
Если Postgres - это надежный банковский сейф, где каждая транзакция на вес золота, то ClickHouse - это промышленная мясорубка. Ему все равно, уникальны ли ваши записи (по умолчанию), он не поддерживает классические транзакции, но зато он умеет делать SELECT count(*) FROM hits по миллиарду строк за доли секунды. Для...

Установка Claude Code на Ubuntu 24.04 — процесс довольно прямолинейный, но требующий аккуратности с версиями Node.js и правами доступа. Как «самоучка», я рекомендую использовать официальный скрипт установки или NPM, но без использования sudo для самого пакета, чтобы избежать проблем с правами в будущем. Claude Code - это специализированный CLI-инструмент от...

Поздравляем! Если вы читаете эти строки, значит, вы прошли полный путь от первого изучения ClickHouse до понимания его самых глубоких механизмов. За эти десять статей мы превратились из новичков, задающихся вопросом "Что такое колоночная СУБД?", в уверенных пользователей, способных не только писать сложные аналитические запросы, но и проектировать, оптимизировать и...

Мы с вами научились виртуозно писать запросы, строить сложные аналитические отчеты и интегрировать ClickHouse с другими системами. Но чтобы вся эта мощь работала стабильно и предсказуемо в production, кластер требует внимания и ухода. Написание запросов — это работа аналитика или разработчика, а поддержание здоровья системы — это задача администратора баз...
Оконные функции ClickHouse и работа с массивами данных. Мы с вами уже прошли большой путь: научились эффективно хранить данные, оптимизировать таблицы, выполнять базовые и сложные запросы и даже интегрироваться с внешними системами. Казалось бы, мы можем практически всё. Но как ответить на такие вопросы: "Каково время между последовательными действиями каждого...
До сих пор мы рассматривали ClickHouse как самостоятельную систему: создавали в нем таблицы и загружали данные. Однако в реальном мире данные редко живут в одном месте. Транзакционная информация находится в реляционных базах вроде MySQL или PostgreSQL, архивы логов — в объектных хранилищах типа Amazon S3, а потоки событий в реальном...
Итак, вы освоили типы данных, создали таблицы на правильных движках MergeTreeи даже научились писать сложные запросы. Кажется, что вы готовы к работе с реальными данными. Однако на больших объемах вы можете столкнуться с ситуацией, когда даже на мощном "железе" запрос выполняется не так быстро, как хотелось бы. В чем же...
В предыдущих статьях мы узнали, что семейство движков MergeTree — это основа для хранения аналитических данных в ClickHouse. Мы создавали таблицы с помощью базового MergeTree и даже упоминали о его специализированных версиях. Теперь пришло время для глубокого погружения. Эти движки — не просто вариации, а мощные инструменты, которые выполняют часть...
Добро пожаловать в четвертую статью нашего курса по ClickHouse! В прошлый раз мы научились основам: вставлять, выбирать и агрегировать данные. Теперь, когда вы можете получать базовую статистику, пришло время углубить свои навыки и научиться "разговаривать" с данными на более сложном языке. Сегодня мы изучим мощные инструменты, которые позволят вам преобразовывать,...
Приветствуем вас в третьей части нашего гида по ClickHouse! В предыдущих статьях мы заложили прочный фундамент: разобрались, что такое ClickHouse (далее CH), почему он так хорош для аналитики, а также глубоко погрузились в типы данных и движки таблиц, научившись создавать оптимизированные таблицы. Теперь пришло время перейти от теории к самой...
Приветствуем вас во второй части нашего курса по основам ClickHouse (далее CH)! В первой статье мы разобрались, что такое ClickHouse, почему он так хорош для аналитики и как запустить его локально или в облаке. Теперь пришло время углубиться в две ключевые концепции, которые определяют, как CH хранит и обрабатывает ваши...
Данной статьей мы начинаем Бесплатный курс по "Основам ClickHouse для аналитиков и дата инженеров", который будет состоять из 10 уроков с практическими занятиями код которых будет доступен для скачивания на нашем GitHub аккаунте. Если ваша работа связана с данными, вы наверняка слышали название ClickHouse. Это не просто очередная база данных,...

Как оптимизировать многопоточную обработку в ClickHouse и эффективно распределить ресурсы ЦП между разными пользователями и запросами, спланировав рабочую нагрузку. Настройка многопоточной обработки в Clickhouse Чтобы эффективно утилизировать ресурсы для аналитической обработки огромных объемов данных, в ClickHouse можно спланировать рабочую нагрузку, определив приоритеты использования памяти, диска и ЦП для разных видов...
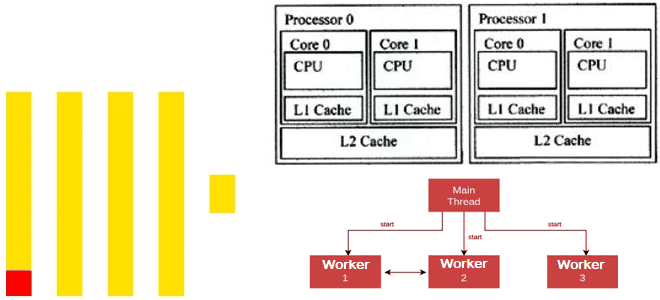
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....
Как эффективно распределять ресурсы ClickHouse между разными пользователями и запросами, настроив политику планирования рабочих нагрузок: примеры и рекомендации. Иерархия планирования рабочей нагрузки в Clickhouse Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски, ЦП и память. Чтобы эффективно распределять ресурсы ClickHouse между разными пользователями и нагрузками,...
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
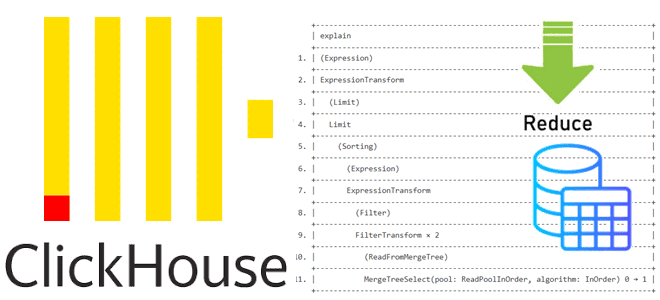
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов. Как устроена оптимизация PREWHERE в ClickHouse Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора...
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации. Как работает оператор PREWHERE в ClickHouse ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...