Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API.
Трудности строго однократной доставки в потоковой обработке данных
Распределенная обработка потоков с отслеживанием состояния и восстановлением после сбоев является довольно сложной задачей. Такая система потоковой обработки должна гарантировать, что каждая запись обрабатывается один раз и только один раз, даже если в середине обработки возникнут какие-то сбои. Это соответствует семантике строго-однократной доставке сообщений (exactly once), когда каждое входящее событие влияет на окончательные результаты только один раз. При этом даже в случае аппаратного или программного сбоя нет дублирующихся данных или тех, которые остались необработанными. Apache Flink поддерживает эту семантику, генерируя контрольные точки с регулярным настраиваемым интервалом, а затем записывает их в постоянную систему хранения с прикрепленной позицией во входном потоке. Во время восстановления после сбоя Flink-приложение возобновляет обработку с последней успешно завершенной контрольной точки, используя метод, представленный в 1985 году Чанди и Лэмпортом для создания согласованных моментальных снимков текущего состояния распределенной системы без пропуска информации и без записи дубликатов.
Однако, сквозной конвейер потоковой обработки предполагает, что Flink отправляет обработанные данные далее. Например, процесс потребляет события из топика Kafka, выполняет анализ в рамках кувыркающегося окна раз в 1 минуту и по истечении этого периода записывает все события в базу данных. Таким образом, события группируются в сегменты и записываются одной операцией массовой вставки. Желательно, чтобы все входящие события в конечном итоге появились в базе данных, но только один раз.
Если Flink-приложение записывает записи со связанными согласованными уникальными идентификаторами, строго однократной доставки можно добиться с помощью идемпотентной реализации записи в базу. Это означает указание БД просто игнорировать или переопределять дублирование, чтобы даже в случае повторной обработки одних и тех же событий не было реального воздействия на внешнюю таблицу. Возвращаясь к примеру рассматриваемого приложения, которое записывает необработанные события в базу раз в минуту, каждое событие имеет связанный идентификатор, что подойдет в качестве первичного ключа таблицы. Если контрольная точка Apache Flink запускается каждые 5 секунд, между двумя контрольными точками может произойти сбой. В этом случае Flink восстановится с последней контрольной точки и переиграет оттуда. На самом деле, все сообщения из последней контрольной точки будут повторно обработаны и отправлены в базу, но будут проигнорированы, поскольку это является попыткой записи одного и того же идентификатора события дважды.
По сути, это соответствует паттерну обработки событий без сохранения состояния, для которого применение Flink может быть излишним. Но сложный механизм контрольных точек Flink полезен для состояний, распределенных по нескольким узлам. Поэтому эти состояния следует сохранить, что можно просто реализовать с помощью собственных API-интерфейсов Apache Kafka для потребителей и производителей, а также группировать события, записывать их и фиксировать средствами этой распределенной системы потоковой обработки событий. Однако, в случае тайм-аута или повторной попытки потребителя одно и то же сообщение будет обработано повторно, но без реального воздействия.
Если же приложение находится в цикле потребления и производства из входящих и исходящих топиков, создание сообщений через Kafka Transaction API будет отличным выбором для потребления, обработки и создания сообщения с помощью атомарной операции. При этом важно, что любой нижестоящий потребитель Kafka, опрашивающий исходящий топик, получит эти результирующие сообщения только один раз. Это гарантирует отсутствие дубликатов, даже если приемнику данных потребуется повторить попытку создания сообщения. Сценарии сбоев могут означать, что исходное сообщение потребляется и обрабатывается несколько раз, но это никогда не приведет к дублированию данных, т.е. публикации повторяющихся исходящих событий.
Чтобы использовать этот метод, все эти три оператора (источник, окно и приемник) должны выполняться на одном компоненте, чтобы создание любого исходящего сообщения было окружено одной и той же транзакцией, которая фиксирует смещение потребителя следующим образом:
- сервис вызывает метод beginTransaction() для инициирования новой транзакции;
- сервис публикует сообщения продюсера;
- смещения потребителей также отправляются продюсеру для включения в ту же транзакцию;
- сервис вызывает метод commitTransaction() для завершения транзакции.
Для поддержки создания транзакций Kafka использует координатор потребителей, координатор и журнал транзакций. Но это не исключает ситуаций, когда исходное сообщение доставляется повторно. Например, если приложение выполняет вызовы REST к другим приложениям или выполняет запись в базу данных. Гарантия exactly once в том, что результирующие события обработки будут записаны только один раз. Для этого существует двухфазная фиксация, которую мы рассмотрим далее.
Двухфазная фиксация
Чтобы понять, как работает двухфазная фиксация, рассмотрим пример приложения, которое использует Kafka, выполняя некоторую агрегацию, а затем записывает результаты во внешнюю базу данных. Как правило, реализовать идемпотентность, когда любое повторное выполнение операции дает те же результаты, что и при первом разе, довольно сложно. Трудность обусловлена тем, что значения агрегации могут быть изменены, но они не могут реально извлечь выгоду из транзакции Kafka, которая не привязана к транзакции базы данных.
