
Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...
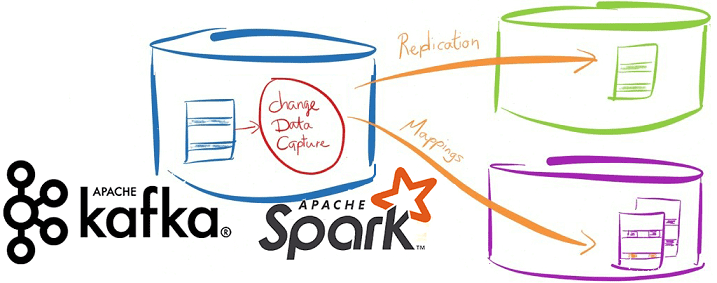
Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых и других транзакций. Зачем нужны потоковые конвейеры транзакционной обработки Big Data на...

В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений....

Продолжая разговор про оптимизацию Apache Spark и повышение эффективности Big Data приложений, сегодня рассмотрим способы ускорения Shuffle-операций в Spark SQL, разберем, чем хороши широковещательные JOIN-операции и как количество разделов влияет на производительность запросов в распределенных приложениях аналитики больших данных. 4 способа оптимизации Shuffle-операций При аналитике больших данных с помощью Apache...

Недавно мы рассматривали, как повысить производительность конвейеров Apache Spark и повысить скорость распределенных приложений для аналитики больших данных. Сегодня разберемся, почему тормозят отдельные Spark-задачи и как их ускорить. Читайте далее про инициализацию Спарк-контекста, предзагрузку артефактов и применение клиентского режима. Почему некоторые задачи в быстром Apache Spark выполняются так медленно Напомним,...

В заключение цикла статей о сравнении Apache Kafka с Pulsar, сегодня мы перечислим, когда следует предпочесть второй вариант для построения распределенных масштабируемых систем потоковой аналитики больших данных. Также читайте далее, с какими ограничениями придется мириться в случае выбора этого Big Data фреймворка. 5 случаев, когда Apache Pulsar лучше Kafka При...

Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все...

Оставив за рамками этой статьи бенчмаркинговые войны по оценке производительности Apache Pulsar в сравнении с Kafka и RabbitMQ, сегодня разберем 5 популярных мифов о превосходстве молодого Пульсар над зрелой Кафка – платформой потоковой обработки событий с точки зрения администрирования и эксплуатации. Читайте далее, правда ли управлять кластером Pulsar проще, чем...

Продолжая разбирать сходства и различия Apache Pulsar с Kafka и RabbitMQ, сегодня попытаемся выяснить, какой Big Data фреймворк все-таки лучше: погрузимся в особенности бенчмаркинговых исследований, сравнивающих эти платформы. Читайте далее, почему не стоит безоговорочно доверять локальным бенчмаркинг-тестам оценки производительности и какие факторы действительно нужно учитывать при выборе фреймворка для разработки...

Недавно мы разбирали, что такое Apache Pulsar: архитектуру, принципы работы, сходства и различия с Kafka и RabbitMQ. В продолжение этого разговора, сегодня рассмотрим основные мифы и их опровержения в горячем споре о технологиях Big Data. Читайте далее про холивар Apache Kafka vs Pulsar vs RabbitMQ: что лучше выбрать для построения...