 750
750 
Содержание
В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных.
Достоинства и недостатки облачных DWH
КХД может быть реализовано не только в локальном датацентре предприятия. Облачные вычисления, когда процесс хранения и обработки данных выполняется на стороне внешнего сервиса или платформы, занимают свою нишу и в области Data Warehouse. Основными преимуществами, которые получают компании от использования подобных решений, считаются следующие [1]:
- быстрота развертывания за счет использования типизированных шаблонов, экономия времени на проектирование и реализацию локального продукта;
- отказоустойчивость благодаря геораспределенному реплицированию, резервному копированию и другим способам обеспечения высокой доступности, которые гарантирует облачный провайдер;
- масштабируемость, а также гибкость при подключении новых источников и потребителей данных благодаря виртуализации и открытым интерфейсам внутриплатформенного взаимодействия.
Недостатками облачных DWH-сервисов можно назвать некоторые сложности в организации ETL-процессов из-за того, что большинство технических подробностей «скрыто под капотом». Также пользователи, привыкшие к локальным решениям, могут опасаться инцидентов с нарушением cybersecurity на стороне SaaS/PaaS-провайдера. Тем не менее, облачные DWH становятся все более популярными. Например, в сентябре 2019 года отечественная компания Mail.ru Group сообщила о запуске своего облачного DWH-сервиса на базе колоночной СУБД ClickHouse, изначально разработанной другим российским ИТ-гигантом, Яндексом [2].
На международном рынке облачных DWH-сервисов наиболее распространены следующие решения [3]:
- Amazon Redshift;
- Google BigQuery;
- Azure Synapse Analytics от
Эти и другие подобные DWH-сервисы имеют похожую архитектуру, основные компоненты которой мы рассмотрим далее.
Как устроены облачные КХД: расширенная LSA архитектура и Big Data
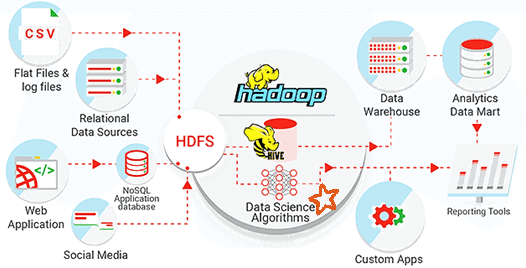
Облачные КХД, как и локальные решения, поддерживают слоеную LSA-архитектуру. При этом реляционный подход к организации хранилища дополняется возможностями работы с Big Data: разноформатной информацией из озер данных (Data Lake), режимами поточной и пакетной обработки, а также средствами расширенной аналитики больших данных с помощью алгоритмов машинного обучения (Machine Learning). Для этого используются следующие архитектурные концепции [4]:
- колоночные СУБД, которые позволяют искать значения по отдельным столбцам и извлекать только нужные данные, что особенно востребовано при работе с большими данными и генерации построении OLAP-кубов в BI-системах. Также такая организация хранения данных существенно экономит дисковое пространство.
- технологии массово-параллельной обработки (Massive-Parallel Processing, MPP), когда информация загружается в кластерную СУБД на все серверы сразу, при этом физические узлы не имеют общих ресурсов (shared-nothing). Благодаря этому возможно линейное масштабирование и высокая производительность.
- подключаемые сервисы расширенной аналитики больших данных на базе алгоритмов Machine Learning за счет фреймворка Apache Spark MLLib, уже развернутого на стороне облачного провайдера;
- гибридный подход, когда локальные структуры данных (on-premise) объединяются с облачными сервисами;
- интеграция с большими данными, которые хранятся в HDFS Data Lake, с помощью инструментов SQL-on-Hadoop, таких как Apache Hive или Cloudera Impala;
- лямбда-архитектура, когда потоковая обработка данных в режиме реального времени объединяется с результатами пакетной аналитики исторических данных из Data Lake.
При том, что SaaS/PaaS-провайдеры предлагают типовые DWH-решения, на практике нельзя обойтись без проектирования КХД. В следующей статье мы расскажем, как архитектор Data Warehouse разрабатывает дизайн корпоративного хранилища данных и рассмотрим наиболее популярные методы моделирования. А как реализовать современное КХД, интегрированное с технологиями больших данных и машинного обучения, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Источники

