIP-932: группы общего доступа потребления данных из Apache Kafka Напомним, группы потребителей в Kafka предназначены для повышения надежности упорядоченной доставки...
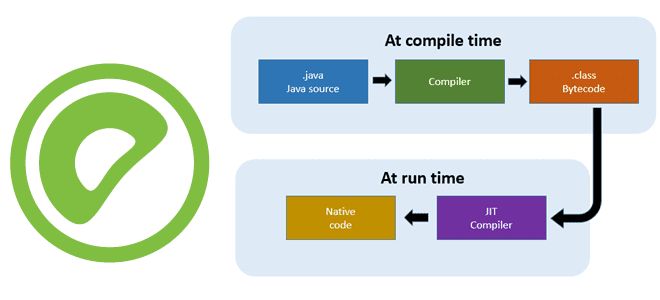
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...
Как использовать функции обратного вызова для отладки конвейера обработки данных в Apache AirFlow, а также отправки оповещений об ошибках. Полезные примеры регистрации и мониторинга сбоев на уровне задачи и всего DAG с on_failure_callback(). Польза обратных вызовов Apache AirFlow на примере on_failure_callback По мере роста и усложнения конвейеров данных, построенных с...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Недавно мы писали про источники данных Apache Flink. Сегодня рассмотрим, как создать и протестировать собственный источник данных для их обработки в распределенном приложении. Создание своего источника данных в Apache Flink Напомним, источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных,...