Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...

В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование. Что из...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...
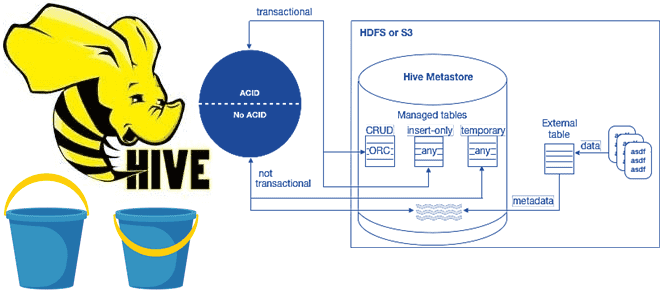
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

Чтобы самостоятельное обучение по Hbase стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с этой СУБД в этой распределенной СУБД, включая ее особенности работы и архитектуру. Тест по основам работы с СУБД Hbase для новичков Для тех, кто начинает самостоятельное обучение по Apache Hbase, мы предлагаем...

В этой статье мы поговорим про основные базовые операции распределенной СУБД Hbase. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в Hbase и их особенности. Основные CRUD-операции в распределенной СУБД Hbase HBase - это распределенная NoSQL столбцово-ориентированная (данные представлены...
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
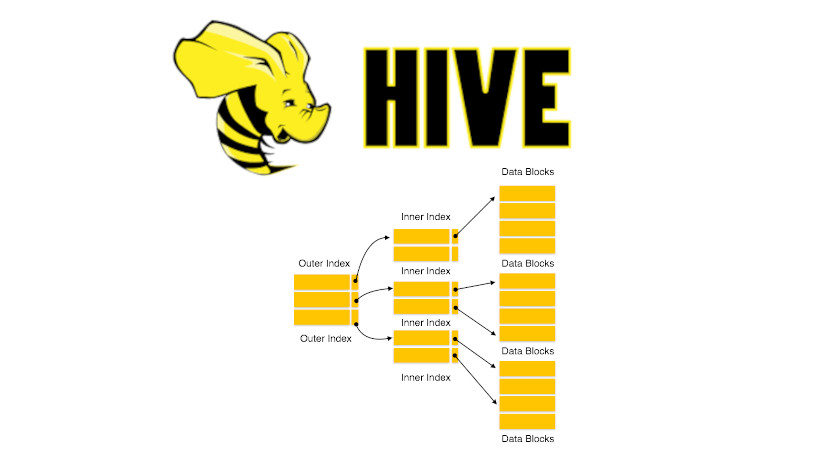
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами. Как работает механизм группировки и сортировки данных: особенности обработки Big Data...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

В прошлый раз мы говорили про особенности работы и создания представлений в Impala. Сегодня поговорим про модифицированный вывод в распределенной SQL-платформе Apache Impala. Читайте далее про особенности модификации вывода записей в Impala, включая базовые операторы, которые применяются для вывода конкретных записей. Базовые SQL-операторы для модификации вывода записей в распределенной СУБД...