 592
592 
Содержание
Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow.
Аналитика системных метрик Apache AirFlow с ADA и Amundsen
ADA — это микросервис, созданный для получения ключевых аналитических показателей задач и DAG из экземпляра базы данных AirFlow. Благодаря тесной интеграции с фреймворком, ADA может извлекать данные из базы данных и анализировать их. Подключив ADA к своему экземпляру, дата-инженер получит значения системных метрик, чтобы принимать управленческие решения на основе исторического поведения DAG. ADA абсолютно не зависит от Python-кода задач и операторов AirFlow, поскольку является средством выполнения SQL-запросов к базе данных метаданных, где хранятся сведения о задачах и DAG. Это пригодится, например, чтобы оценить длительность выполнения процесса и, если она превышает допустимые лимиты, принять оперативные меры.
Аналогичные задачи аналитики системных метрик Apache AirFlow можно решить с помощью Amundsen, механизма обнаружения данных и метаданных. Он имеет наглядные веб-GUI, где отображаются сведения по наиболее востребованным шаблонам, например, таблицы с большим количеством запросов. Амундсен включает в себя следующие компоненты:
- amundsenfrontendlibrary— служба внешнего интерфейса, представляющая собой приложение Flask с интерфейсом React;
- amundsensearchlibrary— служба поиска, использующая возможности Elasticsearch для поиска метаданных внешнего интерфейса;
- amundsenmetadatalibrary– служба метаданных, которая использует графовую базу данных Neo4j или Apache Atlas в качестве постоянного уровня для предоставления различных метаданных;
- amundsendatabuilder– библиотека приема данных для построения графа метаданных и поискового индекса. Пользователи могли либо загрузить данные с помощью Python-скрипта с библиотекой или с помощью DAG AirFlow, импортирующей библиотеку.
- amundsencommon– общая библиотека Amundsen с кодом микросервисов;
- amundsengremlin– библиотека для преобразования объектов модели в вершины и ребра в выражения языка обхода графов Gremlin для загрузки данных в серверную часть AWS Neptune;
- amundsenrds– модели ORM для поддержки реляционной базы данных в качестве внутреннего хранилища метаданных в Amundsen. Схема в моделях ORM следует логике моделей построения данных и используется в конструкторе данных и библиотеке метаданных для хранения и поиска метаданных в реляционных базах данных.
Ditto, gusty и Viewflow для работы с DAG
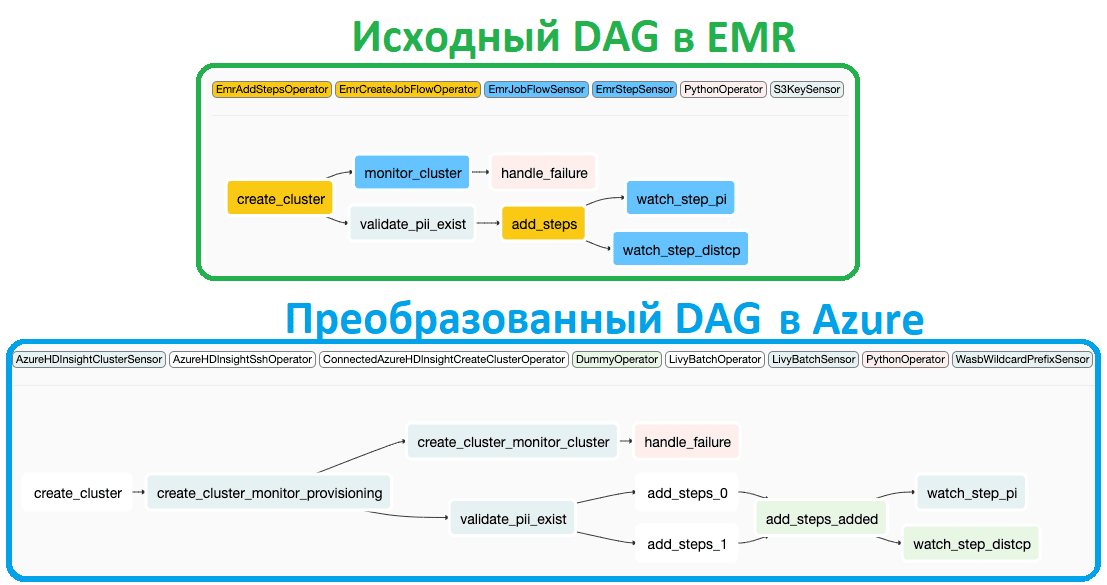
Ditto — это фреймворк, который позволяет преобразовывать DAG AirFlow, изоморфную для другой платформы оркестрации рабочих процессов, чтобы поддерживать одну кодовую базу и запускать DAG AirFlow в разных средах выполнения. Ditto предназначен не для однократного преобразования, а для непрерывного и параллельного развертывания DAG. В основе Ditto лежит графовая библиотека для работы с расширяемыми API. Также этот фреймворк поставляется с готовой поддержкой преобразования EMR в HDInsight. Следующий участок кода показывает пример использования Ditto для преобразования DAG AirFlow из AWS EMR:
ditto = ditto.AirflowDagTransformer(DAG(
dag_id='transformed_dag',
default_args=DEFAULT_ARGS
), transformer_resolvers=[
AncestralClassTransformerResolver(
{
EmrCreateJobFlowOperator: EmrCreateJobFlowOperatorTransformer,
EmrJobFlowSensor: EmrJobFlowSensorTransformer,
EmrAddStepsOperator: EmrAddStepsOperatorTransformer,
EmrStepSensor: EmrStepSensorTransformer,
EmrTerminateJobFlowOperator: EmrTerminateJobFlowOperatorTransformer,
S3KeySensor: S3KeySensorBlobOperatorTransformer
}
)], transformer_defaults=TransformerDefaultsConf({
EmrCreateJobFlowOperatorTransformer: TransformerDefaults(
default_operator= hdi_create_cluster_op
)}))
ditto.transform(emr_dag)
