Почему планировщик Apache AirFlow чувствителен к всплескам рабочих нагрузок, из-за чего тормозит база данных метаданных, как исправить проблемы с файлом DAG, лог-файлами и внешними ресурсами: разбираемся с ошибками пакетного оркестратора и способами их решения. Проблемы с планировщиком Хотя Apache AirFlow позиционируется как довольно простой фреймворк для оркестрации пакетных процессов с...
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...
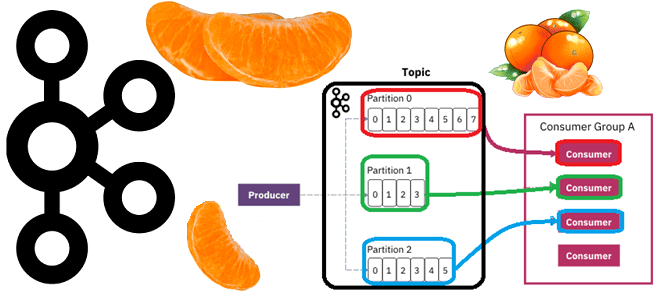
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...

Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...
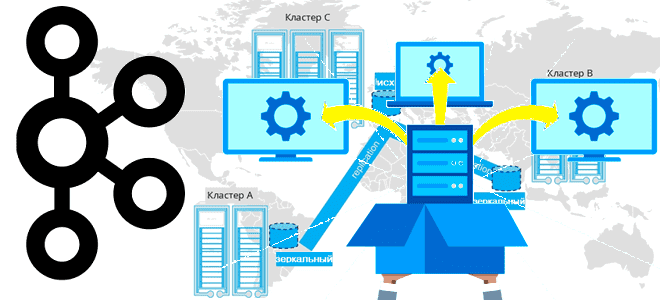
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора. Критерии выбора топологии репликации кластера Apache Kafka Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных...