
С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog.
Что такое Apache Datasketches и зачем это нужно
В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения точных результатов. Например, различные счетчики, часто встречающиеся элементы, соединения, матричные вычисления и анализ графов. Причем на практике далеко не всегда нужно получить точное значение, иногда для принятия решения достаточно приближенного вычисления. В таких случаях можно применить специализированные алгоритмы, называемых потоковыми эскизами, которые дают результаты намного быстрее и с математически доказанными границами ошибок. Для анализа данных в реальном времени подобные эскизы отлично подходят. Например, эта технология помогла Yahoo сократить время обработки данных с дней до минут для нескольких внутренних платформ.
Реализовать такой подход эскизов данных позволяет Apache DataSketches — высокопроизводительная библиотека стохастических потоковых алгоритмов с открытым исходным кодом. Эскизы — это небольшие программы с отслеживанием состояния, которые обрабатывают массивные данные в виде потока и могут дать приблизительные ответы с математическими гарантиями на сложные в вычислительном отношении запросы намного быстрее, чем традиционные точные методы. Библиотека DataSketches была специально разработана для производственных систем, которые должны обрабатывать большие объемы данных. Она включает адаптеры для Apache Hive, Pig и PostgreSQL, а также для совместимых двоичных представлений на разных языках (Java, C ++, Python) и платформах.
Эскизы выполняются очень быстро, поскольку алгоритмы в библиотеке DataSketches обрабатывают данные за один проход и подходят как для реального времени, так и для пакетной обработки. Помимо высокой скорости обработки огромного объема данных, проектирование системы на основе эскизов позволяет упростить ее архитектуру и сократить общие вычислительные ресурсы, необходимые для решения сложных вычислительных задач.
Эскизы отличаются от традиционных методов выборки тем, что исследуют все элементы потока, касаясь каждого элемента только один раз, и часто рандомизацию, которая составляет основу их стохастической природы. Это делает эскизы идеальным вариантом для потоковой обработки в реальном времени.
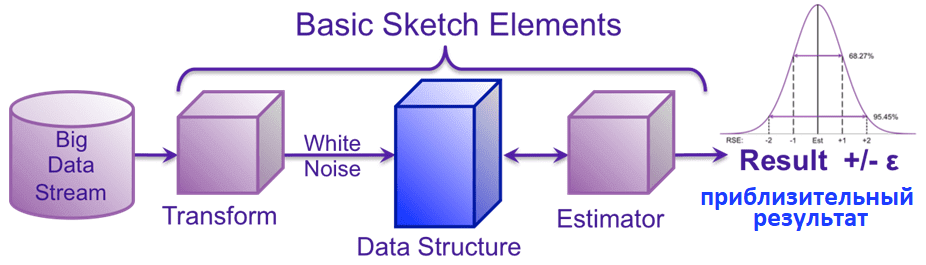
Например, первый этап процесса создания эскизов с подсчетом различных значений представляет собой преобразование, которое придает входному потоку данных свойство белого шума или равномерное распределение значений. Обычно это достигается путем скоординированного хеширования входных уникальных ключей и последующей нормализации результата до однородного случайного числа от нуля до единицы.
Второй этап эскиза представляет собой структуру данных, которая следует набору правил для сохранения небольшого набора хеш-значений, полученных на этапе преобразования. Эскизы также отличаются от простых схем выборки тем, что размер эскиза часто имеет настраиваемую фиксированную верхнюю границу, что обеспечивает простое управление памятью.
Последним элементом процесса создания эскиза является набор алгоритмов оценки, которые по запросу исследуют структуру данных эскиза и возвращают значение результата. Это значение результата будет приблизительным, но будет иметь четко установленные и математически подтвержденные границы распределения ошибок.
Эскизы данных обычно характеризуются следующими свойствами:
- Небольшой размер – на несколько порядков меньше потока необработанных входных данных.Эскизы реализуют сублинейные алгоритмы, размер которых увеличивается гораздо медленнее, чем размер входного потока. Некоторые эскизы имеют конечную верхнюю границу размера, которая не зависит от размера входного потока.
- Высокая скорость обработки, т.к. время обновления не зависит от размера или порядка входного потока. Для вычислений эскизу достаточно увидеть каждый элемент в потоке данных только один раз.
- Высокая параллелизуемость. Структуры данных эскиза являются дополнительными, поскольку их можно объединять без потери точности.
