
Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...
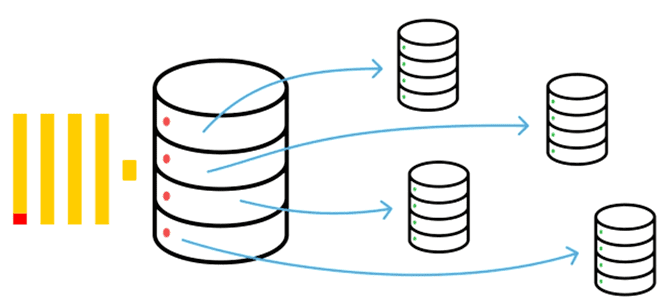
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
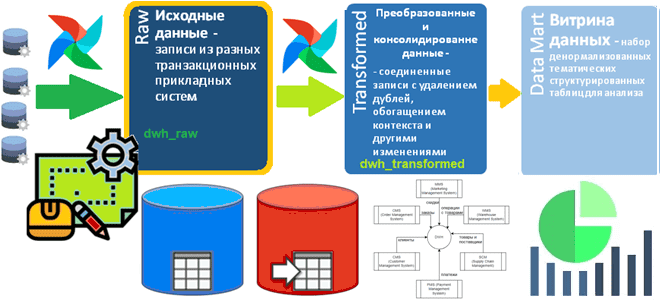
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
Одной из причин быстрой работы ClickHouse являются движки таблиц, оптимизированные на конкретные операции с данными. Сегодня рассмотрим, чем они отличаются и какой из них выбирать для разных сценариев. Движки БД ClickHouse Прежде чем разбираться с движками таблиц ClickHouse, вспомним само назначение этого термина. Движок БД или механизм хранения отвечает за...
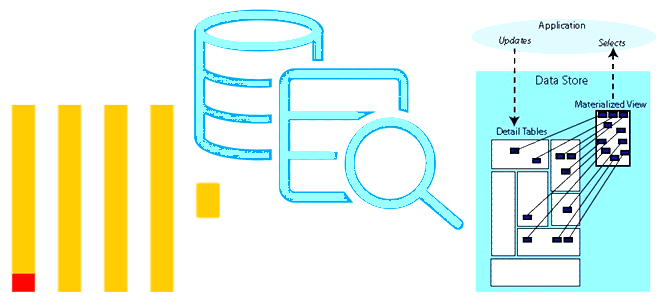
Чем материализованное представление в ClickHouse отличается от обычного, зачем нужны LIVE-представления и как их использовать. Примеры SQL-запросов с VIEW для самой популярной колоночной аналитической СУБД. Представления vs словари в ClickHouse Поскольку ClickHouse, как типовая колоночная СУБД, используется для аналитической обработки огромных объемов данных в реальном времени, вопрос ускорения вычислений для...
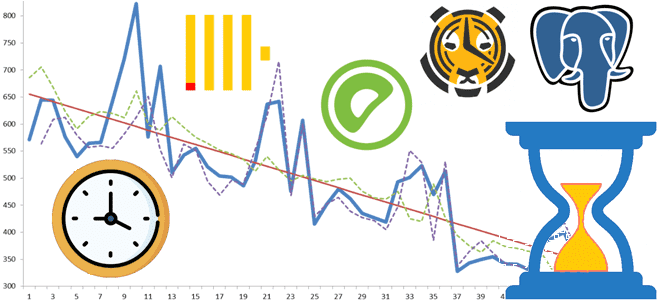
Анализ временных рядов нужен не только в Data Science, но и в мониторинге системных событий. Чем столбец с отметками времени в ClickHouse отличается от гипертаблиц в PostgreSQL и Greenplum c расширением TimescaleDB, и что выбирать для аналитики больших данных. ClickHouse для анализа временных рядов ClickHouse является колоночной СУБД для аналитической...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...

Насколько быстро ClickHouse выполняет SQL-запросы: тестирование СУБД в открытой онлайн-песочнице. Примеры запросов и время их выполнения. Работа с онлайн-песочницей Clickhouse: выполнение SQL-запросов Будучи реляционной аналитической СУБД, ClickHouse позволяет обрабатывать гигабайты данных в реальном времени. Архитектурные особенности, благодаря которым реализуется такая скорость, мы недавно разбирали здесь. Чтобы оценить это на практике,...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....

Сегодня рассмотрим основные преимущества и недостатки ELK-стека. Читайте в этой статье, чем хороши Elasticsearch с Logsatsh и Kibana, а также каковы их основные недостатки и ограничения для использования в реальных Big Data проектах. Также мы собрали для вас несколько практических примеров, где и как используется Elasticsearch в интернет-магазинах, банках и...

Вчера мы разобрали, чем хорош ClickHouse и почему. Сегодня рассмотрим обратную сторону скорости, расширяемости и других преимуществ этой аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Также читайте в нашей статье, как обойти недостатки и ограничения этой системы или понизить степень их влияния на...

Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data. Чем хорош ClickHouse: главные преимущества Напомним, основным...

Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную...

Вчера мы рассматривали интеграцию ClickHouse с Apache Kafka с помощью встроенного движка. Сегодня поговорим про проблемы, которые могут возникнуть при его практическом использовании и разберем способы их решения для корректной связи этих Big Data систем. Почему случаются тайм-ауты: многопоточность и безопасность Напомним, интеграцию ClickHouse и Kafka обеспечивает встроенный движок (engine),...