 902
902 
Недавно мы писали про HTTP-коннектор к Apache Flink от компании GetInData, который позволяет обогатить ML-модель данными из внешней системы с использованием REST API и SQL-концепции Lookup Joins. Как устроен этот коннектор с открытым исходным кодом, и какие методы Flink SQL он использует: разбираем на практическом примере.
Что такое HATEOAS: блеск и нищета REST API
Напомним, компания GetInData разработала HTTP-коннектор, чтобы использовать Flink SQL для доступа к данным во внешних системах в режиме реального времени с помощью REST API. Этот коннектор позволяет извлекать данные из внешней системы с помощью HTTP-запросов GET и методов приемника (Sink), чтобы применять его в операторе Flink SQL в качестве стандартной таблицы, чтобы соединить ее с другим потоком через SQL-запрос. Flink предоставляет ANS-совместимый SQL API, который любой аналитик может применять для определения конвейеров обработки данных, определения источников, приемников и функций преобразования данных, включая распознавание образов. Подробнее о таком сценарии использования мы рассказывали здесь.
Чтобы понять, как лучше использовать этот коннектор, разберемся, как он работает: внутри много нетривиальных решений. В частности, разработчики из GetInData не стали использовать новый унифицированный интерфейс источника Flink, представленный в версии 1.12 и включающий функцию обнаружения работы (work discovery), которая описывает логику для включения новых данных в поток. Например, топик Apache Kafka или обнаружение разделов во время выполнения. Это также может быть активный мониторинг исходной папки для источника файлов, активный опрос сервера электронной почты или корпоративного мессенджера Slack на предмет новых сообщений для обработки. В официальной документации именно этот API рекомендуется для реализации пользовательских коннекторов. Но на практике оказалось, что для рассматриваемого случая он не подходит.
В отличие от JDBC-коннектора, подключаемого к базе данных напрямую, веб-сервисы довольно редко имеют конечную точку REST API, которая возвращает полный набор данных, если он не имеет управляемого размера. Речь идет о так называемой пагинации — постраничном выводе с показом ограниченной части информации на одном экране с «пролистыванием» между страницами. В частности, для REST API характерно ограничение HATEOAS (Hypermedia As The Engine Of Application State), связанное с полной возможностью обнаружения действий/переходов на ресурсе из гипермедиа (фактически гипертекста) как единственного драйвера состояния приложения. Если взаимодействие должно управляться API через гипертекст, документация об этом отсутствует, что заставляет клиента делать предположения, которые на самом деле находятся вне контекста API. А сервер должен инструктировать клиента, как использовать API только через гипертекст. В случае HTTP-взаимодействия добиться этого можно с помощью заголовка Link, который также помогает обнаружить все возможные URI, не переходя к более богатой семантической разметке, такой как определение пользовательских отношений ссылок, протокол публикации Atom или микроформаты. Например, клиент должен иметь возможность обнаружить URI для создания новых ресурсов при выполнении GET-запроса для определенного ресурса. Сегодня для этого чаще всего практикуется, что URI для создания совпадает с URI для GET-запросов всех ресурсов этого типа, с той лишь разницей, что используется HTTP-метод POST.
Обычно REST API полностью обнаруживается из корня и без каких-либо предварительных знаний, т.е. клиент может перемещаться по нему, выполняя GET-запрос в корне. В дальнейшем все изменения состояния управляются клиентом с использованием доступных и обнаруживаемых переходов, которые REST API предоставляет в представлениях, согласно своему названию (передача репрезентативного состояния, Representational State Transfer). В этом случае обычной практикой является возврат данных на пронумерованных страницах в соответствии с шаблоном ответа HATEOAS. HATEOAS расшифровывается как Hypermedia As The Engine Of Application State, и в случае нумерации страниц это реализуется путем предоставления ссылок на предыдущую и следующую страницы. Эти ссылки добавляются в ответ API.
