
Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...
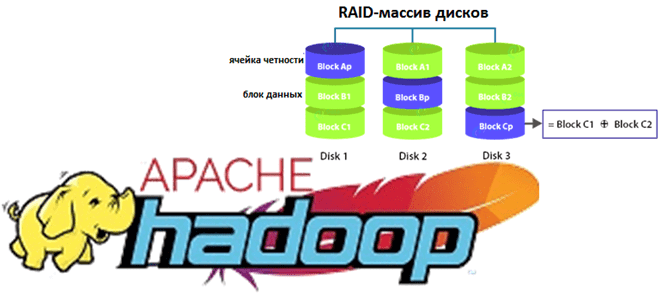
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...
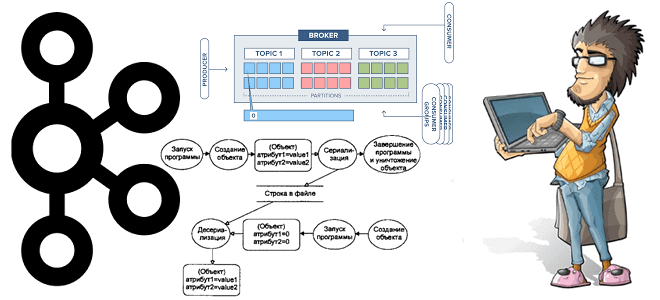
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...