 1304
1304 
Содержание
В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data).
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины [1].
Принцип слоеного пирога или архитектура КХД
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа [2].
Классически LSA реализуется в виде следующих уровней [3]:
- операционный слой первичных данных(Primary Data Layer или стейджинг), на котором выполняется загрузка информации из систем-источников в исходном качестве и сохранением полной истории изменений. Здесь происходит абстрагирование следующих слоев хранилища от физического устройства источников данных, способов их сбора и методов выделения изменений.
- ядро хранилища (Core Data Layer) – центральный компонент, который выполняет консолидацию данныхиз разных источников, приводя их к единым структурам и ключам. Именно здесь происходит основная работа с качеством данных и общие трансформации, чтобы абстрагировать потребителей от особенностей логического устройства источников данных и необходимости их взаимного сопоставления. Так решается задача обеспечения целостности и качества данных.
- аналитические витрины (Data Mart Layer), где данные преобразуются к структурам, удобным для анализа и использования в BI-дэшбордах или других системах-потребителях. Когда витрины берут данные из ядра, они называются регулярными. Если же для быстрого решения локальных задач не нужна консолидация данных, витрина может брать первичные данные из операционного слоя и называется соответственно операционной. Также бывают вторичные витрины, которые используются для представления результатов сложных расчетов и нетипичных трансформаций. Таким образом, витрины обеспечивают разные представления единых данных под конкретную бизнес-специфику.
- Наконец, сервисный слой (Service Layer) обеспечивает управление всеми вышеописанными уровнями. Он не содержит бизнес-данных, но оперирует метаданными и другими структурами для работы с качеством данных, позволяя выполнять сквозной аудит данных (data lineage), использовать общие подходы к выделению дельты изменений и управления загрузкой. Также здесь доступны средства мониторинга и диагностики ошибок, что ускоряет решение проблем.
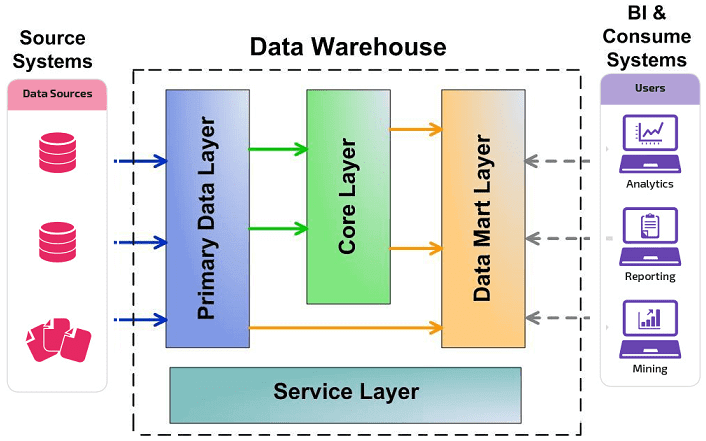
Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами) [3]. Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW) [2].
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД [4] не совсем корректно по следующим причинам:
- разное целевое назначение – DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения [5];
- разные подходы к проектированию. Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями [1]. При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3 [5];
- наконец, цена – обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
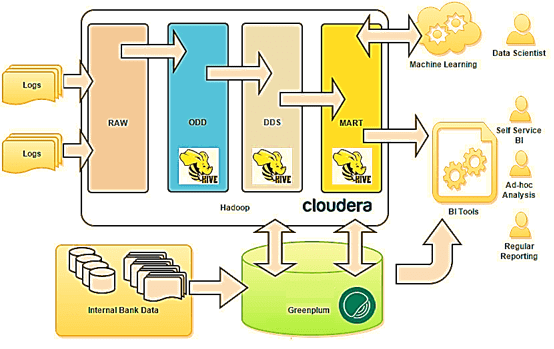
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке [6]:
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- наконец, уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum [6]. От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка [6].
В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Источники