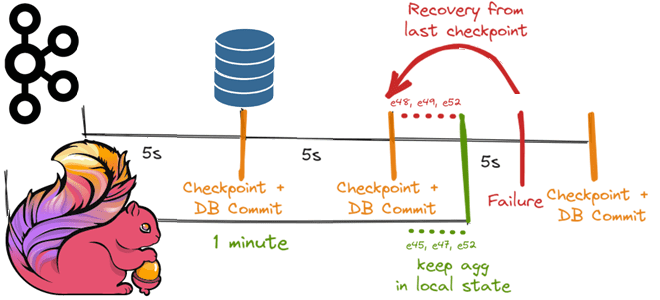
Предположим, вместо записи необработанных событий подсчитывается количество событий, произошедших в течение 1-минутного окна, и это агрегированное значение записывается в базу данных. В топике Kafka есть несколько разделов и несколько экземпляров операторов источника, окна и приемника данных, работающих параллельно. Если не требуется никакого партиционирования по ключу (keyBy) или логического разделения, нужно просто подсчитывать события с мельчайшей детализацией. Чтобы добиться идемпотентной записи, следует знать ее идентификатор в таблице агрегации. Определить его как <Sink Instance ID, minute> проблематично, поскольку нет гарантии, что одни и те же события будут отправлены тем же экземплярам оператора после восстановления. К примеру, конкретный экземпляр оператора приемника изначально обрабатывает события e45, e47 и e52, но после восстановления из последней контрольной точки он получит события e48, e49 и e50, поскольку теперь они придут из окна, отличающиеся от вышестоящего оконного оператора.
Чтобы координировать запись во внешнюю систему со своим внутренним механизмом контрольных точек, в Apache Flink есть функция TwoPhasedCommitSink(). Внешние системы должны предоставлять средства для фиксации или отката записей, чтобы эти события можно было запускать и координировать с управлением контрольными точками Flink. Одним из распространенных подходов к координации фиксации и отката в распределенной системе является протокол двухфазной фиксации. Приемник с двухфазной фиксацией должен реализовать четыре разных метода, которые Flink будет вызывать на разных этапах процесса создания контрольных точек:
- beginTransaction() — транзакция объединяет все операции записи между двумя контрольными точками, поэтому операции записи всегда находятся в пределах области действия транзакции. Эта функция вызывается в начале новой контрольной точки. Здесь можно открыть транзакцию базы данных, если она поддерживает это, или создать временный файл в файловой системе. Вся последующая обработка событий будет использовать его до следующей контрольной точки.
- preCommit() — предварительная фиксация вызывается приемником, как только он получает барьер контрольной точки после успешного сохранения своего внутреннего состояния. Это будет вызываться каждым приемником, чтобы менеджер заданий Flink (координатор) мог зафиксировать контрольную точку только после того, как все приемники успешно выполнят предварительную фиксацию. Здесь можно сбросить файл, закрыть его и больше никогда не писать в него новых записей. Или запустить новую транзакцию базы данных для любых последующих записей, относящихся к следующей контрольной точке.
- Commit() — фиксация будет вызываться каждым приемником только после того, как менеджер заданий Flink уведомит их о завершении контрольной точки. На этом этапе можно атомарно переместить предварительно зафиксированный файл в фактический каталог назначения или зафиксировать транзакцию базы данных.
- Abort() – функция прерывания будет вызываться, когда распределенная контрольная точка была прервана или при прерывании транзакции, которая была отклонена координатором после сбоя. Здесь, например, можно удалить временный файл или прервать транзакцию базы данных.
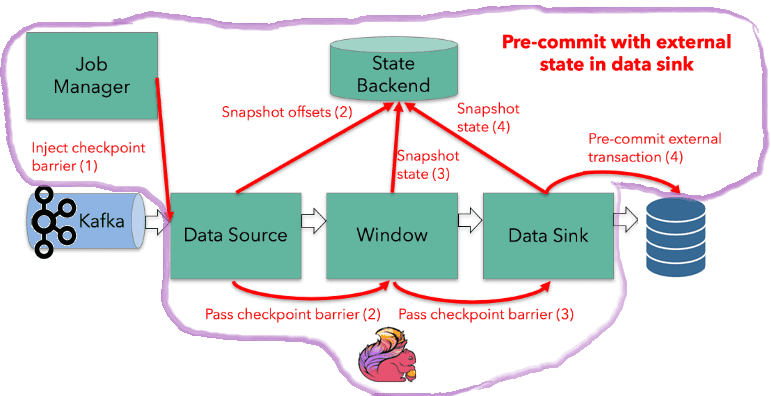
Эта реализация приемника изначально работает с базой данных, которая поддерживает транзакции. Но даже когда приемник записывает агрегации в базу данных временных рядов, например, AWS AppStream, возможна пользовательская реализация функции TwoPhasedCommit(), а фактическая запись в базу данных должна быть отложена до фазы фиксации.
После успешной предварительной фиксации сама фиксация должна успешной. Для этого Flink-операторы и внешняя система, т.е. база данных, должны предоставить такую гарантию. Если фиксация завершается неудачно, например, из-за периодически возникающей проблемы с сетью, во Flink-приложении возникнет сбой, и оно перезапустится согласно заданной стратегии перезапуска, предприняв еще одну попытку фиксации. Если же фиксация в конечном итоге не будет успешной, произойдет потеря данных.
Таким образом, все операторы транзакционно согласованы с окончательным результатом контрольной точки: данные либо фиксируются, либо фиксация прерывается и выполняется откат. Это позволяет добиться того, что фактическая запись базы данных выполняется в одной и той же транзакции постоянной контрольной точки и потребительского смещения. Как использовать эти и другие советы на практике при оптимизации Flink-приложений, читайте в нашей новой статье.
Освойте тонкости использования Apache Flink, Kafka и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Потоковая обработка в Apache Spark
- Apache Kafka для инженеров данных
Источники