- Приблизительный характер. Например, для эскизов с уникальным подсчетом относительные границы ошибок являются функцией от заданного размера.
Технология создания эскизов данных использует HyperLogLog – вероятностный алгоритм для приблизительного подсчета уникальных элементов в мультимножестве. Вычисление точной кардинальности множества требует памяти пропорциональной самой кардинальности, что не приемлемо при работе с большими объёмами данных. Вероятностные алгоритмы вычисления кардинальности, такие как HyperLogLog, потребляют намного меньше памяти, вычисляя приближенное значение кардинальности. Например, HyperLogLog способен вычислить приближенное значение кардинальности 10^9 с погрешностью в 2 %, используя 1.5 килобайт памяти.
Таким образом, предложенный в 2007 году, HyperLogLog решает проблему оценки мощности в прикладной математике, вместо среднего геометрического для усреднения результата используя среднее гармоническое – величину, обратную среднему значению обратных величин.
Этот алгоритм может оценить количество уникальных значений в очень большом наборе данных, используя мало памяти и времени. Алгоритм используется в key-value NoSQL-СУБД Redis, а также других нереляционных базах и хранилищах данных петабайтного масштаба, например, Amazon Redshift , Presto, BigQuery и Apache Druid. Библиотека Apache Datasketches также использует HyperLogLog. Познакомившись с Apache Datasketches, далее рассмотрим, как эта стохастическая библиотека улучшает Spark Structured Streaming.
Зачем это в Spark Streaming?
Использование библиотеки Datasketches для вычисления приблизительного количества отдельных объектов дает несколько преимуществ по сравнению с подсчетом целых чисел прямого результата, возвращаемым функцией approx_count_distinct, ранее доступной в Apache Spark и среде выполнения Databricks. Например, можно сохранять эскизы в хранилище и при необходимости сканировать их позже, чтобы выполнять дальнейший анализ данных или проводить вычисления без необходимости пересчитывать отдельные значения с нуля. Это экономит время и вычислительные ресурсы, поскольку приблизительное количество уникальных экземпляров доступно для последующих запросов.
Еще одним преимуществом использования буферов эскизов является их гибкость при работе с различными сценариями. Эскизы можно легко комбинировать или объединять с помощью операций объединения, что позволяет пользователям объединять несколько буферов эскизов в один эскиз. Такая гибкость обеспечивает масштабируемую обработку больших наборов данных и распределенных систем, поскольку эскизы можно создавать независимо, а затем эффективно объединять. Эти буферы эскизов дают пользователям возможность выполнять над эскизами расширенные операции над наборами, такие как объединения, пересечения и различия, открывая новые возможности для сложных задач анализа данных. В общем случае, приблизительный подсчет особенно полезен в таких случаях использования инкрементального обновления, где для приложений с низкой задержкой, таких как информационные панели, допускается небольшая погрешность в угоду более быстрого выполнения запроса.
Для этого в библиотеке Dataksetches есть функция hll_sketch_agg, которая подсчитывает количество уникальных значений в столбце. Используя алгоритм HyperLogLog, эта функция обеспечивает вероятностную аппроксимацию уникальности, выводя двоичное представление как буфер эскиза. Этот буфер эскизов очень эффективен для долгосрочного хранения и персистентности. Можно интегрировать hll_sketch_agg в свои запросы и с помощью полученных буферов вычислить приблизительное количество уникальных значений. Эта функция hll_sketch_estimate является мощным дополнением к hll_sketch_agg. С помощью входных данных буфера эскизов, созданного с помощью hll_sketch_agg, функция hll_sketch_estimate обеспечивает оценку количества уникальных элементов, позволяя принимать обоснованные решения на основе надежных приближений.
Функция hll_union позволяет объединить два эскиза в один, когда надо агрегировать данные по разным столбцам или наборам данных. Включив hll_union в запросы, можно получить исчерпывающую информацию и вычислить приблизительное количество уникальных пользователей с помощью hll_sketch_estimate. Так можно создавать буферы эскизов и экспортировать их в управляемые таблицы, чтобы избежать повторных вычислений в дальнейшем, используя функцию hll_sketch_agg. Все эти новые функции Apache Spark SQL и Databricks Runtime основаны на библиотеке Apache Datasketches, которая поддерживается в Spark с версии 3.5.0.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

