
Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с драйвером-коннектором JDBC в этой распределенной СУБД, включая его особенности работы и взаимодействия с Java-приложениями. Тест по основам работы драйвера JDBC для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы...

В прошлый раз мы говорили про особенности работы с основными join-операциями в Hive. Сегодня поговорим про использование JDBC-драйвера при работе в распределенной Big Data платформе Apache Hive. Читайте далее про особенности использования этого драйвера при работе в распределенной среде Hive. Использование драйвера JDBC в распределенной СУБД Apache Hive Драйвер JDBC...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
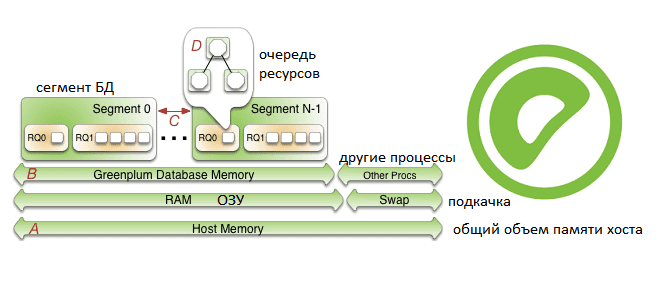
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...

Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с механизмом представлений, включая их структуру и особенности. Тест по основам работы с представлениями Impala для новичков Для начинающих самостоятельное обучение по Apache Impala мы предлагаем простой интерактивный тест по этой Big Data...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...
Однажды мы уже разбирали, способна ли Apache Kafka заменить собой базы данных в мире Big Data. Сегодня рассмотрим обратную постановку этой задачи: можно ли реализовать постоянный обмен сообщениями в стиле Kafka с помощью СУБД. Читайте далее, что общего у Kafka с базой данных, чем они отличаются и почему попытки заменить...

В этой статье мы поговорим про основные базовые операции в МонгоДБ. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в MongoDB и их особенности. Основные операции СУБД MongoDB Прежде всего отметим, что MongoDB - это документно-ориентированная (данные хранятся в...

В этой статье мы поговорим про работу с представлениями в Apache Impala. Также рассмотрим структуру представлений в этой SQL-подобной распределенной СУБД, входящей в экосистему Hadoop. Читайте далее про особенности работы с представлениями в Impala, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки Big Data. Как работает...