Таким образом, HATEOAS — это ограничение архитектуры RESTful-приложения, которое позволяет использовать ссылки гипермедиа в содержимом ответа API, чтобы клиент мог динамически переходить к соответствующим ресурсам, проходя гипермедиа-ссылки. Навигация по гипермедиа-ссылкам концептуально аналогична просмотру веб-страниц путем нажатия соответствующих гиперссылок для достижения конечной цели. Например, приведенный ниже ответ JSON может быть получен от такого API, как HTTP GET http://api.domain.com/management/departments/10:
{
"departmentId": 10,
"departmentName": "Administration",
"locationId": 1700,
"managerId": 200,
"links": [
{
"href": "10/employees",
"rel": "employees",
"type" : "GET"
}
]
}
В этом примере ответ, возвращенный сервером, содержит гипермедиа-ссылки на ресурсы сотрудников 10/employees, по которым клиент может пройти, чтобы прочитать сотрудников в отделе номер 10. Преимущество этого подхода в том, что гипермедиа-ссылки, возвращаемые с сервера, управляют состоянием приложения, а не наоборот. JSON не имеет общепринятого формата для представления ссылок между двумя ресурсами. Можно выбрать отправку в теле ответа или отправлять ссылки в заголовках ответа HTTP:
HTTP/1.1 200 OK ... Link: <10/employees>; rel="employees"
На практике этот самый распространенный паттерн HATEOAS просто использует фильтрацию с помощью HTTP-запроса GET с параметрами. Например, используется идентификатор, по которому должны быть получены данные. В случае обогащения данных ML-модели средствами Apache Flink параметры, используемые в SQL-запросе с JOIN, и являются таким идентификатором. На первый взгляд, передача параметров соединения в коннектор может быть выполнена с помощью концепции Flink под названием Lookup Join. Однако, в реальности все оказалось не так просто. С какими ограничениями Flink SQL столкнулись разработчики GetInData и как решили эти проблемы, мы рассмотрим далее.
Реализация коннектора Flink SQL
Оказалось, что Lookup Join, а точнее LookupTableSource, не может быть реализован с помощью унифицированого API источника Flink. Source-коннектор, реализованный с использованием унифицированного интерфейса источника, действует только как источник сканирования. Это означает, что он будет сканировать все строки из внешней системы хранения во время выполнения, требуя исходной таблицы поиска, которой пока нет. Из-за отсутствия этого в Apache Flink SQL разработчики GetInData не могли реализовать свой коннектор с помощью унифицированного API источника, поскольку он поддерживает только источники сканирования, которые плохо сочетаются с REST API.
В ядре коннектора GetInData есть два основных класса: HttpTableLookupFunction и AsyncHttpTableLookupFunction, которые обеспечивают связь между Flink Runtime и пользовательским кодом, выполняющим HTTP-вызовы. Коннектор может работать асинхронно.
Оба класса для взаимодействия с Flink Core должны реализовать общедоступный метод void eval(…), который не является частью какого-либо интерфейса или абстрактного метода, что упоминается в официальной документации Javadoc для абстрактных классов TableFunction и AsyncTableFunction.
Чтобы зарегистрировать новый источник в качестве источника таблицы, нужно добавить фабричный класс и зарегистрировать его для интерфейсов поставщика услуг Java. Для GetInData это был класс HttpLookupTableSourceFactory, который должен реализовать интерфейс DynamicTableFactory. Чтобы Flink мог его обнаружить, этот класс должен быть добавлен в файл src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory. HttpLookupTableSourceFactory создает экземпляр DynamicTableSource, которым является HttpLookupTableSource.
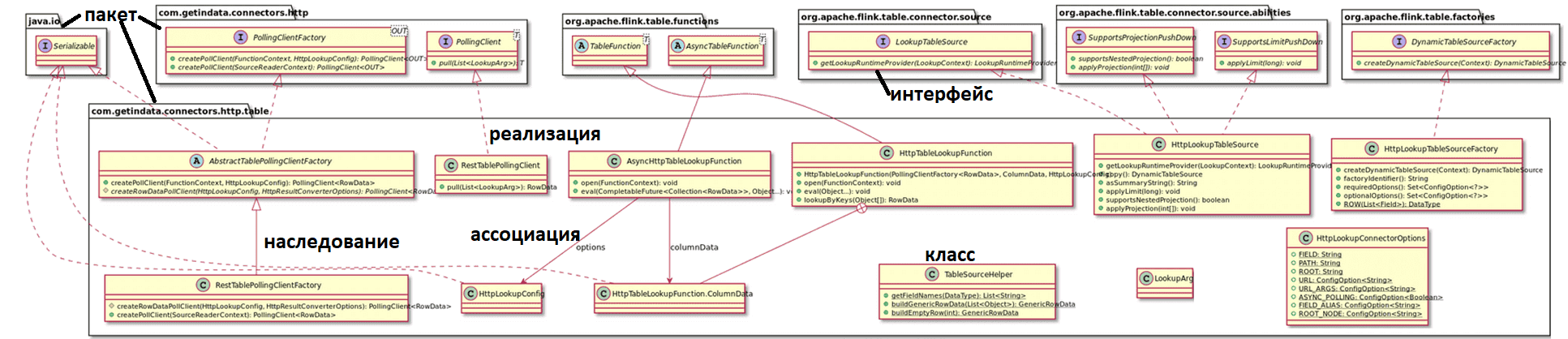
Метод getLookupRuntimeProvider() будет вызываться ядром Flink, чтобы получить реализацию Lookup-функции. Для реализации этого можно использовать LookupRuntimeProvider или ScanRuntimeProvider. Провайдер LookupRuntimeProvider дополнительно расширяется с помощью TableFunctionProvider и AsyncTableFunctionProvider, в зависимости от asyncPolling-параметра конфигурации коннектора.
