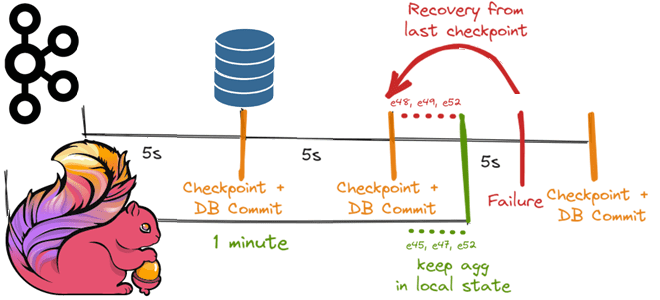
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...
Мы уже писали про поиск сложных событий при их потоковой обработке средствами Apache Flink. Продолжая эту важную для обучения дата-инженеров тему, сегодня рассмотрим, как CDC-коннектор от GetIndata упрощает запуск распознавание шаблонов на потоках данных из многих источников. Проблемы захвата измененных данных из реляционной базы с помощью JDBC-драйвера и способы их...
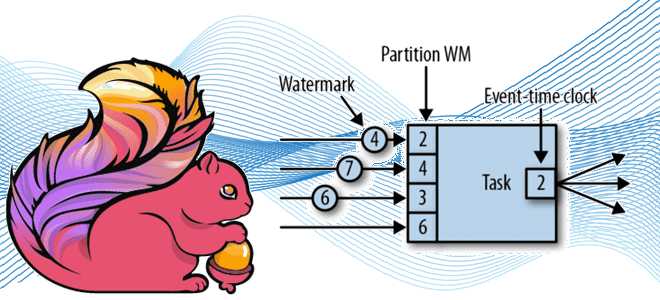
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера. Потоковая синхронизация данных c SQL для Flink...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...
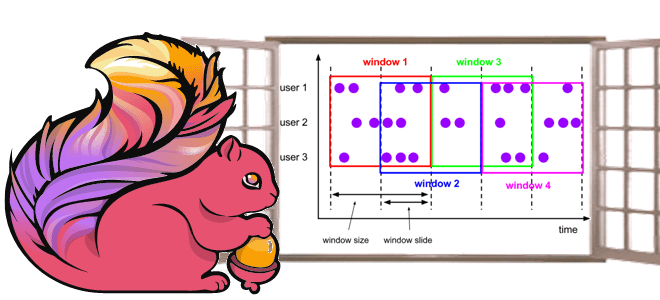
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
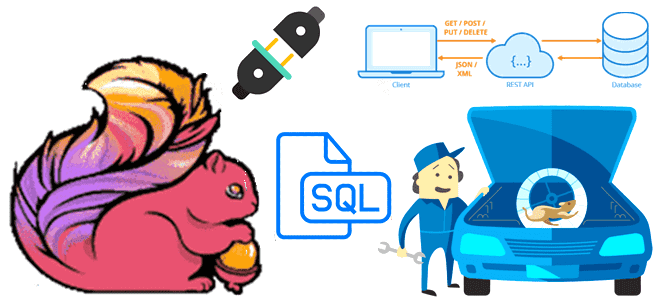
Недавно мы писали про HTTP-коннектор к Apache Flink от компании GetInData, который позволяет обогатить ML-модель данными из внешней системы с использованием REST API и SQL-концепции Lookup Joins. Как устроен этот коннектор с открытым исходным кодом, и какие методы Flink SQL он использует: разбираем на практическом примере. Что такое HATEOAS: блеск...
В этой статье для обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как Flink SQL может обогатить ML-модель данными из внешней системы в режиме реального времени с использованием REST API. Что представляет собой http-flink-connector с открытым исходным кодом, разработанный GetInData на основе концепции Lookup Joins. Обогащение данных c SQL: достоинства использования...

Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...