
Сегодня мы поговорим про продукты компании Arenadata – отечественного разработчика дистрибутива Apache Hadoop (ADH), массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB) и других Big Data платформ. Читайте в нашей статье, где внедрены эти решения и какую пользу они уже успели принести бизнесу. Облака и банк: 3...
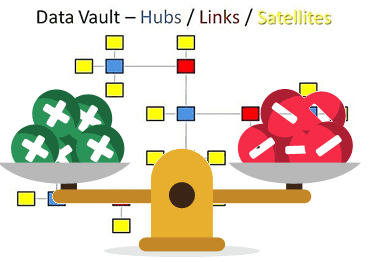
В этой статье мы рассмотрим основные плюсы и минусы Data Vault – популярного подхода к моделированию сущностей при проектировании корпоративных хранилищ данных (КХД). Читайте сегодня, почему промежуточные базы перед витринами данных упрощают ETL-процессы, за счет чего обеспечивается отсутствие избыточности и как много таблиц могут усложнить жизнь архитектора Big Data. Чем...
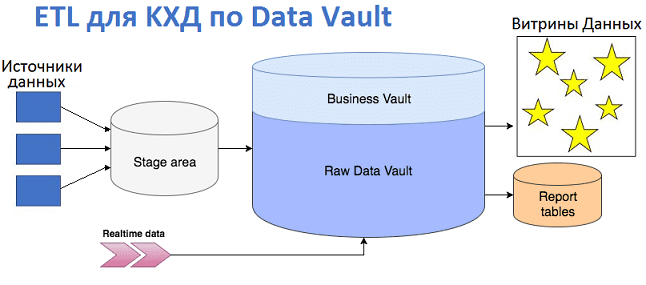
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...
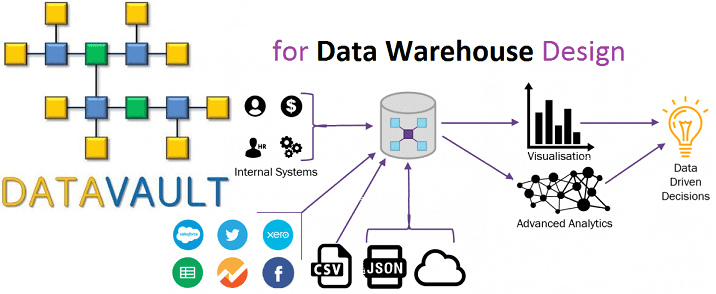
Вчера мы рассмотрели, что такое Data Vault, почему возникла эта модель и чем она полезна при проектировании архитектуры корпоративных хранилищ данных (КХД) и озер данных (Data Lake). Сегодня разберем ключевые понятия Data Vault и поговорим про возможности Data Vault 2.0 для области больших данных (Big Data). Ключевые понятия Data Vault...
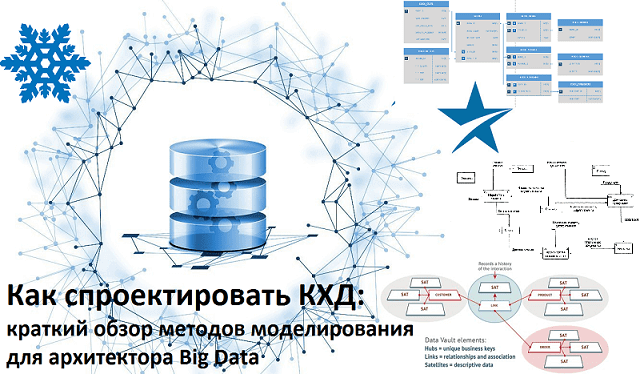
Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...
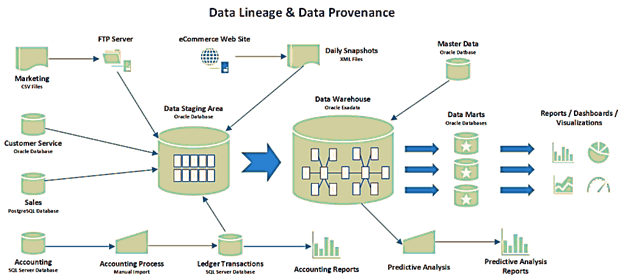
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...

Управление данными не сводится к выделению роли дата стюарда и обеспечению Data Quality. Сегодня мы расскажем, что такое мастер-данные, как искусственный интеллект помогает решать проблемы управления НСИ и почему эффективный Master Data Management (MDM) особенно важен в мире Big Data. Что такое мастер-данные или зачем управлять НСИ Начнем с определения:...
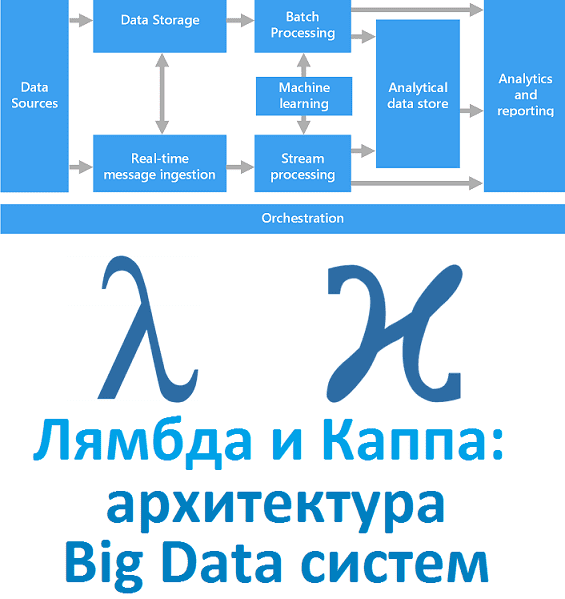
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...