Рассматриваемый http-коннектор к Flink SQL использует HTTP-клиент Java 11 для отправки HTTP-запросов, который предоставляет комплексный механизм, необходимый для связи с HTTP-сервером, и уже реализован в JDK, поэтому дополнительные зависимости не требуются. Однако, для построения пути URI был использован класс URIBuilder из сторонней библиотеки org.apache.httpcomponents, чтобы не разрабатывать логику создания всех вариантов HTTP URI, обработки нескольких параметров запроса и пр.
Как и в большинстве случаев с REST API, HTTP-ответ отправляется в виде JSON-объекта, формат которого поддерживается Flink для определения источников SQL. Пока коннектор GetInData поддерживает только столбцы типа String, а поддержка формата Flink JSON будет добавлена в будущем.
Созданный GetInData альтернативный механизм сопоставления основан на библиотеке com.jayway.jsonpath и нотации JSONPath — языкf запросов для JSON, похожtuj на XPath для XML. Как и XPath, JSONPath позволяет извлекать данные из структуры JSON и фильтровать их, чтобы преобразовать JSON в табличную структуру, а также оформить правила отображения из необработанного формата в общую модель. В HTTP-коннекторе для Apache Flink SQL преобразование из JSON в RowData выполняется классом HttpResultConverter, который использует определение коннектора для поиска определений псевдонимов или определения корневого узла. Если ничего не найдено, имя столбца сопоставляется непосредственно с форматом пути JSON. Для сложных структур пользователь может определить псевдонимы путей согласно шаблону field.COLUMN_NAME.path. Значением ключа пути псевдонима является строка пути JSON. HttpResultConverter или каждый столбец проверяет наличие псевдонима. Если есть, он использует соответствующее определение пути JSON для получения значения из ответа HTTP.
Например, в следующем DDL-запросе каждый столбец, кроме isActive и balance, будет преобразован непосредственно в путь JSON: id в $.id, а оставшиеся два столбца будут использовать псевдонимы путей из определения таблицы. Это значит, что значение для столбца isActive будет взято из пути $.details.isActive, а значение для столбца баланса будет взято из $.details.nestedDetails.balance path:
CREATE TABLE Customers ( id STRING, id2 STRING, msg STRING, uuid STRING, isActive STRING, balance STRING ) WITH ( 'connector' = 'rest-lookup', 'url' = 'http://localhost:8080/client', 'field.isActive.path' = '$.details.isActive', 'field.balance.path' = '$.details.nestedDetails.balance' )
При реализации функции процесса, взаимодействующей с внешней системой с помощью блокирующих вызовов, рекомендуется использовать асинхронный ввод/вывод Flink. Это помогает управлять задержкой связи с внешней системой и не влияет на общую работу приложения потоковой передачи. В частности, в процессе обогащения необходима именно такая асинхронная поддержка. Такой асинхронный ввод-вывод также поддерживается в Flink SQL. Поэтому нужно просто вернуть AsyncTableFunctionProvider из HttpLookupTableSource::getLookupRuntimeProvider. А AsyncTableFunctionProvider должен предоставить объект, расширяющий абстрактный класс AsyncTableFunction, т.е. класс AsyncHttpTableLookupFunction. Абстрактный класс AsyncTableFunction очень похож на TableFunction, с разницей в сигнатуре метода eval, который нужно реализовать. В классе AsyncTableFunction сигнатура метода eval принимает ключи соединения и объект CompletableFuture: public void eval(CompletableFuture<Collection<RowData>> resultFuture, Object… keys). Реализация GetInData метода eval основана на HBaseAsyncTableFunction, который приведен в качестве примера AsyncTableFunction в официальной документации Javadoc:
public void eval(CompletableFuture<Collection<RowData>> resultFuture, Object... keys) {
CompletableFuture<RowData> future = new CompletableFuture<>();
future.completeAsync(() -> decorate.lookupByKeys(keys), pollingThreadPool);
future.whenCompleteAsync(
(result, throwable) -> {
if (throwable != null) {
log.error("Exception while processing Http Async request", throwable);
resultFuture.completeExceptionally(
new RuntimeException("Exception while processing Http Async request", throwable));
} else {
resultFuture.complete(Collections.singleton(result));
}
},
publishingThreadPool);
}
Здесь использовано два отдельных пула потоков: один нужен для HTTP-клиента для выполнения HTTP-запроса, а второй используется для публикации результатов далее по потоковому конвейеру через CompletableFuture resultFuture. Наличие отдельных пулов потоков помогает избежать простоя потоков при публикации результатов.
Узнайте больше про использование возможностей Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

