 700
700 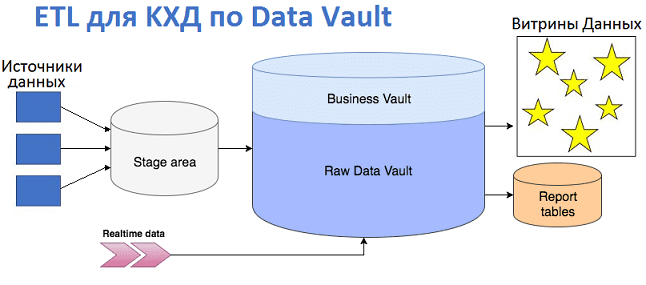
Содержание
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения с помощью технологий Big Data.
Процесс загрузки данных в КХД на базе Data Vault
При том, что Data Vault предлагает оригинальную модель описания сущностей и их взаимосвязей, отличающийся от звездных схем и третьей нормальной формы, он поддерживает типовую LSA-архитектуру КХД. При этом реализуется последовательный подход к загрузке данных в хранилище [1]:
- сперва первичные данные из бизнес-приложений поступают в операционный слой (staging area). Здесь не происходит никакой трансформации: таблицы полностью повторяют исходную структуру, а все ограничения на вставку данных или проверку целостности внешних ключей отключаются. Это делается, чтобы оставить возможность работы с поврежденными или неполными данные. Также здесь выполняется дополнение таблиц метаданными по модели Data Vault: создаются хеши бизнес-ключей, вставляется информация о времени загрузки (load timestamp) и источнике данных (record source).
- Далее данные разбиваются по типам сущностей, принятых в Data Vault: Хабы, Ссылки и Спутники;
- Затем выполняется загрузка в область сырых данных (Raw), при этом не происходит агрегирования и пересчета. Сначала загружаются Хабы, потом Ссылки, а в конце — Спутники. Возможна параллельная загрузка при отсутствии связей link-2-link.
- Наконец, структурированные по модели Data Vault данные попадают в область Business Vault – опциональную вспомогательную надстройку над Raw, где хранятся уже в переработанном виде: агрегированные результаты, сконвертированные валюты и т.д.
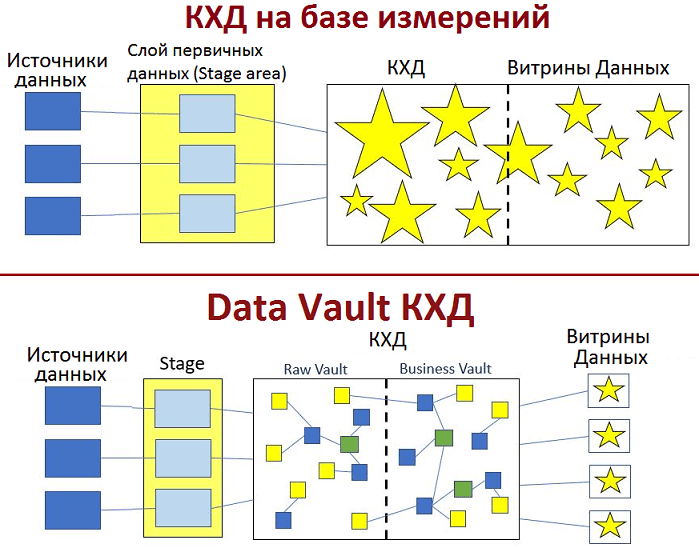
Разделение на Business и Raw Vault лишь логическое, физически обе эти базы находятся в одном месте и необходимо для упрощенного формирования витрин данных (Data Mart). Обычно каждая витрина представлена в виде отдельной СУБД или схемы для решения конкретных бизнес-задач. Поэтому в Data Mart может быть реализована своя «звезда» или «снежинка». По возможности таблицы внутри витрин следует делать виртуальными – вычисляемыми «на лету». Для этого обычно используются SQL-представления (SQL views) [1]. Рекомендуется для каждой таблицы со смысловыми данными иметь свое SQL-представление [2].
Проблемы ETL и инструменты Big Data для их решения
Технически вышеописанная последовательность загрузки данных в КХД реализуется с помощью ETL-систем, например, IBM WebSphere DataStage, Informatica PowerCenter, Oracle Data Integrator, Oracle Warehouse Builder, SAP Data Services, SAS Data Integration Server, Talend Open Studio, Pentaho и др. [3]. Современные ETL-средства позволяют отойти от парадигмы ночной загрузки, когда текущие процессы обработки информации приостанавливаются в пользу централизованной консолидации корпоративных данных из множества источников. Это достигается разделением единого ETL-конвейера на несколько независимых процессов, которые организуют выгрузку данных в КХД небольшими порциями по мере их готовности в исходных системах [2].
Разумеется, Data Vault не является серебряной пулей для организации DWH. В частности, на этапе загрузки данных в КХД возможны следующие проблемы:
- нарушение целостности данных, например, отсутствие записей в нескольких Хабах, выявленное при загрузке таблиц-Ссылок. Решить это можно перезапуском ETL-процесса или отключением механизма предварительной проверки данных, делая проверку данных уже после их загрузки в stage area [1].
- сложности работы в режиме реального времени, когда данные приходят настолько быстро, что ETL-системы не успевают оперативно поместить их в буферную область, очистить и подготовить к загрузке в КХД. Чтобы ускорить этот процесс, при работе в режиме реального времени (near real-time) таблицы-Ссылки и Спутники заполняются почти одновременно с родительскими Хабами [4]. Организовать это помогают принципы массивно-параллельной архитектуры (massive parallel processing, MPP), реализованные в Data Vault 2.0 [5].
Также решить подобные проблемы, характерные для области Big Data, можно с помощью озер данных (Data Lake), интегрированных с КХД. В этом случае готовые ETL-решения дополняются соответствующими технологиями больших данных. Например, чтобы обеспечить стабильный поток данных в Raw-слой корпоративного озера данных на Hadoop, Тинькоф-банк применяет Apache Flume. А далее, чтобы адаптировать эти большие данные к структурам Data Warehouse (DWH), использует ETL-платформу Informatica Big Data Edition, которая позволяет быстро разрабатывать ETL-процедуры (маппинги). Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, а за мониторинг и управление ETL-процессами (запуск, обработка ветвлений и исключительных ситуаций) продолжает отвечать Informatica [6]. Подробнее об этой интеграции КХД c Data Lake на примере Тинькоф-банка мы рассказывали здесь.
В следующей статье мы подведем итог Data Vault подходу, разобрав основные достоинства и недостатки этого способа построения DWH. А практические навыки по организации КХД и Data Lake для эффективного хранения больших данных вы получите на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Источники
- https://habr.com/ru/post/348188/
- https://habr.com/ru/post/281553/
- https://chernobrovov.ru/articles/etl-chto-takoe-zachem-i-dlya-kogo/
- http://www.dwh-club.com/ru/dwh-bi-articles/data-vault-metodika-zagruzki-dannyh/
- https://www.diasoft.ru/gallery/PDF/Data_Vault_2.0_fin.pdf
- https://habr.com/ru/company/tinkoff/blog/259173/

