 637
637 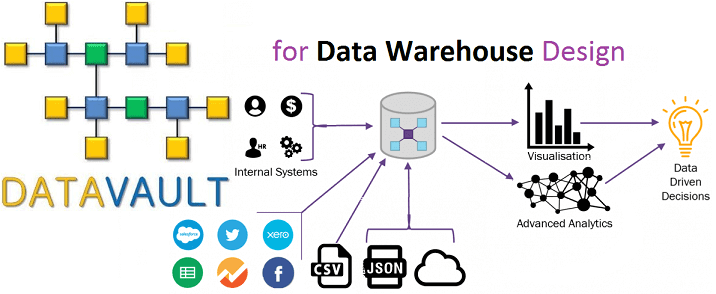
Содержание
Вчера мы рассмотрели, что такое Data Vault, почему возникла эта модель и чем она полезна при проектировании архитектуры корпоративных хранилищ данных (КХД) и озер данных (Data Lake). Сегодня разберем ключевые понятия Data Vault и поговорим про возможности Data Vault 2.0 для области больших данных (Big Data).
Ключевые понятия Data Vault
Напомним, Data Vault — это один из методов моделирования данных, который используется при проектировании КХД. Этот гибридный подход, впервые представленный в 2000 году, объединяет достоинства схемы «звезды» и 3-ей нормальной формы. Данный метод был придуман Дэном Линстедтом (Dan Linstedt) в процессе разработки Data Warehouse (DWH) для Министерства Обороны США и хорошо себя зарекомендовал на практике. В 2013 году Дэн Линстедт анонсировал новую версию подхода, Data Vault 2.0, доработанную с учетом технологий Big Data (NoSQL, Apache Hadoop) и новых требований к современному DWH [1].
Для сохранения простоты дизайна и обеспечения максимальной гибкости КХД используется минимум базовых понятий [2]:
- Хаб (Hub) – таблица, хранящая основное представление бизнес-сущности с функциональной позиции предметной области, например, Клиент, Продукт, Заказ и пр. Хаб содержит уникальный и неизменный бизнес-ключ – одно или несколько полей, идентифицирующих сущность в понятиях бизнеса. При потере бизнес-ключа теряется ссылка на контекст или окружающую информацию. Помимо бизнес-ключа хаб содержит мета-поля: время первоначальной загрузки сущности в хранилище (load timestamp) и ее источник (record source) – название системы, базы или файла, откуда были взяты данные. В качестве первичного ключа Хаба рекомендуется хэш бизнес-ключа, сгенерированный с помощью алгоритмов MD5 или SHA-1.
- Связь или Ссылка (Link), которая представляет отношения или транзакцию между двумя или более компонентами бизнеса, связывая их через соответствующие бизнес-ключи. Эта таблица адаптирует отношение «много ко многим» из 3NF, но решает проблемы с масштабируемостью и гибкостью. Она содержит те же метаданные, что и Хаб: временная метка загрузки и источник данных. Ключи связываемых Хабов также мигрируют в сущность Link, образуя составной ключ.
- Спутник (Satellite) – таблица с контекстной (описательной) информацией ключа Хаба. Для обеспечения гибкости структура Спутников должна позволять хранить новые или измененные детальные данные. Кроме единственного ключа родительского хаба и его контекстных данных таблица-Спутник также содержит типовой набор метаданных: load timestampи record source. Таким образом, в Спутниках можно хранить историю изменения контекста, добавляя новую запись при обновлении в системе-источнике. Чтобы упростить процесс обновления большой таблицы-сателлита можно добавить в нее поле хэш-слепок (HashDiff), полученный с помощью алгоритмов MD5 или SHA-1 от всех его описательных атрибутов. По сути, HashDiff – это хэш-функция, применённая к набору бизнес-атрибутов из таблицы-Спутника. Контекст из разных систем-источников принято хранить в отдельных таблицах-Спутниках.
