 1449
1449 
Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления групповых служб.
Как устроен Apache Zookeeper: архитектура и принцип работы
Начнем с того, что Apache Zookeeper – это, прежде всего, инструмент Big Data администратора, который следит за синхронизацией и координацией всего кластера распределенных приложений. По сути, Зукипер представляет собой распределенное хранилище ключ-значение (key-value), где пространство ключей образует древовидную иерархию как в файловой системе, а значения могут содержаться в любом узле иерархии (только в листьях) [1].
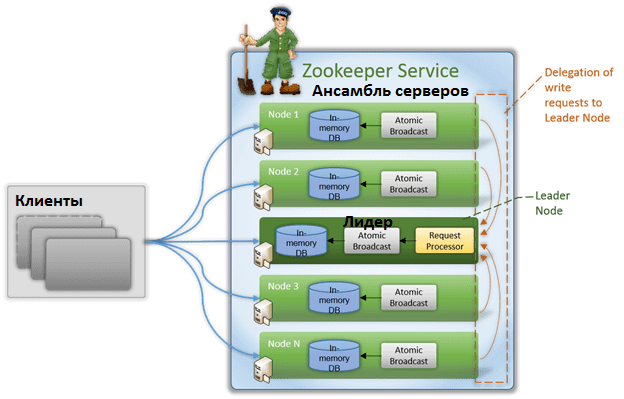
Кластер Zookeeper поддерживает клиент-серверную архитектуру, основанную на следующих компонентах [1]:
- клиент – это один из узлов в кластере распределенного приложения, который имеет двустороннюю связь с сервером. Периодически, в течение всей сессии подключения к серверу, клиент посылает ему сообщение (heartbeat), которое сигнализирует о работе.
- сервер – это один из узлов ZooKeeper, который предоставляет все службы клиенту и посылает ему подтверждение при подключении. Если от сервера нет ответа, клиент автоматически перенаправляет сообщение другому серверу.
- ансамбль – группа серверов Зукипер. Минимальный размер ансамбля составляет 3 сервера.
- лидер (leader) – сервер, который выполняет все операции записи и запускает автоматическое восстановление при отказе любого из подключенных узлов. Лидеры выбираются при запуске служб.
- последователь (подписчик, follower) — сервер, который следует инструкциям лидера и реплицирует себе его данные. Благодаря множеству подписчиков, операции чтения выполняются быстрее, т.к. считывать данные можно с любого узла.
Таким образом, можно сказать, что ZooKeeper имитирует виртуальную древовидную файловую систему из взаимосвязанных узлов, которые представляют собой совмещенное понятие файла и директории. Каждый узел этой иерархии (znode) может одновременно хранить данные и иметь подчиненные узлы (потомки). В системе существует два типа узлов [2]:
- постоянные (persistent), которые сохраняются на диск и никогда не пропадают;
- эфемерные (недолговечные), которые создаются в рамках конкретной сессии подключения клиента к серверу и существуют только во время ее действия. Такие узлы не имеют потомков, а представляют собой объект, в котором можно временно сохранить какие-то данные.
Вообще Zookeeper больше ориентирован на чтение, чем на запись. Все операции записи выполняются строго последовательно в одном потоке и на одном сервере (лидере). Чтения могут выполняться с реплик (последователей или подписчиков). На стороне клиента реализуется строгая последовательность операций: сначала выполнится запись, а только потом — чтение. Благодаря такому принципу Zookeper позволяет создавать предсказуемые Big Data системы асинхронной работы. Например, Яндекс.Почта еще в 2014 году использовала Зукипер для гарантированной доставки сообщений [3]. Также этот инструмент применяется для создания сервисов распределенных блокировок [4] и управления конфигурацией кластера, когда централизация данных через Zookeeper запрещает или разрешает работу какой-либо службы [2].
5 главных недостатков Зукипер
При всех своих достоинствах, практическое использование Зукипер ограничено следующими недостатками [5]:
- база данных Zookeeper должна помещаться в оперативную память сервера, иначе значительно снижается производительность;
- сильная зависимость от времени таймаута сессии – при некорректной настройке этого параметра возможны отказы некоторых узлов в случае увеличения нагрузки на кластер. Обычно пользователи стремятся уменьшить время сессии, которое по умолчанию равно 30 секунд. Это делается, чтобы эфемерные (недолговечные) узлы, созданные на время конкретной сессии, удалялись быстрее. Однако, как мы уже упомянули, при повышении нагрузки на распределенную Big Data систему Zookeeper ведет себя менее стабильно.
- сложность масштабирования – добавление новых узлов в кластер значительно снижает производительность операций записи. Напомним, в ансамбле Zookeeper, согласно требованию протокола ZAB (ZooKeeper Atomic Broadcast), который обеспечивает гарантию порядка репликации, обрабатывает выбор лидера и восстановление неисправных узлов [6], число серверов должно быть нечетным. Обычно используется ансамбль из 3-х узлов, а расширение его до 5, 7 или 9 серверов снизит производительность. Хорошая новость в том, что можно использовать механизм наблюдателей, чтобы уведомит клиента об изменениях в ансамбле серверов ZooKeeper, имитируя таким образом операцию чтения [1].
- максимальный размер данных в пространстве имен любого узла ограничен 1MB [1].
- число узлов в листинге потомков ограничено максимальным размером пакета данных, который сервер может отправить клиенту (jute.maxbuffer), равным 4МБ. Если перечень потомков узла Zookeeper не помещается в один пакет, то невозможно получить сведения о них напрямую. Это ограничение обходится с помощью иерархических «псевдоплоских» списков аналогично построению кэша в файловой системе, когда имена объектов разбиваются на части и составляют свою иерархическую структуру.
Также разработчики Big Data систем, сталкивающиеся с Зукипер, отмечают, что API этой службы централизации достаточно низкоуровневый, требует много времени и внимания для корректного использования на практике. Впрочем, эта проблема решается с помощью специальных библиотек, упрощающих работу с API Zookeeper. В частности, одной из них является Apache Curator, который поддерживает схемы данных, миграции, тестовые сервера и кластера, а также предоставляет целый набор решений для поддержки очередей. Но, что особенно важно, Curator в разы сокращает количество программного кода, делая его очень читабельным и понятным [5].
В заключение отметим еще раз, что, несмотря на ряд альтернатив (Atomix, Jocko, Consul, Self-Managed Metadata Quorum), Zookeeper до сих пор остается неотъемлемой частью кластеров Apache Hadoop, HBase и Kafka. Поэтому почти каждый администратор Big Data, DevOps-инженер и разработчик распределенных систем сталкивается с этой службой централизации. Чтобы эффективно работать с ней, необходимо знать возможные проблемы использования этого сервиса и современные методы обхода его ограничений. Все это и другие тонкости администрирования кластеров для хранения и обработки больших данных вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Администрирование кластера Hadoop
- Hadoop для инженеров данных
- Администрирование кластера Kafka
- Администрирование кластера HBase
Источники
- https://ru.bmstu.wiki/Apache_ZooKeeper
- https://habr.com/ru/company/yandex/blog/234335/
- https://habr.com/ru/company/yandex/blog/219617/
- https://habr.com/ru/post/144708/
- https://habr.com/ru/post/334680/
- https://distributedalgorithm.wordpress.com/2015/06/20/architecture-of-zab-zookeeper-atomic-broadcast-protocol/