Python-библиотека gusty позволяет управлять группами DAG, группами задач и задач AirFlow, представленными в виде любого количества файлов YAML, Python, SQL, Jupyter Notebook или R Markdown. Каталог файлов задач мгновенно преобразуется в DAG путем передачи пути к файлу функции create_dag. Также библиотека gusty управляет зависимостями внутри одной DAG и внешними зависимостями от задач в других DAG для каждого определенного пользователем файла задачи. Дата-инженеру нужно предоставить список внутренних или внешних зависимостей, и gusty автоматически установит зависимости каждой задачи и создаст внешние сенсоры задач для любых перечисленных внешних зависимостей. Пакет работает как с 1-ой, так и со 2-ой версией, позволяя также обнаруживать и генерировать зависимости через атрибут объекта задачи dependencies. Это позволяет устанавливать зависимости динамически. Например, если оператор запускает SQL-запрос, из него можно извлечь имена таблиц и прикрепить их список к атрибуту оператора dependencies. Если эти имена таблиц, являются идентификаторами задач в DAG, gusty автоматически установит эти зависимости. Объекты DAG и TaskGroup также создаются фреймворком автоматически, просто будучи каталогами и подпапками соответственно. Путь к каталогу в функции create_dag станет DAG, а любая подпапка в этой DAG по умолчанию будет преобразована в TaskGroup. Вот пример использования функции create_dag с gusty:
from datetime import timedelta
from airflow.utils.dates import days_ago
from gusty import create_dag
dag = create_dag(
'/usr/local/airflow/dags/hello_world',
description="A DAG created without any metadata",
schedule_interval="1 0 * * *",
default_args={
"owner": "airflow",
"depends_on_past": False,
"start_date": days_ago(1),
"email": "airflow@example.com",
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
},
task_group_defaults={
"tooltip": "This is a task group tooltip",
"prefix_group_id": True
}
)
В заключение отметим, что вместе с gusty можно использовать традиционные методы создания DAG AirFlow, выбирая лучший подход для каждого конкретного случая.
Еще одним полезным инструментом для работы с DAG является Viewflow — платформа, построенная на основе Airflow, которая позволяет создавать материализованные представления и автоматически создает группы DAG и задачи Airflow на основе файлов SQL, Python, R или Rmd. Обычно каждый из этих файлов отвечает за материализацию нового представления. Дата-инженеру достаточно лишь написать определение представления, а все остальное сделает Viewflow.
Одной из основных особенностей Viewflow является его способность управлять зависимостями задач, т.е. представлениями, используемыми для создания другого представления. Viewflow может автоматически извлекать из кода, например, SQL-запроса или Python-скрипта, внутренние и внешние зависимости. Внутренняя зависимость — это представление, принадлежащее той же DAG, что и создаваемое представление. Внешняя зависимость — это представление, принадлежащее другой DAG. Преимущества автоматического управления зависимостями упрощает работу дата-инженера, избавляя от необходимости вручную составлять список зависимостей, что довольно муторно и чревато ошибками. Также это гарантирует, актуальность представлений, т.е. ни одно из них не будет построено на устаревших данных, поскольку все зависимые представления обновляются заранее. Пока Viewflow поддерживает представления SQL, Python, R и Rmd, а также базы данных PostgreSQL и Redshift в качестве места назначения. Чтобы писать представления в базы данных, Viewflow использует соединение AirFlow, указанные в connection_id.
Viewflow основан на следующих компонентах:
- Парсер (синтаксический анализатор), который преобразует исходный файл (SQL, Rmd, Python) с метаданными представления (владелец, схема данных, описание самого представления и его столбцов, а также имя соединения AirFlow для подключения к базе данных) и код представления в определенную структуру данных Viewflow. Эта структура данных используется другими компонентами Viewflow: адаптером и генератором зависимостей.
- Адаптер представляет собой уровень перевода представленийViewflow в их соответствующий аналог AirF Он использует объекты структуры данных, созданные синтаксическим анализатором, для создания объекта задачи AirFlow, т.е. оператора.
- Генератор зависимостей использует объекты структуры данных синтаксического анализатора для установки внутренних и внешних зависимостей к объекту задачи AirFlow, созданному адаптером.
Таким образом, использование внешних компонентов, интегрированных в экосистему Apache AirFlow позволяет повысить эффективность работы дата-инженера при проектировании и отладке конвейеров обработки данных.
Узнайте больше про использование Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