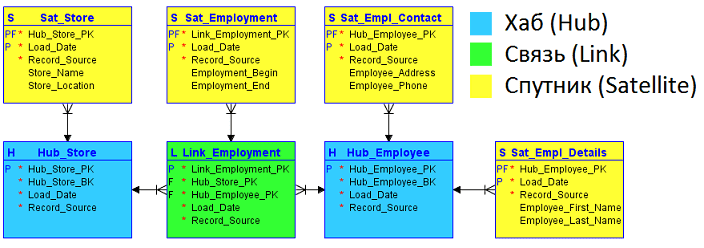
Как смоделировать Хабы, Связи и Спутники: правила построения модели
Модель Data Vault создается по следующему алгоритму [2]:
- определение Хабов на основе ключевых бизнес-сущностей и их использованию в предметной области;
- определение Ссылок через выявление возможных отношений между бизнес-ключами – и понимание контекста его работы;
- определение Спутников – моделирование контекста каждой бизнес-сущности и транзакции (Ссылки), соединяющий Хабы;
- моделирование point-in-time таблиц, производных от Спутников.
При этом необходимо придерживаться следующих правил [2]:
- ключи Хабов не могут мигрировать в другие Хабы, чтобы не нарушать гибкость и расширяемость техники моделирования Data Vault;
- Бизнес-ключи и первичные ключи Хаба никогда не меняются;
- Хабы связываются только с помощью сущностей типа Ссылка;
- Ссылка должна связывать не менее двух Хабов и может связываться с другими сущностями типа Ссылка;
- Суррогатные ключи могут использоваться в Хабах и Ссылках, но не в Спутниках;
- Ключи Хаба всегда мигрируют в Ссылки и дочерний Спутник с контекстными данными;
- Спутник может быть связан с Хабами и с Ссылками;
- Спутник всегда содержит временную метку даты загрузки (Load Date Time Stamp) или числовой внешний ключ, ссылающийся на автономную таблицу с последовательностью временных меток, например, календарь;
- Если Хаб имеет 2 или более Спутника, для удобства операций объединения (join) можно создать point-in-time таблицу;
- Спутники фиксируют только изменения без дублирования строк;
- Данные распределяются по структуре Спутников на основе типа информации и темпах ее изменения.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
15 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Дата Волт для Big Data: итоги версии 2.0
Вышеописанные правила моделирования, на первый взгляд, поддерживают только реляционную парадигму, которая не слишком коррелирует с большими данными. Однако, несмотря на часто используемое в Data Vault понятие «таблица», термин сущность скорее соответствует документу в документо-ориентированных NoSQL-СУБД [3]. Кроме того, как мы уже отметили, версия Data Vault 2.0 привнесла следующие важные для Big Data нововведения [4]:
- возможность распараллеливания загрузки ядра КХД, что позволяет использовать массивно-параллельную архитектуру (massive parallel processing, MPP) для повышения производительности;
- использование суррогатного хеш-ключа как основного способа идентификации объектов вместо инкрементальных ID. Так идентификатор строится на основе входных, а не уже имеющихся, данных. Кроме того, использование хеш-ключей позволяет напрямую интегрироваться с NoSQL-СУБД, где хеш-ключи идентифицируют объекты.
Наконец, примечательно, что методология Data Vault 2.0, как и лучшие практики Big Data, поддерживают Agile-принципы и популярные подходы управления качеством: 6 сигм, TQM и SDLC. В частности, проекты Data Vault должны иметь короткий, управляемый цикла релиза длительностью 2-3 недели. Кроме того, команды, использующие методологию Data Vault, должны легко адаптироваться к повторяемым, последовательным и измеримым проектам, соответствующим 5-му уровню модели управленческой зрелости CMMI. Благодаря этому корпоративные данные в DWH будут следовать жизненному циклу TQM (полное управление качеством, Total Quality Management), обеспечивая выполнение процессов Data Governance [5]. Например, идея метаданных (time stamp и record source), а также отслеживаемых дельт изменений в таблицах-спутниках поддержана в понятиях lineage и provenance, о которых мы рассказывали здесь.
Читайте в нашей новой статье про проектирование хранилища данных с методологией Data Vault в архитектуре Lakehouse.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
1 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
В следующей статье мы рассмотрим особенности ETL-процессов по методу Data Vault и поговорим про достоинства и недостатки этой концепции. А технические подробности организации КХД и Data Lake для эффективного хранения больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

